做旅游计划的网站网络推广的方式
您是否应该删除、插入或估算?

世界上没有完美的数据集。每个数据科学家在数据探索过程中都会有这样的感觉:
df.info()
看到类似这样的内容:
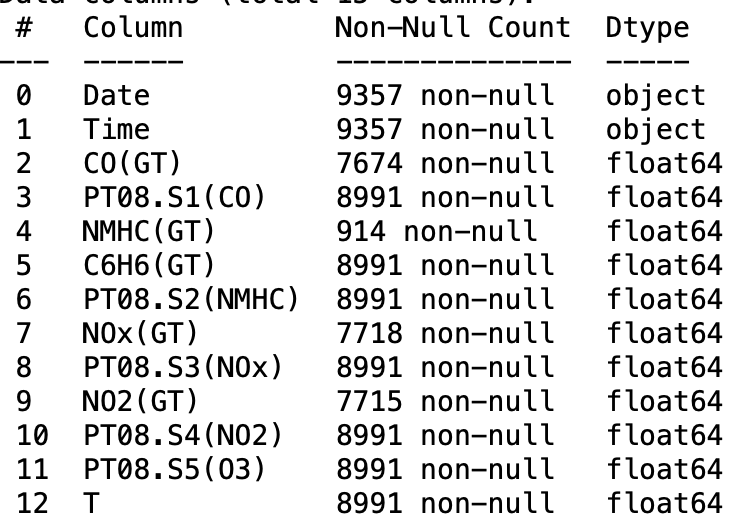
大多数 ML 模型无法处理 NaN 或空值,因此如果您的特征或目标包含这些值,则在尝试将模型拟合到数据之前对它们进行适当处理非常重要。
在本文中,我将探讨处理时间序列数据集中的空值/缺失数据的 3 种简单方法。
1. 删除空值
这可能是处理缺失数据最简单、最直接的方法:将其删除。
# 删除所有列中的所有空值
df.dropna(inplace=True)
默认情况下,pandas 的dropna 函数会全面搜索(所有列)空值,并删除任何列中存在空值的行**。**但是,可以使用各种参数进行修改。
在本数据集中,请注意 NMHC(GT) 列只有 914 个非空值。因此,如果我们删除所有空值,我们的模型最终最多只能得到 914 行(可能更少)。这与原来的 9,357 行相比大幅下降!
通过指定列的子集 ,pandas 将仅删除数据框中特定列为空的行。
df.dropna(subset=['CO(GT)','PT08.S1(CO)'], inplace=True)
这样,我们可以对方法进行混合和搭配,在某些列中删除空值,并以不同的方式处理其他列。
您还可以通过将参数how设置为“all”来指定是否仅删除所有列都为空的行。how 的默认值为“any”。
2. 插值空值
填充空值的另一种简单方法是通过插值。Pandas 的 interpolate 方法默认使用线性插值。
线性插值基本上取空值前后的两个值,并在两者之间创建一条线。然后使用这条线来估计缺失数据点的值。Pandas**的插值方法假设每个数据点的间距相等。**如果您没有针对每个可能的时间戳设置一行,只要您有日期时间索引,就可以将插值方法设置为“时间”。这样,如果您有两行相隔 >1 个间隔(例如 >1 天或 1 小时),插值将考虑这个距离。
如果这是第一个索引,由于空值前面没有值,因此不会进行插值。
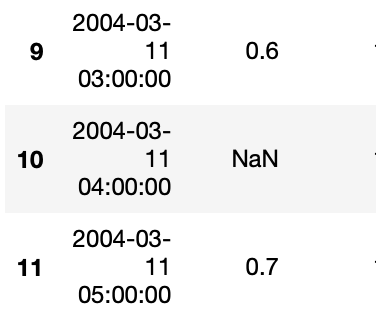
在这种情况下,插值很简单,因为在两个已知值的中间正好有 1 个空值。所有值都以 1 小时为间隔。索引 10 处的空值将只是前后值的平均值 (0.65)。
如果存在 2 个或更多连续的 NaN,则将根据它们与已知值之间的距离对它们进行插值。
**您可以通过limit**关键字参数设置要插入的连续 NaN 数量限制。如果有大量连续 NaN,您可能希望在某个插值点之后删除它们,因为*每次插值都会给算法带来不确定性。*插值越多 = 不确定性越大,尤其是在时间序列的情况下。
3. 归纳空值
我要介绍的最后一种方法是归纳法。归纳法本质上意味着用数据的平均值或中位数填充空值。
最简单的方法是使用 pandas 的 fillna 并取整列的中值。
df.fillna(df['CO(GT)'].median())
但对于时间序列,整个数据集的中值通常并不准确。时间序列数据通常具有季节性模式,使用情况会根据一天中的小时、星期几、月份等而变化。
