交友网站该如何做东莞网络排名优化
背景
事情是这样的,当前业务有一个场景: 从业务库的Mysql抽取数据到Hive
由于运行环境的网络限制,当前选择的方案:
使用spark抽取业务库的数据表,然后利用impala jdbc数据灌输到hive。(没有spark on hive 的条件)
问题
结果就出现问题了:
报错信息如下:
java.sql.SQLFeatureNotSupportedException: [Cloudera][JDBC](10220) Driver does not support this optional feature.at com.cloudera.impala.exceptions.ExceptionConverter.toSQLException(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.checkTypeSupported(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.setNull(Unknown Source)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:658)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
23/03/04 23:24:51 WARN TaskSetManager: Lost task 0.0 in stage 1.0 (TID 1, localhost, executor driver): java.sql.SQLFeatureNotSupportedException: [Cloudera][JDBC](10220) Driver does not support this optional feature.at com.cloudera.impala.exceptions.ExceptionConverter.toSQLException(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.checkTypeSupported(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.setNull(Unknown Source)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:658)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
问题溯源
在spark从mysql中读出来的数据中,存在字段有string的类型。
这个类型在使用DataFrame.write.jdbc()通过impala jdbc向Hive中写数据的时候,如果没有创建Impala的jdbc Dialect的时候,此时这个String的类型,会被转换成
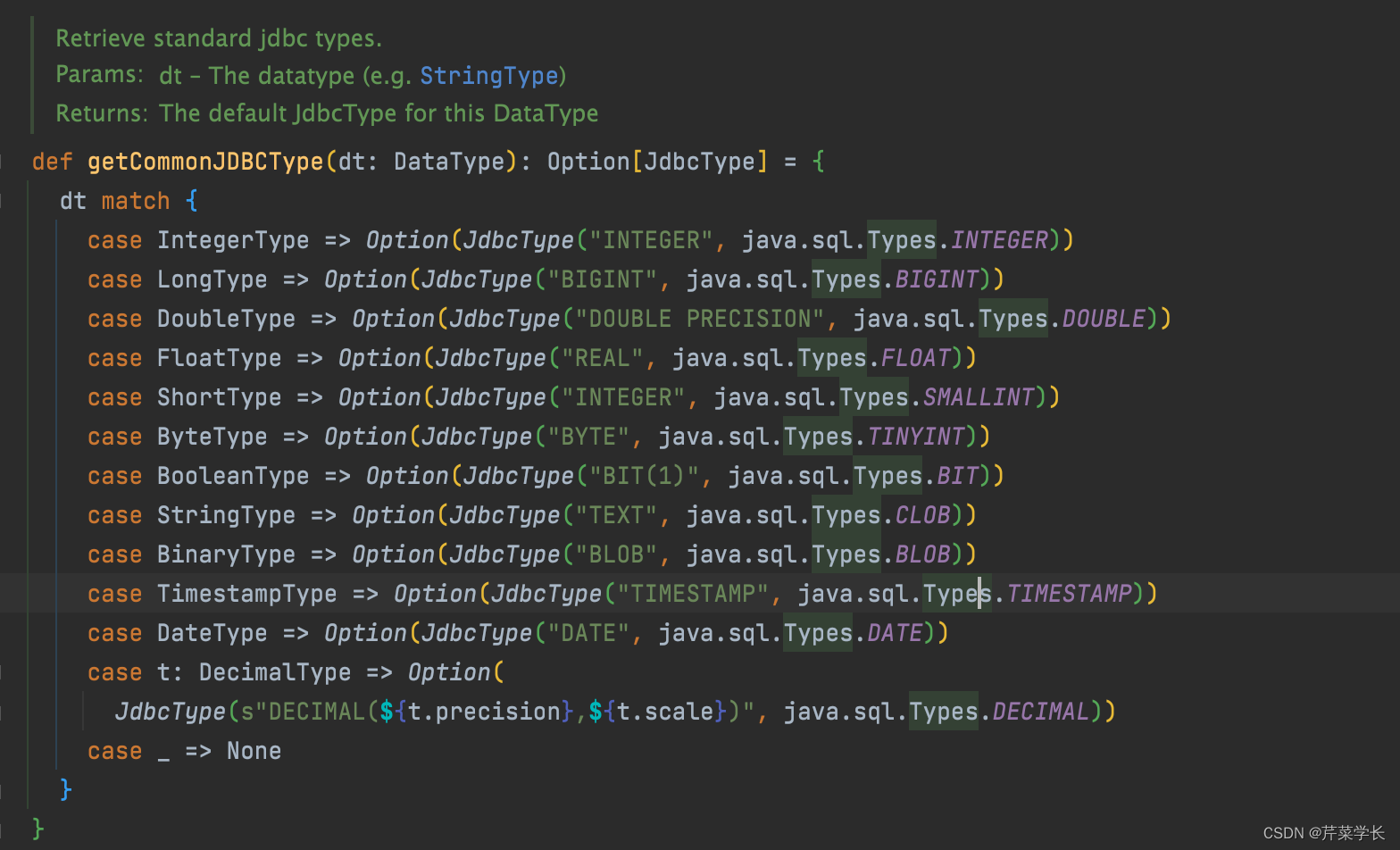
源自 org/apache/spark/sql/execution/datasources/jdbc/JdbcUtils.scala
