青岛网站优化公司免费seo视频教学

文章目录
- 前言
- 一、需求
- 二、分析
- 三、处理
- 四、运行结果
前言
- 本系列文章来源于真实的需求
- 本系列文章你来提我来做
- 本系列文章仅供学习参考
- 阅读人群:有Python基础、Scrapy框架基础
一、需求
- 全站爬取游戏卡牌信息

二、分析
- 查看网页源代码,图片资源是否存在
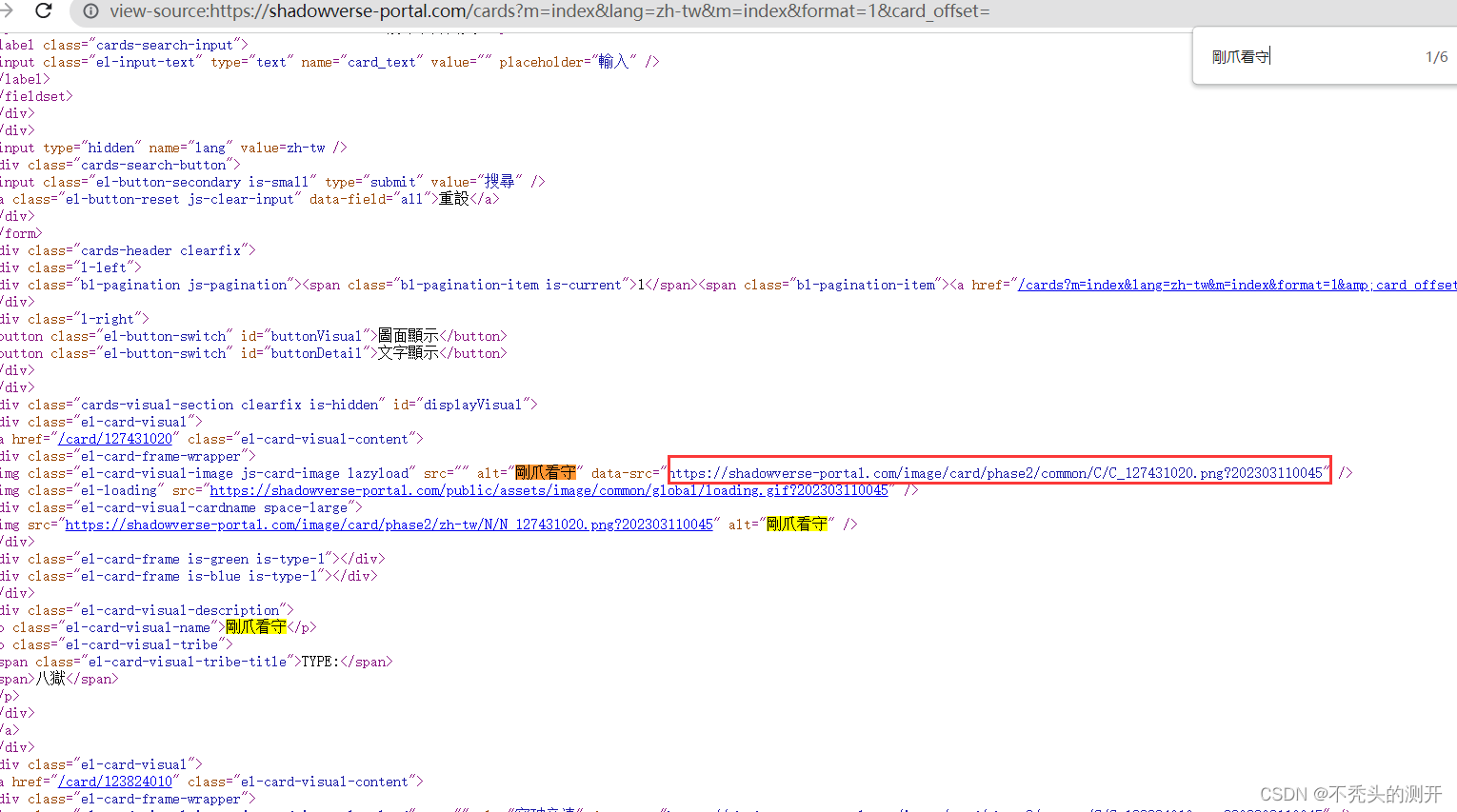
- 网页源码中,定位下一页url路径
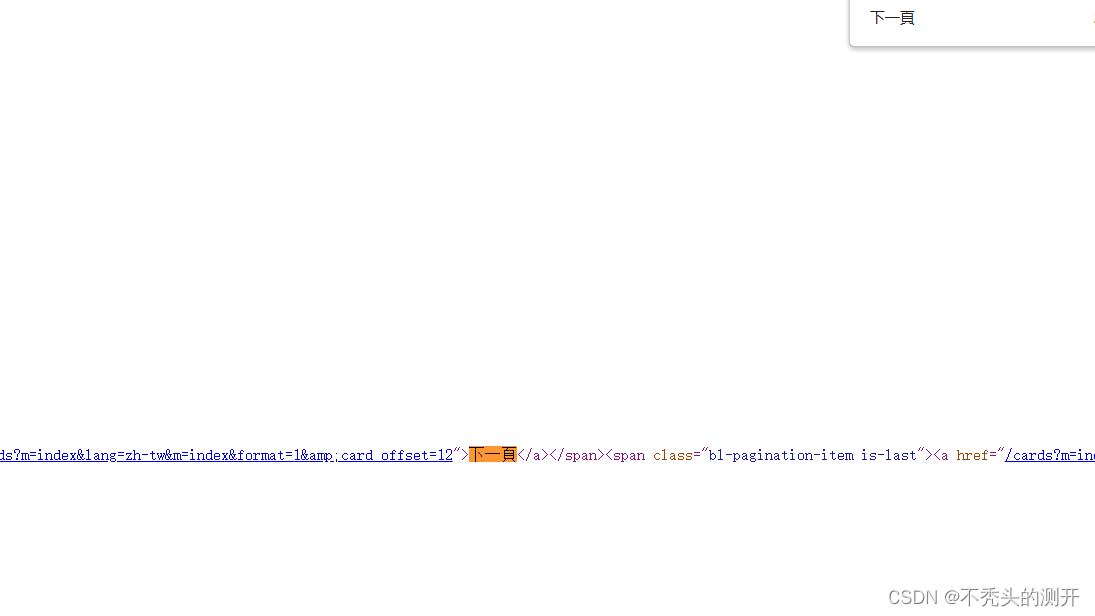
整体思路
1、通过Scrapy框架(中间件随机UA、代理)
2、通过Xpath构造单页爬取
3、通过Xpath定位下一页实现翻页功能
三、处理
初始化Scrapy框架
- Pycharm创建项目
- 安装Scrapy第三方库 pip install scrapy==2.5.1
- 创建项目 scrapy startproject card
- 进入card目录 cd card
- 创建爬虫 scrapy genspider get_card shadowverse-portal.com
- 修改start_urls

编写get_card 文件
1、获取标题和图片url
2、翻页功能
def parse(self, response):# 获取标题和图片urldisplay = response.xpath("//div[@id='displayVisual']")for d in display:img_url = d.xpath("//img[@class='el-card-visual-image js-card-image lazyload']/@data-src").extract()title = d.xpath("//img[@class='el-card-visual-image js-card-image lazyload']/@alt").extract()img_url_dict = dict(zip(title, img_url))for name, url in img_url_dict.items():yield {"url":url}# 翻页功能page = response.xpath("//div[@class='cards-footer']")for p in page:page_url = p.xpath("//span[@class='bl-pagination-item is-next']/a/@href").extract_first()# print(page_url)yield scrapy.Request(url=f"https://shadowverse-portal.com{page_url}",method="get",callback=self.parse)
通过管道保存资源,这里自定义方法通过ImagePIPline管道进行保存
1、安装模块 pip install pillow
2、settings配置管道、中间件
3、管道自定义图片下载方法
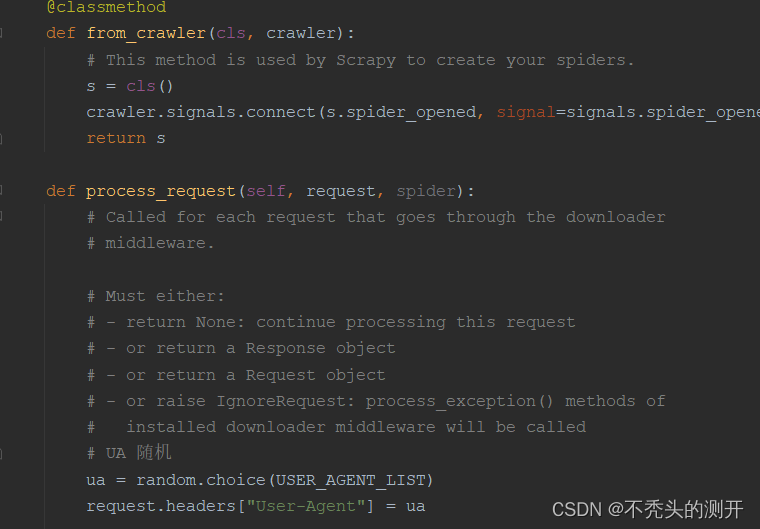
4、通过中间件实现UA随机
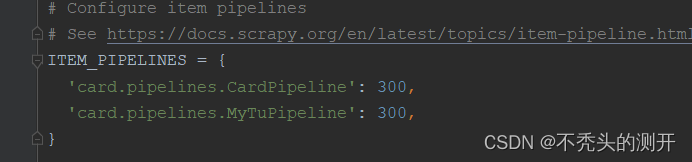


# 管道文件 pipelines.py
import scrapy
