武汉科技职业学院是大专吗成都百度seo公司
一共六个脚本,分别是:
①generateDictionary.py用于生成词典
②datasets.py定义了数据集加载的方法
③models.py定义了网络模型
④configs.py配置一些参数
⑤run_train.py训练模型
⑥run_test.py测试模型
数据集![]() https://download.csdn.net/download/Victor_Li_/88486959?spm=1001.2014.3001.5501停用词表
https://download.csdn.net/download/Victor_Li_/88486959?spm=1001.2014.3001.5501停用词表![]() https://download.csdn.net/download/Victor_Li_/88486973?spm=1001.2014.3001.5501
https://download.csdn.net/download/Victor_Li_/88486973?spm=1001.2014.3001.5501
generateDictionary.py如下
import jiebadata_path = "./weibo_senti_100k.csv"
data_stop_path = "./hit_stopwords.txt"
data_list = open(data_path,encoding='utf-8').readlines()[1:]
stops_word = open(data_stop_path,encoding='utf-8').readlines()
stops_word = [line.strip() for line in stops_word]
stops_word.append(" ")
stops_word.append("\n")voc_dict = {}
min_seq = 1
top_n = 1000
UNK = "UNK"
PAD = "PAD"
for item in data_list:label = item[0]content = item[2:].strip()seg_list = jieba.cut(content,cut_all=False)seg_res = []for seg_item in seg_list:if seg_item in stops_word:continueseg_res.append(seg_item)if seg_item in voc_dict.keys():voc_dict[seg_item] += 1else:voc_dict[seg_item] = 1# print(content)# print(seg_res)voc_list = sorted([_ for _ in voc_dict.items() if _[1] > min_seq],key=lambda x:x[1],reverse=True)[:top_n]voc_dict = {word_count[0]:idx for idx,word_count in enumerate(voc_list)}voc_dict.update({UNK:len(voc_dict),PAD:len(voc_dict)+1})ff = open("./dict","w")
for item in voc_dict.keys():ff.writelines("{},{}\n".format(item,voc_dict[item]))
ff.close()datasets.py如下
from torch.utils.data import Dataset, DataLoader
import jieba
import numpy as npdef read_dict(voc_dict_path):voc_dict = {}with open(voc_dict_path, 'r') as f:for line in f:line = line.strip()if line == '':continueword, index = line.split(",")voc_dict[word] = int(index)return voc_dictdef load_data(data_path, data_stop_path,isTest):data_list = open(data_path, encoding='utf-8').readlines()[1:]stops_word = open(data_stop_path, encoding='utf-8').readlines()stops_word = [line.strip() for line in stops_word]stops_word.append(" ")stops_word.append("\n")voc_dict = {}data = []max_len_seq = 0for item in data_list:label = item[0]content = item[2:].strip()seg_list = jieba.cut(content, cut_all=False)seg_res = []for seg_item in seg_list:if seg_item in stops_word:continueseg_res.append(seg_item)if seg_item in voc_dict.keys():voc_dict[seg_item] += 1else:voc_dict[seg_item] = 1if len(seg_res) > max_len_seq:max_len_seq = len(seg_res)if isTest:data.append([label, seg_res,content])else:data.append([label, seg_res])return data, max_len_seqclass text_ClS(Dataset):def __init__(self, data_path, data_stop_path,voc_dict_path,isTest=False):self.isTest = isTestself.data_path = data_pathself.data_stop_path = data_stop_pathself.voc_dict = read_dict(voc_dict_path)self.data, self.max_len_seq = load_data(self.data_path, self.data_stop_path,isTest)np.random.shuffle(self.data)def __len__(self):return len(self.data)def __getitem__(self, item):data = self.data[item]label = int(data[0])word_list = data[1]if self.isTest:content = data[2]input_idx = []for word in word_list:if word in self.voc_dict.keys():input_idx.append(self.voc_dict[word])else:input_idx.append(self.voc_dict["UNK"])if len(input_idx) < self.max_len_seq:input_idx += [self.voc_dict["PAD"] for _ in range(self.max_len_seq - len(input_idx))]data = np.array(input_idx)if self.isTest:return label,data,contentelse:return label, datadef data_loader(dataset,config):return DataLoader(dataset,batch_size=config.batch_size,shuffle=config.is_shuffle,num_workers=4,pin_memory=True)models.py如下