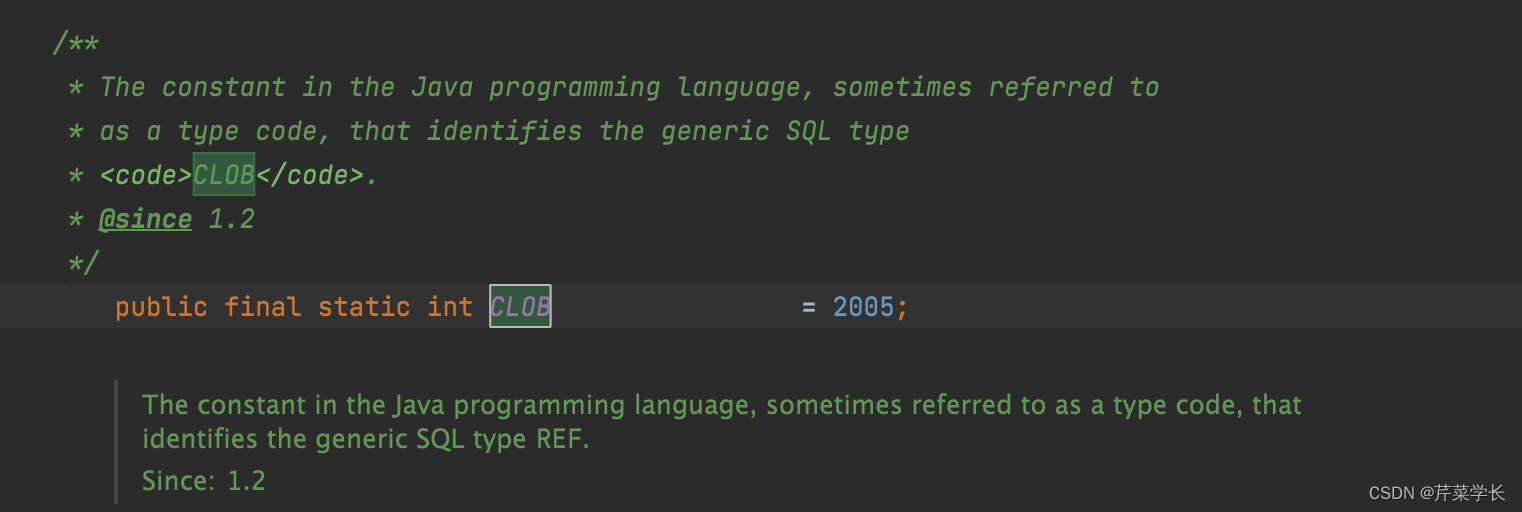
java.sql.Types.ClOB类型,戳进这个变量。可以看到它代表的值
接着,我们找到impala jdbc 的com.cloudera.impala.jdbc.common.SPreparedStatement#checkTypeSupported
方法,发现这个列表里面没有2005所以,程序代码会报错。
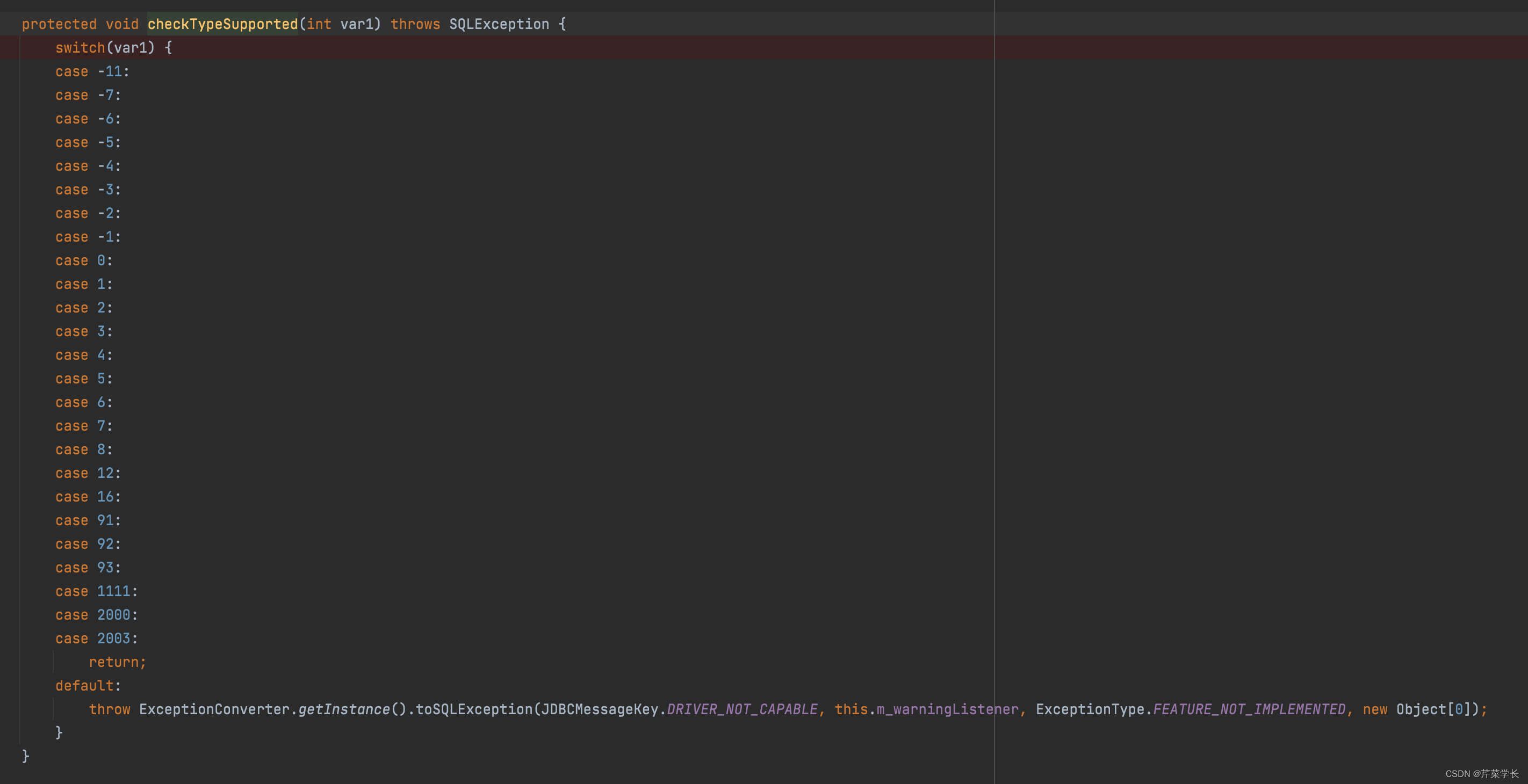
对应的数字编码:
com.cloudera.impala.dsi.dataengine.utilities.TypeUtilities#sqlTypeToString
public static String sqlTypeToString(short var0) {switch(var0) {case -11:return "SQL_GUID";case -10:return "SQL_WLONGVARCHAR";case -9:return "SQL_WVARCHAR";case -8:return "SQL_WCHAR";case -7:return "SQL_BIT";case -6:return "SQL_TINYINT";case -5:return "SQL_BIGINT";case -4:return "SQL_LONGVARBINARY";case -3:return "SQL_VARBINARY";case -2:return "SQL_BINARY";case -1:return "SQL_LONGVARCHAR";case 0:return "NULL";case 1:return "SQL_CHAR";case 2:return "SQL_NUMERIC";case 3:return "SQL_DECIMAL";case 4:return "SQL_INTEGER";case 5:return "SQL_SMALLINT";case 6:return "SQL_FLOAT";case 7:return "SQL_REAL";case 8:return "SQL_DOUBLE";case 12:return "SQL_VARCHAR";case 16:return "SQL_BOOLEAN";case 91:return "SQL_TYPE_DATE";case 92:return "SQL_TYPE_TIME";case 93:return "SQL_TYPE_TIMESTAMP";case 101:return "SQL_INTERVAL_YEAR";case 102:return "SQL_INTERVAL_MONTH";case 103:return "SQL_INTERVAL_DAY";case 104:return "SQL_INTERVAL_HOUR";case 105:return "SQL_INTERVAL_MINUTE";case 106:return "SQL_INTERVAL_SECOND";case 107:return "SQL_INTERVAL_YEAR_TO_MONTH";case 108:return "SQL_INTERVAL_DAY_TO_HOUR";case 