做的网站一直刷新软文吧
注1:本文系“计算机视觉/三维重建论文速递”系列之一,致力于简洁清晰完整地介绍、解读计算机视觉,特别是三维重建领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, TPAMI, IJCV 等)。
本次介绍的论文是: CVPR 2023 | 用户可控的条件图像到视频生成方法
文章DOI:
https://doi.org/10.48550/arXiv.2303.13744 ↗。
CVPR 2023 | 用户可控的条件图像到视频生成方法

1 引言
图像到视频(I2V)生成是计算机视觉领域一个迷人且富有潜力的研究课题。给定一张静态图像 x 0 x_0 x0和一个文本描述 y y y(例如“微笑”),条件图像到视频(cI2V)生成旨在合成出一个符合条件 y y y的新视频 x ^ _ 1 K \hat{x}\_1^K x^_1K。cI2V生成在艺术创作、娱乐产业以及机器学习的数据增广等方面都有巨大的应用前景。但是,cI2V生成面临的核心挑战在于如何同时生成符合图像 x 0 x_0 x0的视觉外观以及符合条件 y y y的时域动态。
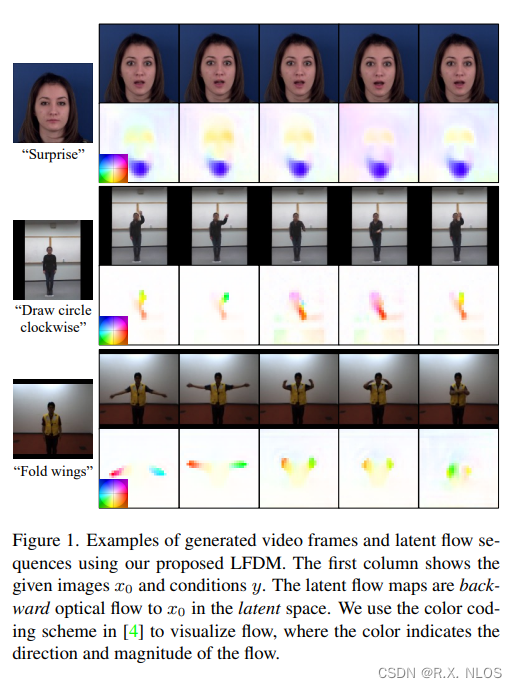
2 动机
以往的cI2V生成方法可以分为两大类:直接合成法和无扭曲合成法。
- 直接合成法
- 直接基于图像 x 0 x_0 x0和条件 y y y逐帧生成新的视频帧
- 但是这类方法往往难以同时满足视觉细节的保真和时域连贯性。
- 无扭曲合成法
- 先生成一系列扭曲场或光流,然后根据它们来扭曲或漂移图像 x 0 x_0 x0,从而合成新视频
- 但是它们的扭曲场或光流生成往往依赖额外的监督信息,例如人体姿态。对于只给定图像 x 0 x_0 x0和简单文本条件 y y y的情况,无扭曲合成法效果仍有限。
