做网站分几步百度推广开户渠道
论文笔记
资料
1.代码地址
2.论文地址
https://arxiv.org/abs/1411.4038
3.数据集地址
论文摘要的翻译
卷积网络是强大的视觉模型,可以产生特征层次结构。我们表明,卷积网络本身,经过端到端,像素对像素的训练,在语义分割方面超过了最先进的技术。我们的关键见解是建立“完全卷积”网络,该网络可以接受任意大小的输入,并通过有效的推理和学习产生相应大小的输出。我们定义和详细描述了全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并绘制了与先前模型的连接。我们将当代分类网络(AlexNet , VGG网络和GoogLeNet)改编为全卷积网络,并通过微调将其学习到的表征转移到分割任务中。然后,我们定义了一种新的架构,该架构将来自深层粗糙层的语义信息与来自浅层精细层的外观信息相结合,以产生准确而详细的分割。我们的全卷积网络实现了PASCAL VOC(相对于2012年的62.2%平均IU提高了20%)、NYUDv2和SIFT Flow的最先进分割,而对典型图像的推理时间不到五分之一秒。
1背景
从粗糙到精细推理的关键一步自然是对每个像素进行预测。先前的方法使用卷积神经网络进行语义分割,其中每个像素都用其封闭对象或区域的类别进行标记,但该工作解决了缺点。
该方法具有渐近性和绝对性两方面的有效性,避免了其他工作中的复杂性。Patchwise训练很常见,但缺乏全卷积训练的效率。我们的方法没有利用预处理和后处理的复杂性,包括超像素,建议,或随机字段或局部分类器的事后细化[8,16]。我们的模型将最近在分类方面的成功转移到密集预测上,将分类网络重新解释为完全卷积的,并从其学习到的表示中进行微调。相比之下,以前的作品应用了没有监督预训练的小convnets。
语义分割面临语义和位置之间固有的紧张关系:全局信息解决什么问题,而局部信息解决哪里问题。=
2论文的创新点
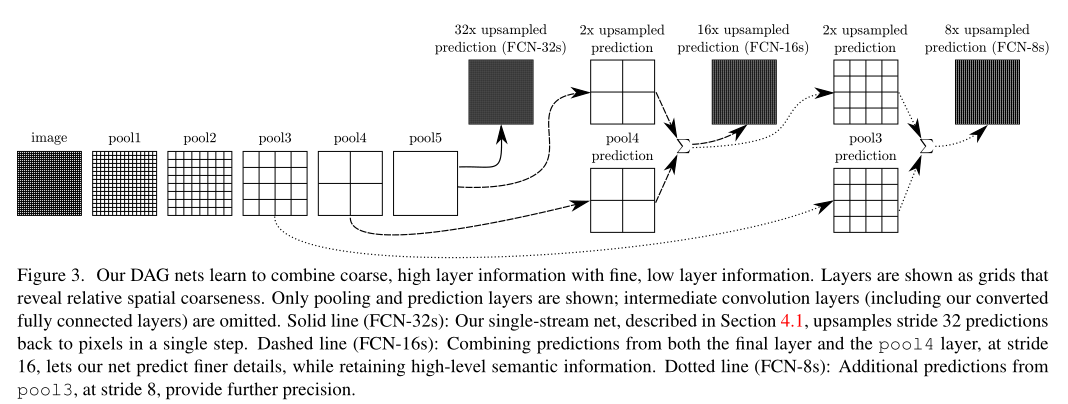
- 建立完全卷积网络,该网络可以接受任意大小的输入,并通过有效的推理和学习产生相应大小的输出。
- 定义了一种新的架构,该架构将来自深层粗糙层的语义信息与来自浅层精细层的外观信息相结合,以产生准确而详细的分割。
3 论文方法的概述
convnet中的每一层数据是一个大小为 h × w × d h × w × d h×w×d的三维数组,其中 h 和 w h和w h和w是空间维度, d d d是特征或通道维度。第一层是图像,像素大小为 h × w h × w h×w,有 d d d个颜色通道。更高层的位置对应于它们在图像中路径连接的位置,这些位置被称为它们的接受野。
3.1 Adapting classifiers for dense prediction
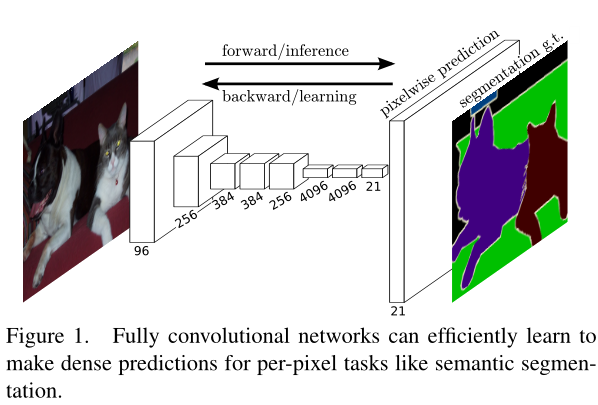
典型的识别网络,包括LeNet、AlexNet及其后继者,表面上采用固定大小的输入,并产生非空间输出。这些网的完全连接层具有固定的尺寸,并且抛弃了空间坐标。完全连接层也可以被视为卷积,其卷积核覆盖了整个输入区域。这样做将它们转换成完全卷积的网络,可以接受任何大小的输入和输出分类图。这一转变如图2所示

AlexNet示例中对应的反向时间为单张图像2.4 ms,全卷积10 × 10输出映射37 ms,导致类似于正向传递的加速。这种密集的反向传播如图1所示。
3.2Shift-and-stitch is filter rarefaction
