注册深圳公司seo设置是什么
论文:https://arxiv.org/pdf/2203.15556.pdf
发表:2022

前文回顾:
OpenAI在2020年提出《Scaling Laws for Neural Language Models》:Scaling Laws(缩放法则)也一直影响了后续大模型的训练。其给出的结论是最佳计算效率训练涉及在相对适中的数据量上训练非常大的模型并在收敛之前early stopping。所以后续的工作都专注于提升参数规模,设计越来越大的模型,而不是在更多的数据上训练较小的模型。每个人都认为模型大小比数据大小重要的多得多!但DeepMind在2022年提出了不同的看法。
摘要

1:目前的LLM大模型训练都不够充分,原因是:大部分精力主要花费在扩大模型尺寸上,训练数据却没有同步增长。(这个主要是受OpenAI论文观点的影响)
2:DeepMind团队发现:最优的训练是模型尺寸和训练的Token数量应该是等比例增长。如果模型尺寸翻倍,token数量也应该翻倍。
简介

DeepMind得到了与OpenAI相同的结论:大模型在训练到loss最低前已经到算力最优了,即在收敛前进行early stopping。尽管得出了同样的结论,但DeepMind认为:大型模型应训练更多的token,远超过OPenAI作者推荐的数量。具体来说,给定计算预算增加10倍,OpenAI建议模型大小应增加5.5倍,而训练token数量只应增加1.8倍。相反,DeepMind认为模型大小和训练令牌数量应该以相同的比例增长。
相关工作

OpenAI首先观测到了scale law法则,DeepMind也采用了相同的技术手段:训练不同尺寸的模型,然后进行观测。但他们存在以下不同点。
1:OpenAI固定了训练的token数目以及学习率方案,这阻止了他们研究这些超参数对损失的影响。相反,DeepMind发现将学习率调度设置为大约匹配训练token数量可以导致最好的最终损失,无论模型大小如何。作者举例:130B token,使用cosine学习率。因为会在收敛前进行早停,所以观测到的都是中间状态(即训练token数量还没有到130B token 时候的loss),使用这些中间损失观测,导致对训练模型在小于130B token的数据上的有效性的低估,并最终导致了一个结论,即模型大小应比训练数据大小增长得更快。DeepMind的观点是同比例缩放。
2:OpenAI使用的模型参数量比较小,DeepMind观测的范围更广。
3 估计最优的参数 / 训练token数目
 首先训练一系列模型:模型大小和训练数据数量两方面都有所不同,然后使用所得到的训练曲线来拟合他们应该满足的经验规律。
首先训练一系列模型:模型大小和训练数据数量两方面都有所不同,然后使用所得到的训练曲线来拟合他们应该满足的经验规律。

训练70M到10B的一系列模型大小,每个模型大小针对四个不同的余弦周期长度进行训练。从这些曲线中,提取了每FLOP最小损失的包络,并用这些点来估计给定计算量条件下最优模型大小以及最优训练token数。(此处的scale law 实践与OpenAI一致)。从上图不难看出:模型越大,需要的算力越大,需要的token也越多。
左图可以看到计算量与模型性能呈现幂律关系(可以认为数据和模型都不受限制),根据中图和右图,可以发现,
,即计算效率最优时,模型的参数与计算量的幂次成线性关系,数据量的大小也与计算量的幂次成线性关系。
根据C=6ND,可以推算出a+b=1,但是a,b分别是多少存在分歧。
OpenAI:认为模型规模更重要,即a=0.73, b=0.27,
DeepMind在Chinchilla工作和Google在PaLM工作中都验证了 a=b=0.5 ,即模型和数据同等重要。
所以假定计算量整体放大10倍,OpenAI认为模型参数更重要,模型应放大 (5.32)倍,数据放大
(1.86)倍;后来DeepMind和Google认为模型参数量与数据同等重要,两者都应该分别放大
(3.16)倍。
3.1 方案1:固定模型,训练不同的token数目

通过方案1,得到N、D与C的幂次关系:模型尺寸和数据量同等重要,缩放比例相同,均为0.5。
3.2 方案2:固定FLOP

选取9种不同的计算量:e18−e21 ,观测不同参数量模型的训练情况:
在每条曲线的最小值的左侧,模型太小——在较少数据上训练的较大模型将是一种改进。
在每条曲线的最小值的右侧,模型太大——在更多数据上训练的较小模型将是一种改进。
最好的模型处于最小值。
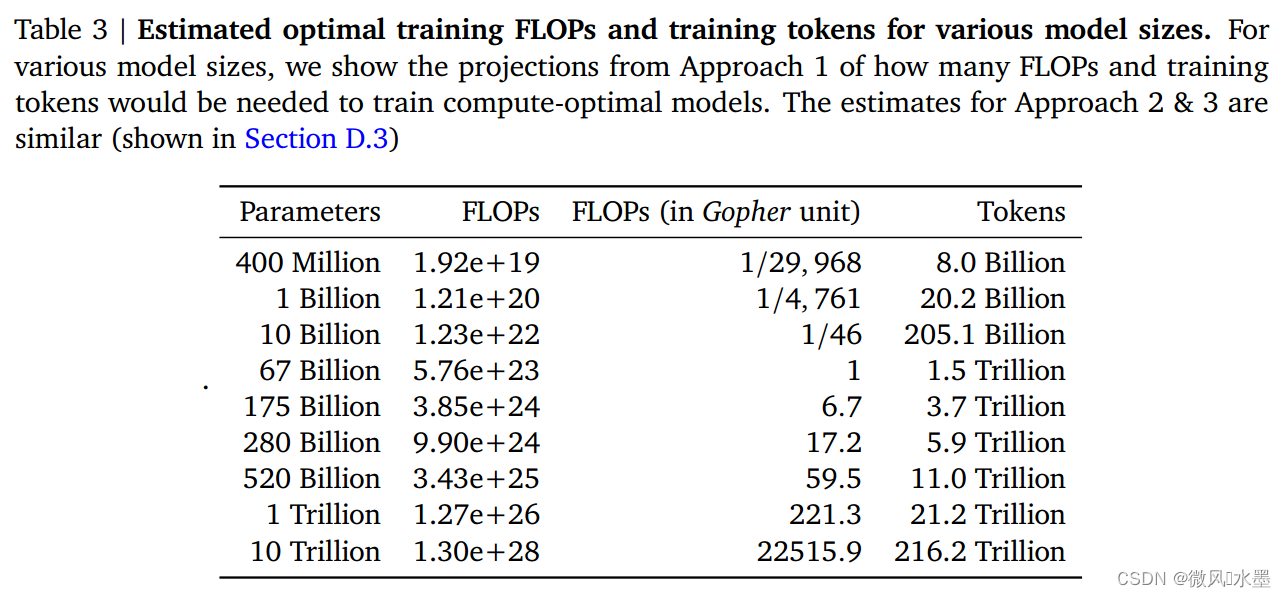
这个是DeepMind推荐的模型参数N、训练数据D、训练算力C的配比。可以发现和OpenAI的推荐是不一样的。也与BaiChuan2中7B/13B训练需要2.6T的数据量对不上。