bootstrap手机模板广安网站seo
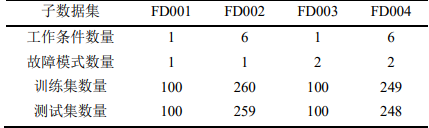
本例所用的数据集为C-MAPSS数据集,C-MAPSS数据集是美国NASA发布的涡轮风扇发动机数据集,其中包含不同工作条件和故障模式下涡轮风扇发动机多源性能的退化数据,共有 4 个子数据集,每个子集又可分为训练集、 测试集和RUL标签。其中,训练集包含航空发动机从开始运行到发生故障的所有状态参数; 测试集包含一定数量发动机从开始运行到发生故障前某一时间点的全部状态参数;RUL标签记录测试集中发动机的 RUL 值,可用于评估模 型的RUL预测能力。C-MAPSS数据集包含的基本信息如下:
添加图片注释,不超过 140 字(可选)
本例只采用FD001子数据集:

添加图片注释,不超过 140 字(可选)
关于python的集成环境,我一般Anaconda 和 winpython 都用,windows下主要用Winpython,IDE为spyder(类MATLAB界面)。

添加图片注释,不超过 140 字(可选)
正如peng wang老师所说
winpython, anaconda 哪个更好? - peng wang的回答 - 知乎 winpython, anaconda 哪个更好? - 知乎
winpython脱胎于pythonxy,面向科学计算,兼顾数据分析与挖掘;Anaconda主要面向数据分析与挖掘方面,在大数据处理方面有自己特色的一些包;winpython强调便携性,被做成绿色软件,不写入注册表,安装其实就是解压到某个文件夹,移动文件夹甚至放到U盘里在其他电脑上也能用;Anaconda则算是传统的软件模式。winpython是由个人维护;Anaconda由数据分析服务公司维护,意味着Winpython在很多方面都从简,而Anaconda会提供一些人性化设置。Winpython 只能在windows上用,Anaconda则有linux的版本。
抛开软件包的差异,我个人也推荐初学者用winpython,正因为其简单,问题也少点,由于便携性的特点系统坏了,重装后也能直接用。
请直接安装、使用winPython:WinPython download因为很多模块以及集成的模块

添加图片注释,不超过 140 字(可选)
可以选择版本,不一定要用最新版本,否则可能出现不兼容问题。
下载、解压后如下

添加图片注释,不超过 140 字(可选)
打开spyder就可以用了。
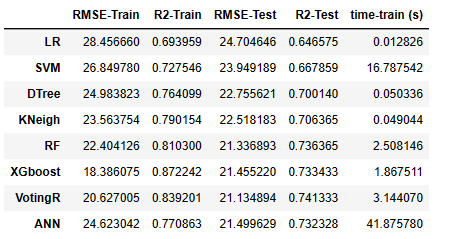
采用8种机器学习方法对NASA涡轮风扇发动机进行剩余使用寿命RUL预测,8种方法分别为:Linear Regression,SVM regression,Decision Tree regression,KNN model,Random Forest,Gradient Boosting Regressor,Voting Regressor,ANN Model。
首先导入相关模块
import pandas as pd import seaborn as sns import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.svm import SVR from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score import tensorflow as tf from tensorflow.keras.layers import Dense
版本如下:
tensorflow=2.8.0 keras=2.8.0 sklearn=1.0.2
导入数据
path = '' # define column names col_names=["unit_nb","time_cycle"]+["set_1","set_2","set_3"] + [f's_{i}' for i in range(1,22)] # read data df_train = train_data = pd.read_csv(path+"train_FD001.txt", index_col=False, sep= "\s+", header = None,names=col_names )
df_test和y_test同理导入,看一下训练样本
df_train.head()

添加图片注释,不超过 140 字(可选)
进行探索性数据分析
df_train[col_names[1:]].describe().T

添加图片注释,不超过 140 字(可选)
数据可视化分析:
sns.set_style("darkgrid") plt.figure(figsize=(16,10)) k = 1 for col in col_names[2:] : plt.subplot(6,4,k) sns.histplot(df_train[col],color='Green') k+=1 plt.tight_layout() plt.show()