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass Model(nn.Module):def __init__(self,config):super(Model,self).__init__()self.embeding = nn.Embedding(config.n_vocab,config.embed_size,padding_idx=config.n_vocab - 1)self.lstm = nn.LSTM(config.embed_size,config.hidden_size,config.num_layers,batch_first=True,bidirectional=True,dropout=config.dropout)self.maxpool = nn.MaxPool1d(config.pad_size)self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size,config.num_classes)self.softmax = nn.Softmax(dim=1)def forward(self,x):embed = self.embeding(x)out, _ = self.lstm(embed)out = torch.cat((embed, out), 2)out = F.relu(out)out = out.permute(0, 2, 1)out = self.maxpool(out).reshape(out.size()[0],-1)out = self.fc(out)out = self.softmax(out)return out
configs.py如下
import torch.typesclass Config():def __init__(self):self.n_vocab = 1002self.embed_size = 256self.hidden_size = 256self.num_layers = 5self.dropout = 0.8self.num_classes = 2self.pad_size = 32self.batch_size = 32self.is_shuffle = Trueself.learning_rate = 0.001self.num_epochs = 100self.devices = torch.device('cuda' if torch.cuda.is_available() else 'cpu')run_train.py如下
import torch
import torch.nn as nn
from torch import optim
from models import Model
from datasets import data_loader,text_ClS
from configs import Config
import time
import torch.multiprocessing as mpif __name__ == '__main__':mp.freeze_support()cfg = Config()data_path = "./weibo_senti_100k.csv"data_stop_path = "./hit_stopwords.txt"dict_path = "./dict"dataset = text_ClS(data_path, data_stop_path, dict_path)train_dataloader = data_loader(dataset,cfg)cfg.pad_size = dataset.max_len_seqmodel_text_cls = Model(cfg)model_text_cls.to(cfg.devices)loss_func = nn.CrossEntropyLoss()optimizer = optim.Adam(model_text_cls.parameters(), lr=cfg.learning_rate)scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.9)for epoch in range(cfg.num_epochs):running_loss = 0correct = 0total = 0epoch_start_time = time.time()for i,(labels,datas) in enumerate(train_dataloader):datas = datas.to(cfg.devices)labels = labels.to(cfg.devices)pred = model_text_cls.forward(datas)loss_val = loss_func(pred,labels)running_loss += loss_val.item()loss_val.backward()if ((i + 1) % 4 == 0) or (i + 1 == len(train_dataloader)):optimizer.step()optimizer.zero_grad()_, predicted = torch.max(pred.data, 1)correct += (predicted == labels).sum().item()total += labels.size(0)scheduler.step()accuracy_train = 100 * correct / totalepoch_end_time = time.time()epoch_time = epoch_end_time - epoch_start_timetain_loss = running_loss / len(train_dataloader)print("Epoch [{}/{}],Time: {:.4f}s,Loss: {:.4f},Acc: {:.2f}%".format(epoch + 1, cfg.num_epochs, epoch_time, tain_loss,accuracy_train))torch.save(model_text_cls.state_dict(),"./text_cls_model/text_cls_model{}.pth".format(epoch))run_test.py如下
import torch
import torch.nn as nn
from torch import optim
from models import Model
from datasets import data_loader,text_ClS
from configs import Config
import time
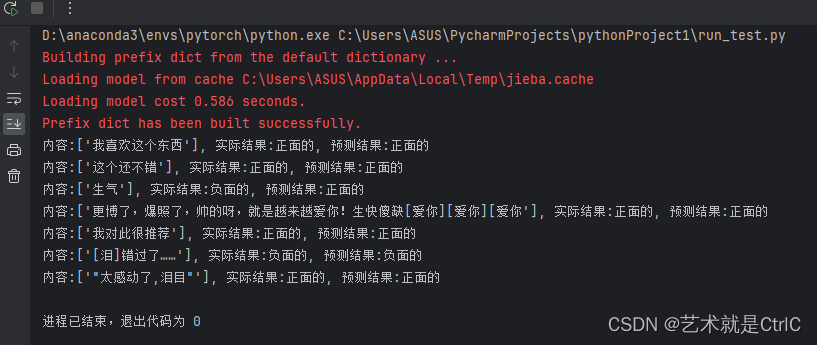
import torch.multiprocessing as mpif __name__ == '__main__':mp.freeze_support()cfg = Config()data_path = "./test.csv"data_stop_path = "./hit_stopwords.txt"dict_path = "./dict"cfg.batch_size = 1dataset = text_ClS(data_path, data_stop_path, dict_path,isTest=True)dataloader = data_loader(dataset,cfg)cfg.pad_size = dataset.max_len_seqmodel_text_cls = Model(cfg)model_text_cls.load_state_dict(torch.load('./text_cls_model/text_cls_model0.pth'))model_text_cls.to(cfg.devices)classes_name = ['负面的','正面的']for i,(label,input,content) in enumerate(dataloader):label = label.to(cfg.devices)input = input.to(cfg.devices)pred = model_text_cls.forward(input)_, predicted = torch.max(pred.data, 1)print("内容:{}, 实际结果:{}, 预测结果:{}".format(content,classes_name[label],classes_name[predicted[0]]))
测试结果如下