from scrapy.pipelines.images import ImagesPipelineclass MyTuPipeline(ImagesPipeline):# 1. 发送请求def get_media_requests(self, item, info):url = item['url']yield scrapy.Request(url=url, meta={"url": url}) # 直接返回一个请求对象即可# 2. 图片的存储路径def file_path(self, request, response=None, info=None, *, item=None):# 可以准备文件夹img_path = "card/"# 剔除file_path = item['url'].split("?")[0]file_name = file_path.split("/")[-1] # 用item拿到urlprint("item:", file_name)real_path = img_path + "/" + file_name # 文件夹路径拼接return real_path # 返回文件存储路径即可# 3. 可能需要对item进行更新def item_completed(self, results, item, info):for r in results:print(r[1]['path'])return item # 一定要return item 把数据传递给下一个管道
# setting.py文件
# UA随机
USER_AGENT_LIST = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36','Mozilla/5.0 (X11; Ubuntu; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2919.83 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2866.71 Safari/537.36','Mozilla/5.0 (X11; Ubuntu; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2820.59 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2762.73 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2656.18 Safari/537.36','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36','Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36','Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36','Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36','Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
]
# 中间件 middlewares.py
import random
from .settings import USER_AGENT_LIST.....def process_request(self, request, spider):ua = random.choice(USER_AGENT_LIST)request.headers["User-Agent"] = ua
.....