添加图片注释,不超过 140 字(可选)
def remaining_useful_life(df): # Get the total number of cycles for each unit grouped_by_unit = df.groupby(by="unit_nb") max_cycle = grouped_by_unit["time_cycle"].max() # Merge the max cycle back into the original frame result_frame = df.merge(max_cycle.to_frame(name='max_cycle'), left_on='unit_nb', right_index=True) # Calculate remaining useful life for each row remaining_useful_life = result_frame["max_cycle"] - result_frame["time_cycle"] result_frame["RUL"] = remaining_useful_life # drop max_cycle as it's no longer needed result_frame = result_frame.drop("max_cycle", axis=1) return result_frame df_train = remaining_useful_life(df_train) df_train.head()
绘制最大RUL的直方图分布
plt.figure(figsize=(10,5)) sns.histplot(max_ruls.RUL, color='r') plt.xlabel('RUL') plt.ylabel('Frequency') plt.axvline(x=max_ruls.RUL.mean(), ls='--',color='k',label=f'mean={max_ruls.RUL.mean()}') plt.axvline(x=max_ruls.RUL.median(),color='b',label=f'median={max_ruls.RUL.median()}') plt.legend() plt.show()

添加图片注释,不超过 140 字(可选)
plt.figure(figsize=(20, 8)) cor_matrix = df_train.corr() heatmap = sns.heatmap(cor_matrix, vmin=-1, vmax=1, annot=True) heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':12}, pad=10);
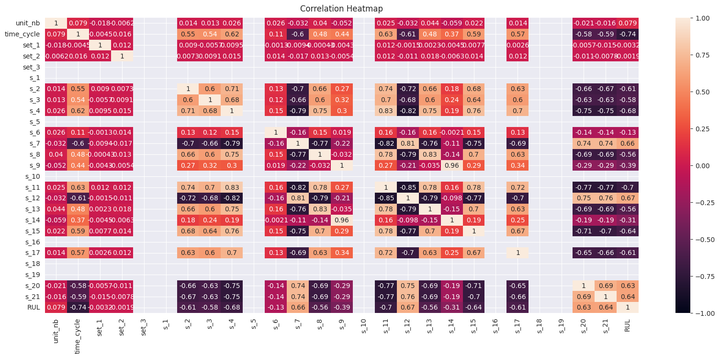
添加图片注释,不超过 140 字(可选)
col = df_train.describe().columns #we drop colummns with standard deviation is less than 0.0001 sensors_to_drop = list(col[df_train.describe().loc['std']<0.001]) + ['s_14'] print(sensors_to_drop) # df_train.drop(sensors_to_drop,axis=1,inplace=True) df_test.drop(sensors_to_drop,axis=1,inplace=True) sns.set_style("darkgrid") fig, axs = plt.subplots(4,4, figsize=(25, 18), facecolor='w', edgecolor='k') fig.subplots_adjust(hspace = .22, wspace=.2) i=0 axs = axs.ravel() index = list(df_train.unit_nb.unique()) for sensor in df_train.columns[1:-1]: for idx in index[1:-1:15]: axs[i].plot('RUL', sensor,data=df_train[df_train.unit_nb==idx]) axs[i].set_xlim(350,0) axs[i].set(xticks=np.arange(0, 350, 25)) axs[i].set_ylabel(sensor) axs[i].set_xlabel('Remaining Use Life') i=i+1

