有哪些做封面的网站竞价广告代运营
人生苦短,我用python
这次给大家带来的是模块+实战
以便大家理解学习
觉得写的好的话,可以给我多多点赞鸭~
走心Python实战应用:【requests+re 模块】快速下载原shen图片
- 一、理解Python requests 模块
- 二、requests 方法
- 三、ruqusets 模块实战案例
- ❤部分代码展示
- 导入模块
- 发送请求
- 获取数据
- 获取章节ID
- 保存数据
- ❤效果展示
- 💢碎碎念预警:

一、理解Python requests 模块
Python 内置了 requests 模块,
该模块主要用来发 送 HTTP 请求,
requests 模块比 urllib 模块更简洁。
实例
# 导入 requests 包
import requests# 发送请求
x = requests.get('这里放网址')# 返回网页内容
print(x.text)
每次调用 requests 请求之后,
会返回一个 response 对象,
该对象包含了具体的响应信息。
实例
import requests
print(x.status_code)
print(x.reason)
print(x.apparent_encoding)
输出结果如下:
200
OK
utf-8
请求 json 数据文件,
返回 json 内容:
实例
import requests
x = requests.get('https://网站网址/try/ajax/json_demo.json')
print(x.json())
二、requests 方法
requests 方法如下表:
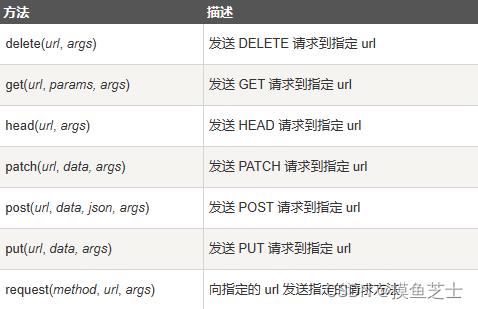
使用 requests.request() 发送 get 请求:
实例
import requests
x = requests.request('get', 'https://网址/')
print(x.status_code)
输出结果如下:
200
设置请求头:
实例
import requestskw = {'s':'python 教程'}headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}response = requests.get("这里放网址", params = kw, headers = headers)print (response.status_code)
print (response.encoding)
print (response.url)
print(response.text)
输出结果如下:
200
UTF-8
这里是网址?s=python+%E6%95%99%E7%A8%8B... 其他内容...
三、ruqusets 模块实战案例
纸上得来终觉浅,绝知此事要躬行
接下来就来案例实战吧
这次的网站如下图:

本次采集的目标是:
将这个网站的官方漫画采集下来
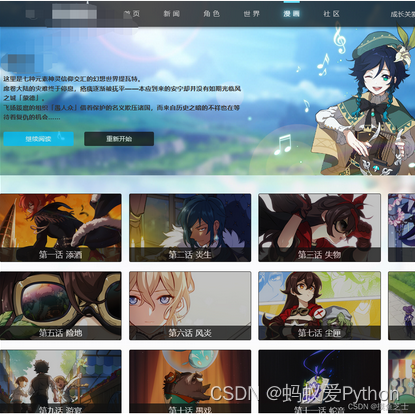
为什么要打码呢?
因为不打码就过不辽审核…
❤部分代码展示
导入模块
import requests
import re
发送请求
def get_response(html_url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari'}response = requests.get(url=html_url, headers=headers)return response
获取数据
def get_chapter(html_url):html_data = get_response(html_url).textchapter_list = re.findall('"(\d+)","第.*?话', html_data)return chapter_list
获取章节ID
def get_img_info(chapter_id):link = f'F12开发者工具获取'chapter_text = get_response(html_url=link).textimg_list = re.findall('<img .*?src="(.*?)"', chapter_text)title = re.findall('false,"(.*?)"', chapter_text)[0]return img_list, title
保存数据
def save(img, file):img_content = get_response(img).contentwith open(file, mode='wb') as f:f.write(img_content)print(img)
❤效果展示
夹带私货,截取一下海哥全脸哈哈哈
💢碎碎念预警:
可能会有人问我为什么不直接去官网上一章章看…
首先,这是一个锻炼项目,
目的是自己对requests模块的熟练程度进行加深;
其次,我真的很懒,
一次性全下载下来就很方便
万一想用手机看,
想看就马上看了鸭,
就没那么麻烦了(懒)
最后,是自己看,自己用,公开数据
总有那么些人总要杠我一下,
一次性说清楚用法用途,真的不理解意思就算了。
不管你是想磨练自己的技术还是想赚外包,
别触犯法律、别伤害他人就行。