四、运行结果
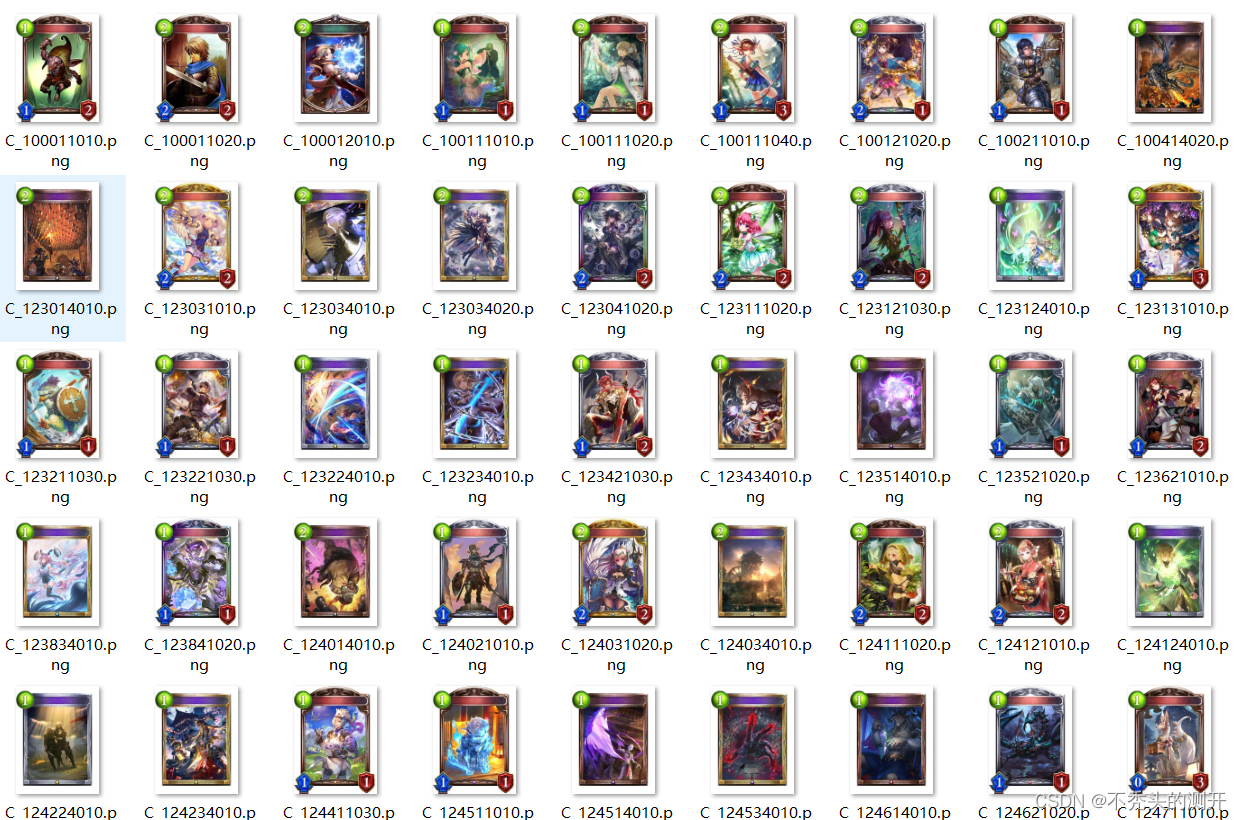
源码下载方式:
知识星球Python 网络爬虫模块
我正在「Print(“Hello Python”)」和朋友们讨论有趣的话题,你⼀起来吧?
https://t.zsxq.com/086uG3kOn