本文提出一种称为潜在流弥散模型(LFDM)的新型cI2V生成框架,以弥补现有方法的不足。LFDM的核心创新在于,它首先基于条件 y y y在潜在空间中合成一个时域连贯的光流序列,然后用该光流序列来扭曲图像 x 0 x_0 x0,从而生成新视频。这种基于扭曲的生成方式可以更好地利用图像 x 0 x_0 x0所包含的视觉细节,同时满足条件 y y y要求的运动动力学。
3 方法
LFDM的生成流程如图1所示。它包含两个阶段的训练。
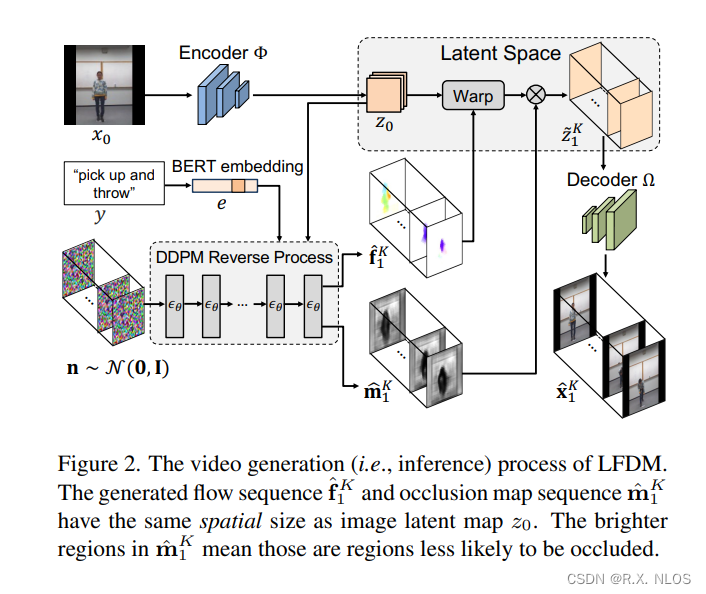
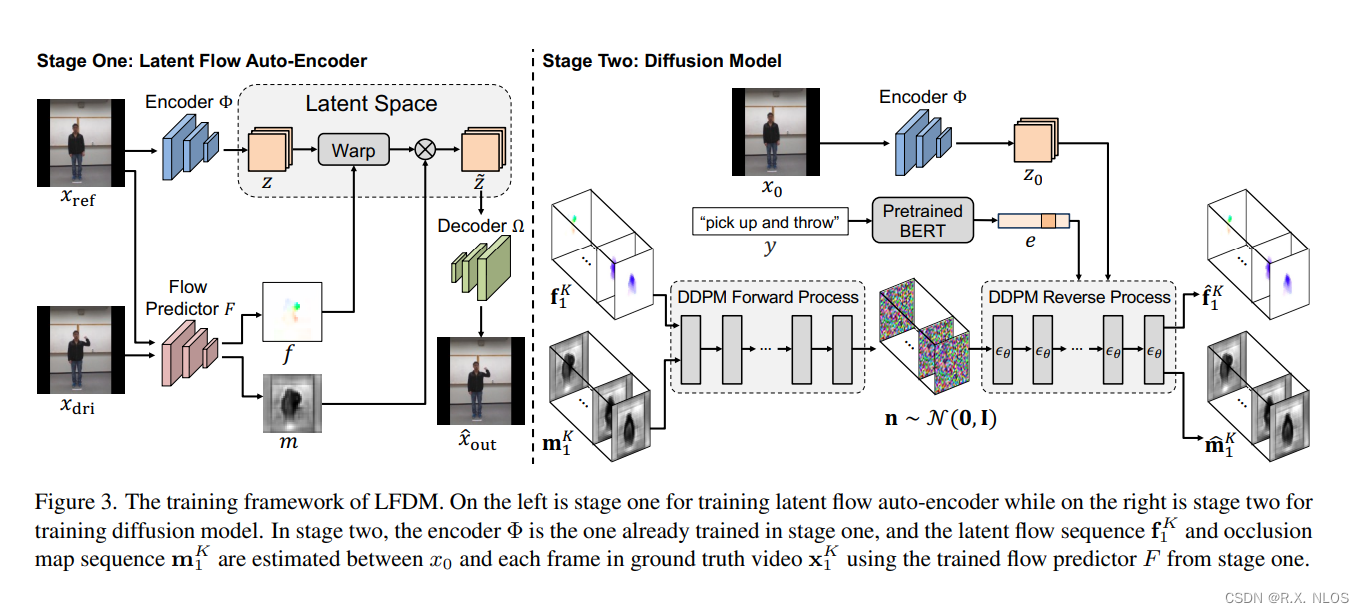
3.1 阶段一:潜在光流自动编码器
在阶段一中,我们用无标注视频训练一个潜在光流自动编码器(LFAE)。LFAE 包含编码器 Φ \Phi Φ、光流预测器 F F F和解码器 Ω \Omega Ω三个模块。给定一对来自同一视频的参考帧 x r e f x_{ref} xref和驱动帧 x d r i x_{dri} xdri,编码器 Φ \Phi Φ先把 x r e f x_{ref} xref编码为潜在空间的特征图 z z z,然后 F F F估计 x r e f x_{ref} xref到 x d r i x_{dri} xdri之间的逆向潜在空间光流 f f f。 f f f用于扭曲 z z z得到 z ~ \tilde{z} z~,最后 Ω \Omega Ω解码 z ~ \tilde{z} z~来重建 x d r i x_{dri} xdri。LFAE的训练目标是最小化重建损失。
3.2 阶段二:弥散模型
在阶段二中,我们训练一个基于3D U-Net的弥散模型(DM)来生成时域连贯的潜在光流序列。给定一段训练视频 x 0 K = x 0 , x 1 , . . . , x K x_0^K={x_0,x_1,...,x_K} x0K=x0,x1,...,xK和对应的标签 y y y,我们用阶段一训练好的 F F F来估计 x 0 x_0 x0到每个 x k x_k xk的光流 f k f_k fk。然后这些 f k f_k fk被DM以 y y y和 x 0 x_0 x0为条件,学习生成时域连贯的光流。相比像素空间或潜在特征空间,LFDM的DM只需要学习一个简单的低维光流空间,因此训练更高效。