109:return "SQL_INTERVAL_DAY_TO_MINUTE";case 110:return "SQL_INTERVAL_DAY_TO_SECOND";case 111:return "SQL_INTERVAL_HOUR_TO_MINUTE";case 112:return "SQL_INTERVAL_HOUR_TO_SECOND";case 113:return "SQL_INTERVAL_MINUTE_TO_SECOND";case 2003:return "SQL_ARRAY";default:return null;}}
解决
我们在代码中添加一个这样的类:
import org.apache.spark.sql.jdbc.JdbcDialect;
import org.apache.spark.sql.jdbc.JdbcType;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.MetadataBuilder;
import org.apache.spark.sql.types.StringType;
import scala.Option;import java.sql.Types;/*** @author wmh* @date 2021/1/12* impala的sql的方言,为了使impala sql能在spark中正确的执行*/
public class ImpalaDialect extends JdbcDialect {@Overridepublic boolean canHandle(String url) {return url.startsWith("jdbc:impala") || url.contains("impala");}@Overridepublic String quoteIdentifier(String colName) {return "`" + colName + "`";}@Overridepublic Option<DataType> getCatalystType(int sqlType, String typeName, int size, MetadataBuilder md) {return super.getCatalystType(sqlType, typeName, size, md);}@Overridepublic Option<JdbcType> getJDBCType(DataType dt) {if (dt instanceof StringType) {return Option.apply(new JdbcType("String", Types.VARCHAR));}return super.getJDBCType(dt);}
}
会出现这个问题:

