安徽网站优化哪里有百度搜索引擎服务项目
因果推断(六)基于微软框架dowhy的因果推断
DoWhy 基于因果推断的两大框架构建:「图模型」与「潜在结果模型」。具体来说,其使用基于图的准则与 do-积分来对假设进行建模并识别出非参数化的因果效应;而在估计阶段则主要基于潜在结果框架中的方法进行估计。DoWhy 的整个因果推断过程可以划分为四大步骤:
- 「建模」(model):利用假设(先验知识)对因果推断问题建模
- 「识别」(identify):在假设(模型)下识别因果效应的表达式(因果估计量)
- 「估计」(estimate):使用统计方法对表达式进行估计
- 「反驳」(refute):使用各种鲁棒性检查来验证估计的正确性
同样的,不过多涉及原理阐述,具体的可以参考因果推断框架 DoWhy 入门。
准备数据
# !pip install dowhy
import pandas as pd
from dowhy import CausalModel
from IPython.display import Image, display
import warnings
warnings.filterwarnings('ignore') # 设置warning禁止
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【因果推断06】自动获取~
raw_data = pd.read_csv('BankChurners.csv')
raw_data.head()

特征工程
# 计算高额信贷:信贷额度超过20000
raw_data['High_limit'] = raw_data['Credit_Limit'].apply(lambda x: True if x > 20000 else False)
# 定义流失用户
raw_data['Churn'] = raw_data['Attrition_Flag'].apply(lambda x: True if x == 'Attrited Customer' else False)
# 剔除
- 目标变量(Y):Churn
- 干预变量(V/treatment):High_limit
- 混淆变量(W):其他变量
这里通过随机试验进行简单的因果关系判断:
# 随机试验简单判断因果关系
def simple_cause(df, y, treatment, n_sample):counts_sum=0for i in range(1,10000):counts_i = 0rdf = df.sample(n_sample)counts_i = rdf[rdf[y] == rdf[treatment]].shape[0]counts_sum+= counts_ireturn counts_sum/10000simple_cause(raw_data, 'Churn', 'High_limit', 1000)
750.6551 \displaystyle 750.6551 750.6551
- 对X~Y进行随机试验,随机取1000个观测,统计y=treatment的次数,如果越接近于500,则越无法确定因果关系,越接近0/1则估计存在因果
- 对上述实验随机进行了10000次,得到y=treatment的次数均值为750。因此假设存在一定的因果关系
因果推断建模
定义问题
y = 'Churn'
treatment = 'High_limit'
W = raw_data.drop([y, treatment, 'Credit_Limit', 'Attrition_Flag'], axis=1).columns.to_list()
问题定义为:额度限制是影响客户流失的原因,因为低限制类别的人可能不那么忠诚于银行
因果图建模
# 定义训练集:y+treatment+W
train = raw_data[[y, treatment]+W].copy()
# 定义因果图的先验假设
causal_graph = """
digraph {
High_limit;
Churn;
Income_Category;
Education_Level;
U[label="Unobserved Confounders"];
Education_Level->High_limit; Income_Category->High_limit;
U->Churn;
High_limit->Churn; Income_Category -> Churn;
}
"""
# 因果图绘制
model= CausalModel(data = train,graph=causal_graph.replace("\n", " "),treatment=treatment,outcome=y)
model.view_model()
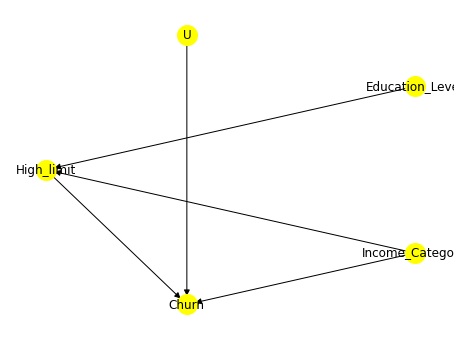
先验假设:额度高限制影响流失;收入类别影响额度限制从而影响流失;教育程度影响额度限制;其他混淆因素影响流失
识别
# 识别因果效应的估计量
ie = model.identify_effect()
print(ie)
Estimand type: nonparametric-ate### Estimand : 1
Estimand name: backdoor
Estimand expression:d
────────────(Expectation(Churn|Income_Category))
d[Highₗᵢₘᵢₜ]
Estimand assumption 1, Unconfoundedness: If U→{High_limit} and U→Churn then P(Churn|High_limit,Income_Category,U) = P(Churn|High_limit,Income_Category)### Estimand : 2
Estimand name: iv
Estimand expression:
Expectation(Derivative(Churn, [Education_Level])*Derivative([High_limit], [Edu
cation_Level])**(-1))
Estimand assumption 1, As-if-random: If U→→Churn then ¬(U →→{Education_Level})
Estimand assumption 2, Exclusion: If we remove {Education_Level}→{High_limit}, then ¬({Education_Level}→Churn)### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
- 我们称干预Treatment导致了结果Outcome,当且仅当在其他所有状况不变的情况下,干预的改变引起了结果的改变
- 因果效应即干预发生一个单位的改变时,结果变化的程度。通过因果图的属性来识别因果效应的估计量
- 根据先验假设,模型支持backdoor、和iv准则下的两者因果关系。具体的因果表达式见打印结果
估计因果效应
# 根据倾向得分的逆概率加权估计
estimate = model.estimate_effect(ie,method_name="backdoor.propensity_score_weighting")
print(estimate)
propensity_score_weighting
*** Causal Estimate ***## Identified estimand
Estimand type: nonparametric-ate### Estimand : 1
Estimand name: backdoor
Estimand expression:d
────────────(Expectation(Churn|Income_Category))
d[Highₗᵢₘᵢₜ]
Estimand assumption 1, Unconfoundedness: If U→{High_limit} and U→Churn then P(Churn|High_limit,Income_Category,U) = P(Churn|High_limit,Income_Category)## Realized estimand
b: Churn~High_limit+Income_Category
Target units: ate## Estimate
Mean value: -0.028495525240213704
估计平均值为-0.03,表明具有高额度限制的客户流失率降低了3%
反驳结果
# 随机共同因子检验:用随机选择的子集替换给定的数据集,如果假设是正确的,则估计值不应有太大变化。
refutel = model.refute_estimate(ie, estimate, "random_common_cause")
print(refutel)
Refute: Add a random common cause
Estimated effect:-0.028495525240213704
New effect:-0.02852304490516341
p value:0.96
# 数据子集:用随机选择的子集替换给定的数据集,如果假设是正确的,则估计值不应有太大变化。
refutel = model.refute_estimate(ie, estimate, "data_subset_refuter")
print(refutel)
Refute: Use a subset of data
Estimated effect:-0.028495525240213704
New effect:-0.027690470580490477
p value:0.98
# 安慰剂:用独立的随机变量代替真实的干预变量,如果假设是正确的,则估计值应接近零
refutel = model.refute_estimate(ie, estimate, "placebo_treatment_refuter")
print(refutel)
Refute: Use a Placebo Treatment
Estimated effect:-0.028495525240213704
New effect:0.0006977458004958939
p value:0.98
基于上述的反驳,即稳健检验。表明High_limit与Churn具有因果关系
总结
和上期一样,这里的分享也权当一种冷门数据分析方法的科普,如果想深入了解的同学可自行查找资源进行充电。因果推断算的上一门高深的专业知识了,我本人也只是了解了些皮毛,如果在后续工作中有较深层次的理解后,再进行补充分享吧。也欢迎该领域的大佬慷慨分享~
共勉~