4 实验和结果
我们在多个人脸表情、人体动作数据集上验证了LFDM的有效性。主要结论如下:
-
LFDM相比现有cI2V生成方法效果更好,可以同时保证视觉质量、时域连贯性和结果多样性。如图2所示,LFDM生成的视频质量明显优于对比方法。
-
LFDM可以轻松适配新域面部视频,只需要微调阶段一的解码器 O m e g a \\Omega Omega(图3)。这得益于LFDM分阶段的训练策略。
-
Ablation study表明,LFDM中DM的潜在光流空间维度低,计算量小,这有助于生成效率的提升(表1)。

图2. 不同方法的生成比较
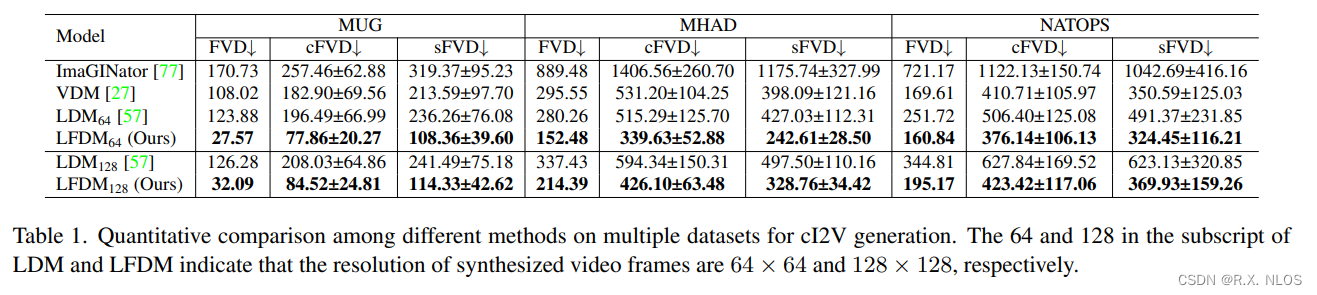

图3. 微调 O m e g a \\Omega Omega后在新域人脸数据集的生成效果提升
表1. 不同方法的生成时间和空间复杂度比较
| 模型 | 生成一段视频所需时间 | 潜在空间维度 |
|---|---|---|
| VDM | 112.5s | 40×64×64×3 |
| LFDM | 36s | 40×32×32×3 |
5 不足和未来展望
尽管取得了一定进展,LFDM仍存在一些局限:
-
当前仅支持单主体视频生成 。未来可以拓展至包含多个主体的光流预测。
-
输入条件仅为类别标签,期望支持基于文本的控制信号。
-
采样速度相比GAN慢 。可以探索一些快速采样策略以提升生成效率。
6 总结
本文提出了一种新型的基于潜在空间光流扭曲的条件图像到视频生成方法LFDM。
- 它可以高质量地生成符合条件要求的新视频。
- 分阶段的训练策略也使LFDM容易迁移到新域。
- 实验结果表明LFDM优于多种先进对比方法。
- 本文为条件视频生成任务提供了一种新的有效思路。