at com.cloudera.impala.hivecommon.api.HS2Client.executeStatementInternal(Unknown Source)at com.cloudera.impala.hivecommon.api.HS2Client.executeStatement(Unknown Source)at com.cloudera.impala.hivecommon.dataengine.HiveJDBCNativeQueryExecutor.executeHelper(Unknown Source)at com.cloudera.impala.hivecommon.dataengine.HiveJDBCNativeQueryExecutor.execute(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.executePreparedAnyBatch(Unknown Source)at com.cloudera.impala.jdbc.common.SPreparedStatement.executeBatch(Unknown Source)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:667)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:834)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
Caused by: com.cloudera.impala.support.exceptions.GeneralException: [Cloudera][ImpalaJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: TStatus(statusCode:ERROR_STATUS, sqlState:HY000, errorMessage:AnalysisException: Char size must be > 0: 0
上述问题解释一下:
注意最后一句:errorMessage:AnalysisException: Char size must be > 0: 0
是因为在DataFrame里面存在’'没有长度的空字符串,这样的空字符串会导致如上报错
因为在spark构建insert into xx table values(cast('' as char(0)) ,因为这个char(0)的数字不能等于0,所以会出现如上错误。所以字符串中不能为
‘’,
源代码路径:impalajdbc41/2.6.4/impalajdbc41-2.6.4.jar!/com/cloudera/impala/impala/querytranslation/ImpalaInsertQueryGenerator.class
那么针对这个问题,我们要在impala的jdbc的参数上面加上一个UseNativeQuery=1, 即可解决该问题。
这个UseNativeQuery=1参数含义是:

上图来自impala jdbc的官方文档
我这里来翻译一下:
此属性指定驱动程序是否转换应用程序发出的查询。
1:驱动程序不会转换应用程序发出的查询,直接使用sql查询。
0:驱动程序将应用程序发出的查询转换为Impala SQL中的等效形式。
也就是说,如果查询sql本来就是impala查询sql,那么就不用进行转换了。
总结
如果有什么更好的方法,请在下方评论区留言,谢谢大哥们了!