对于这个例子,我决定使用该小时的中位数来估算 CO(GT) 列**。**
为了能够用中位数进行估算,我想出了自己的解决方案,因为没有直接的方法或库可以做到这一点(据我所知)。 我必须首先创建一个数据框,其中包含各个小时的所有中位数。
# 创建包含按小时分组的每列中位数的数据框
hour_df = pd.DataFrame(df.groupby([df.index.hour]).median())
hour_df.reset_index(inplace=True)
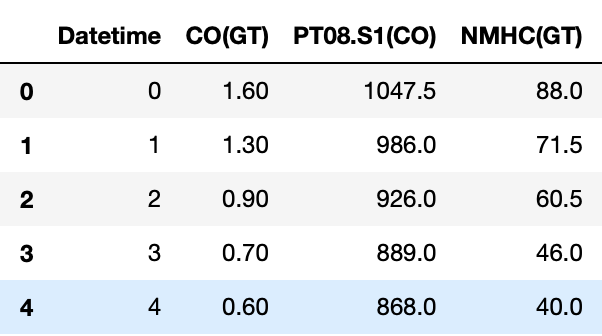
接下来,我创建了一个名为 get_hour_median 的函数。虽然我仅针对 CO(GT) 列展示了该函数,但我使该函数足够灵活,以便它可以处理任何列名。
def get_hour_median(hour,col_name):median = hour_df[hour_df['Datetime']==hour][col_name].values[0]return median
然后我使用 apply 和另一个自定义函数将此函数应用于 CO(GT) 列。
# 重置日期时间索引以便在下面的函数中更轻松地处理
df.reset_index(inplace=True)# 获取数据框行并返回中值(如果行为空),否则返回原始值。
def fill_with_hourly_median(row,col_name):if pd.isnull(row[col_name]):return get_hour_median(row['Datetime'].hour,col_name)else:return row[col_name]# 将 fill_with_hourly_median 应用于 CO(GT) 列
df['CO(GT)'] = df.apply(fill_with_hourly_median, axis=1, col_name='CO(GT)')
CO(GT) 列现在应该填写相应小时的中值而不是 NaN。
选择哪一个?
很多时候,您会针对不同的列使用不同方法的组合。例如,由于线性插值不会填充列中的第一个值,因此如果数据框开头有空行,则可以在数据框中间的行被插值后删除这些行。
如果您有大量数据,且空值不多,则删除几行不会产生太大影响。在这种情况下,删除通常是我的首选方法,因为我将输入模型的所有数据都是实际数据。
对于数据集中偶尔出现的小间隙(1-2 行缺失),我通常会使用插值法。但是,如果间隙较大,且存在大量连续的空值,我会考虑使用中位数,直到达到某个阈值(>6-10,但可能取决于数据的粒度和模式的一致性),之后我会开始删除行。
如您所见,虽然处理缺失数据是一种常见现象,但处理方法有很多考虑因素。我提到的方法绝不是唯一的方法,但仅使用这 3 种方法就可以做很多事情。
我建议 彻底探索您的时间序列数据,方法是绘制图表并确定零点在哪里、差距是大还是小以及存在哪些类型的季节性模式。随着时间和实践,您将对如何最好地处理数据中的差距有更好的直觉。
参考
- Vito,Saverio. (2016). Air Quality. UCI Machine Learning Repository. https://doi.org/10.24432/C59K5F.