wordpress 慢途网seo优化技巧有哪些
LSTM回归网络(1→1)
长短期记忆网络 - 通常只称为“LSTM” - 是一种特殊的RNN,能够学习长期的规律。 它们是由Hochreiter&Schmidhuber(1997)首先提出的,并且在后来的工作中被许多人精炼和推广。他们在各种各样的问题上应用得非常好,现在被广泛的使用。
LSTM简介
有一串时间序列数据[112,118,132,129,121,135],训练的本质是用后一个步长的数据作为Y去对应当前的X。
用一个步长预测一个,监督学习数据类型1->1
X Y
112 118
118 132
132 129
129 121
121 135
问题描述
所给的数据文件是1949-1960每月的航班乘客数量

源代码
# LSTM for international airline passengers problem with regression framing
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
"""
用一个步长预测一个,监督学习数据类型1->1
X Y
112 118
118 132
132 129
129 121
121 135
"""
# 将数据截取成1->1的监督学习格式
def create_dataset(dataset, look_back=1):dataX, dataY = [], []for i in range(len(dataset)-look_back-1):a = dataset[i:(i+look_back), 0]dataX.append(a)dataY.append(dataset[i + look_back, 0])return numpy.array(dataX), numpy.array(dataY)
# 定义随机种子,以便重现结果
numpy.random.seed(7)
# 加载数据
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
dataset = dataframe.values
dataset = dataset.astype('float32')
# 缩放数据
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 分割2/3数据作为测试
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
# 预测数据步长为1,一个预测一个,1->1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# 重构输入数据格式 [samples, time steps, features] = [93,1,1]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# 构建 LSTM 网络
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 对训练数据的Y进行预测
trainPredict = model.predict(trainX)
# 对测试数据的Y进行预测
testPredict = model.predict(testX)
# 对数据进行逆缩放
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算RMSE误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))# 构造一个和dataset格式相同的数组,共145行,dataset为总数据集,把预测的93行训练数据存进去
trainPredictPlot = numpy.empty_like(dataset)
# 用nan填充数组
trainPredictPlot[:, :] = numpy.nan
# 将训练集预测的Y添加进数组,从第3位到第93+3位,共93行
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict# 构造一个和dataset格式相同的数组,共145行,把预测的后44行测试数据数据放进去
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
# 将测试集预测的Y添加进数组,从第94+4位到最后,共44行
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict# 画图
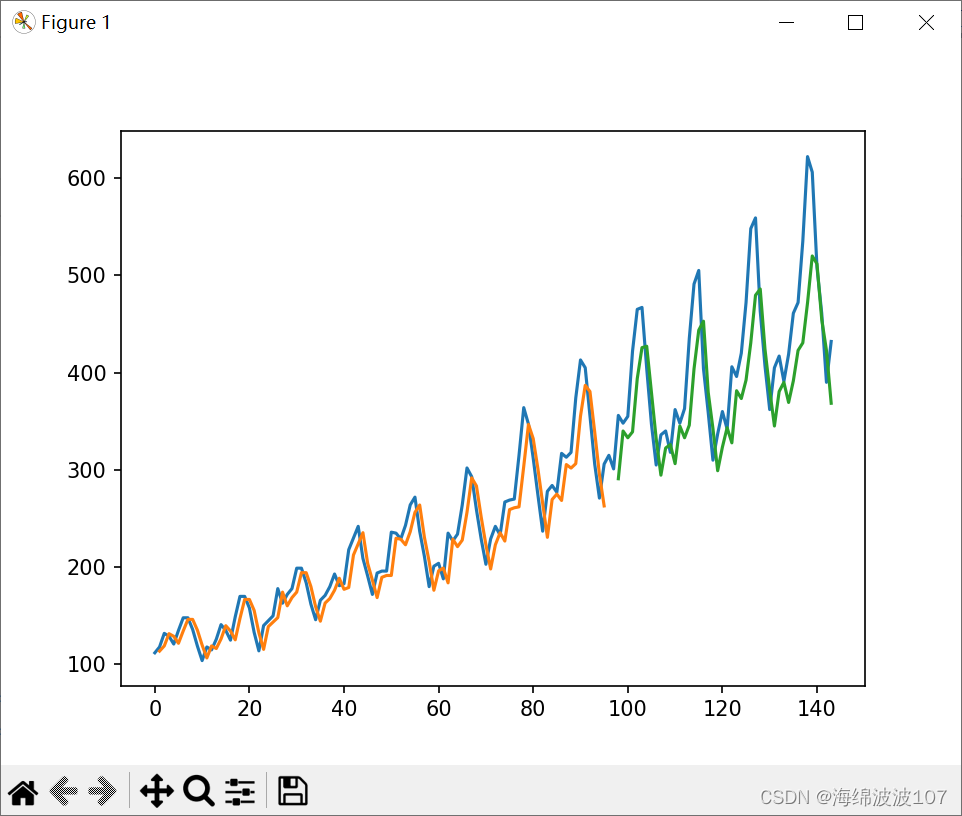
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
代码注释
1、scaler = MinMaxScaler(feature_range=(0, 1))。这段代码的意思是使用MinMaxScaler对数据进行归一化处理,将特征值缩放到0到1的范围内。
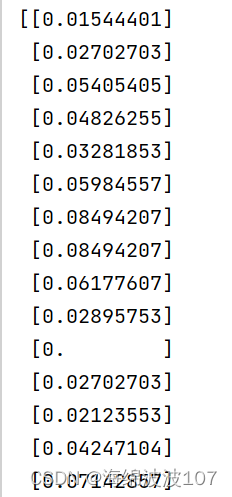
2、dataset = scaler.fit_transform(dataset)。这是一个常见的数据预处理步骤,将数据集进行归一化(或标准化)。在这个过程中,scaler是一个用于缩放数据的对象,可以使用fit_transform方法来对数据集进行归一化处理。这个方法会计算数据集的均值和标准差,并将数据进行转换,使得数据的分布符合均值为0,标准差为1的正态分布。通过归一化可以使得数据的不同特征在相同的尺度上进行比较和分析。转换后的部分数据如下:
3、model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss=‘mean_squared_error’, optimizer=‘adam’)
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)。
这段代码是使用Keras库构建了一个简单的循环神经网络(LSTM)模型。模型使用一个LSTM层,输入形状为(1, look_back),其中look_back是用于预测的时间步数。然后,通过添加一个全连接层(Dense)来输出预测结果。模型使用均方误差作为损失函数,优化器选择Adam。训练时使用了trainX作为输入数据,trainY作为目标数据,通过100个epochs进行训练,每个batch的大小为1,并且设置verbose=2打印训练过程的日志信息。
结果
参考博文
LSTM模型介绍