输入移位和输出交错是OverFeat引入的一种技巧,可以在没有插值的情况下从粗输出中产生密集预测。如果输出按f的系数下采样,则输入(通过左和上填充)向右移动 x x x个像素,向下移动y个像素,对于每个 ( x , y ) ∈ { 0 , … , f − 1 } × { 0 , … , f − 1 } (x, y)∈\{0,…, f−1\}×\{0,…, f−1\} (x,y)∈{0,…,f−1}×{0,…,f−1} 这 f 2 f^2 f2个输入都通过convnet运行,输出是交错的,这样预测就与它们的接受域中心的像素相对应
只改变滤波器和convnet的层步长可以产生与这种移位和缝合技巧相同的输出。考虑一个输入步长为 s s s的层(卷积或池化),以及一个过滤器权重为 f i j f_{ij} fij的卷积层。将下层的输入步幅设置为1,将其输出采样5倍,就像shift-and-stitch一样。然而,将原始滤波器与上采样输出进行卷积不会产生与技巧相同的结果,因为原始滤波器只看到其(现在上采样)输入的减少部分。为了重现这个技巧,将滤波放大为 f i j ′ = { f i / s , j / s if s divides both i and j ; 0 otherwise , \left.f_{ij}^{\prime}=\left\{\begin{array}{ll}f_{i/s,j/s} & \text{if }s\text{ divides both }i\text{ and }j;\\ 0 & \text{otherwise},\end{array}\right.\right. fij′={fi/s,j/s0if s divides both i and j;otherwise,再现该技巧的完整净输出需要一层一层地重复这个滤波器放大,直到所有的子采样被移除。
在网络中简单地减少子采样是一种权衡:过滤器可以看到更精细的信息,但接受野更小,计算时间更长。我们已经看到,移位和缝合技巧是另一种权衡:在不减少过滤器的接受野大小的情况下,输出变得更密集,但过滤器被禁止以比原始设计更精细的规模访问信息。
33 上采样后向卷积
从某种意义上说,因子 f f f的上采样是与 1 / f 1/f 1/f的分数阶输入步长的卷积。只要 f f f是积分的,那么上采样的自然方法就是输出步长为 f f f的反卷积。因此,通过像素损失的反向传播,在网络中进行端到端学习的上采样。
3.4. Patchwise training is loss sampling
在随机优化中,梯度计算是由训练分布驱动的。拼接训练和全卷积训练都可以产生任何分布,尽管它们的相对计算效率取决于重叠和小批量大小。==全图像全卷积训练与patch - wise训练相同,其中每批训练由图像(或图像集合)损失以下的单元的所有接受域野组成。==虽然这比对补丁进行统一采样更有效,但它减少了可能批次的数量。然而,图像中随机选择的补丁可以简单地恢复。将损失限制为其空间项的随机抽样子集(或者,等效地在输出和损失之间应用将补丁从梯度计算中排除
如果保留的patch仍然有明显的重叠,全卷积计算仍然会加快训练速度。如果梯度累积在多个反向通道上,批次可以包括来自多个图像的补丁patch - wise训练中的采样可以纠正类不平衡,减轻密集patch的空间相关性。在全卷积训练中,也可以通过加权损失来实现类平衡,并且可以使用损失采样来解决空间相关性
4 论文实验
4.1 FCN
定义了一种新的全卷积网络(FCN)用于分割,它结合了特征层次结构的层并改进了输出的空间精度。参见图3。