添加图片注释,不超过 140 字(可选)
X_train = df_train[df_train.columns[3:-1]] y_train = df_train.RUL X_test = df_test.groupby('unit_nb').last().reset_index()[df_train.columns[3:-1]] y_train = y_train.clip(upper=155) # create evalute function for train and test data def evaluate(y_true, y_hat): RMSE = np.sqrt(mean_squared_error(y_true, y_hat)) R2_score = r2_score(y_true, y_hat) return [RMSE,R2_score]; #Make Dataframe which will contain results Results = pd.DataFrame(columns=['RMSE-Train','R2-Train','RMSE-Test','R2-Test','time-train (s)'])
训练线性回归模型
import time Sc = StandardScaler() X_train1 = Sc.fit_transform(X_train) X_test1 = Sc.transform(X_test) # create and fit model start = time.time() lm = LinearRegression() lm.fit(X_train1, y_train) end_fit = time.time()- start # predict and evaluate y_pred_train = lm.predict(X_train1) y_pred_test = lm.predict(X_test1) Results.loc['LR']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results def plot_prediction(y_test,y_pred_test,score): plt.style.use("ggplot") fig, ax = plt.subplots(1, 2, figsize=(17, 4), gridspec_kw={'width_ratios': [1.2, 3]}) fig.subplots_adjust(wspace=.12) ax[0].plot([min(y_test),max(y_test)], [min(y_test),max(y_test)],lw=3,c='r') ax[0].scatter(y_test,y_pred_test,lw=3,c='g') ax[0].annotate(text=('RMSE: ' + "{:.2f}".format(score[0]) +'\n' + 'R2: ' + "{:.2%}".format(score[1])), xy=(0,140), size='large'); ax[0].set_title('Actual vs predicted RUL') ax[0].set_xlabel('Actual') ax[0].set_ylabel('Predicted'); ax[1].plot(range(0,100),y_test,lw=2,c='r',label = 'actual') ax[1].plot(range(0,100),y_pred_test,lw=1,ls='--', c='b',label = 'prediction') ax[1].legend() ax[1].set_title('Actual vs predicted RUL') ax[1].set_xlabel('Engine num') ax[1].set_ylabel('RUL'); plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练支持向量机模型
# create and fit model start = time.time() svr = SVR(kernel="rbf", gamma=0.25, epsilon=0.05) svr.fit(X_train1, y_train) end_fit = time.time()-start # predict and evaluate y_pred_train = svr.predict(X_train1) y_pred_test = svr.predict(X_test1) Results.loc['SVM']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练决策树模型
start=time.time() dtr = DecisionTreeRegressor(random_state=42, max_features='sqrt', max_depth=10, min_samples_split=10) dtr.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = dtr.predict(X_train1) y_pred_test = dtr.predict(X_test1) Results.loc['DTree']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练KNN模型
from sklearn.neighbors import KNeighborsRegressor # Evaluating on Train Data Set start = time.time() Kneigh = KNeighborsRegressor(n_neighbors=7) Kneigh.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = Kneigh.predict(X_train1) y_pred_test = Kneigh.predict(X_test1) Results.loc['KNeigh']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练随机森林模型
start = time.time() rf = RandomForestRegressor(n_jobs=-1, n_estimators=130,max_features='sqrt', min_samples_split= 2, max_depth=10, random_state=42) rf.fit(X_train1, y_train) y_hat_train1 = rf.predict(X_train1) end_fit = time.time()-start # predict and evaluate y_pred_train = rf.predict(X_train1) y_pred_test = rf.predict(X_test1) Results.loc['RF']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

添加图片注释,不超过 140 字(可选)
训练Gradient Boosting Regressor模型
from sklearn.ensemble import GradientBoostingRegressor # Evaluating on Train Data Set start = time.time() xgb_r = GradientBoostingRegressor(n_estimators=45, max_depth=10, min_samples_leaf=7, max_features='sqrt', random_state=42,learning_rate=0.11) xgb_r.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = xgb_r.predict(X_train1) y_pred_test = xgb_r.predict(X_test1) Results.loc['XGboost']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

训练Voting Regressor模型
from sklearn.ensemble import VotingRegressor start=time.time() Vot_R = VotingRegressor([("rf", rf), ("xgb", xgb_r)],weights=[1.5,1],n_jobs=-1) Vot_R.fit(X_train1, y_train) end_fit =time.time()-start # predict and evaluate y_pred_train = Vot_R.predict(X_train1) y_pred_test = Vot_R.predict(X_test1) Results.loc['VotingR']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results plot_prediction(y_test.RUL,y_pred_test,evaluate(y_test, y_pred_test))

训练ANN模型
star=time.time() model = tf.keras.models.Sequential() model.add(Dense(32, activation='relu')) model.add(Dense(64, activation='relu')) model.add(Dense(128, activation='relu')) model.add(Dense(128, activation='relu')) model.add(Dense(1, activation='linear')) model.compile(loss= 'msle', optimizer='adam', metrics=['msle']) history = model.fit(x=X_train1,y=y_train, epochs = 40, batch_size = 64) end_fit = time.time()-star # predict and evaluate y_pred_train = model.predict(X_train1) y_pred_test = model.predict(X_test1) Results.loc['ANN']=evaluate(y_train, y_pred_train)+evaluate(y_test, y_pred_test)+[end_fit] Results
工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家,担任《计算机科学》,《电子器件》 , 《现代制造过程》 ,《电源学报》,《船舶工程》 ,《轴承》 ,《工矿自动化》 ,《重庆理工大学学报》 ,《噪声与振动控制》 ,《机械传动》 ,《机械强度》 ,《机械科学与技术》 ,《机床与液压》,《声学技术》,《应用声学》,《石油机械》,《西安工业大学学报》等中文核心审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。