网站备案的账号找不到百度关键词排名点
PDF转为图片
- 背景
- pdf展示
- 目标效果
- 发展过程
- 最终解决方案:python PDF转图片
- pdf2image
- 注意:poppler 安装
背景
最近接了一项目,主要的需求就是本地的文联单位,需要做一个电子刊物阅览的网站,将民族的刊物发布到网站上供大众阅览。用户提供了pdf版本刊物。起初是用分布式文件系统,将pdf以流的形式直接传递给前端,前端使用canvas将dpf转为图片,再用jQuery、turn.js进行3D拟真翻书动画的阅览。前端在将pdf转为图片的过程太慢,严重影响了客户体验。想把pdf转图片的过程在后端进行处理。
pdf展示
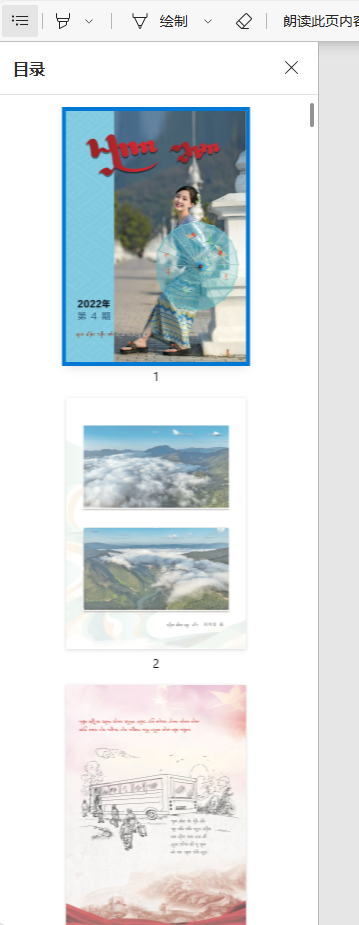
目标效果
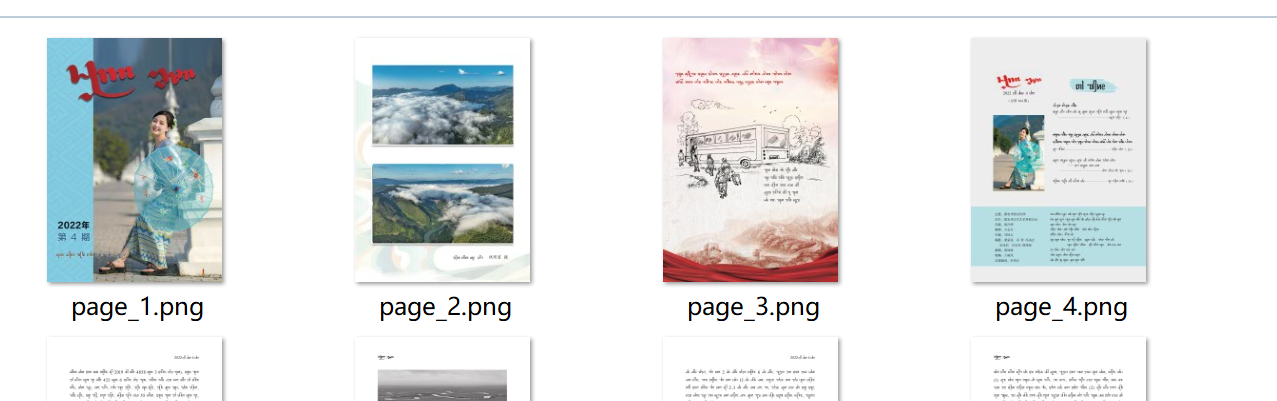
发展过程
开始参考了华为开发者联盟的一篇博客,尝试了上面所有方式。虽然不能达到效果,还是收藏一下。
java 实现pdf转换成图片
各种方式出现的问题基本都是:
下面就看一下,我保留下来的两个效果截图吧。
方式一:apache pdfbox
方式二:icepdf
最后后面我想了一下选择python试试,不行就再转js试试。
python也找了两个库,第一个尝试的是pymupdf,这个库需要安装Ghostscript ,代码我也照着cp了,依赖也安装了,中间调试也报了很多错,我没进行记录,最终的到了一个output.xps的文件,控制台也没有报错,也没有生成图片,以我对python的掌握是时候该换另一种方式了。又尝试了pdf2image库,依赖需要安装poppler,最终实现了目标。再冲java中调用python的批处理实现了java将pdf转为图片!!!
使用java调用python批处理将pdf转为图片
最终解决方案:python PDF转图片
pdf2image
版本:python3.8
使用Python的pdf2image库来将PDF文件转换为图片。首先,确保你已经安装了pdf2image库和相应的依赖库(比如poppler)。
你可以使用以下步骤在Python中进行PDF到图片的转换:
-
安装
pdf2image库:pip install pdf2image -
安装
poppler,这是一个用于处理PDF的工具:-
在Linux上,你可以使用包管理器安装,例如:
sudo apt-get install poppler-utils -
在Windows上,你可以从 poppler-utils 下载并安装。
-
-
编写Python脚本进行PDF到图片的转换:
from pdf2image import convert_from_pathdef pdf_to_images(pdf_path, output_folder):images = convert_from_path(pdf_path, output_folder=output_folder+"\\temp", poppler_path=r'E:\poppler-23.11.0\Library\bin') # 替换成你的Poppler路径for i, image in enumerate(images):image_path = f"{output_folder}\page_{i + 1}.png"image.save(image_path, 'PNG')print(f"Page {i + 1} saved as {image_path}")# 调用函数并传入PDF文件路径和输出文件夹路径
pdf_path = r"D:\Users\********\勇罕 2022年 第 4 期\勇罕 2022年 第 4 期.pdf"
output_folder = r"D:\Users\*******\勇罕 2022年 第 4 期"
pdf_to_images(pdf_path, output_folder)运行这个脚本后,PDF文件的每一页都会被转换为一张图片,并保存在指定的输出文件夹中。
生成的类似 21456f17-e88d-4382-ad48-70f3a1005c1d-081.ppm 的文件是由pdf2image库中的convert_from_path函数生成的临时文件。这些文件通常是以 .ppm 格式保存的,它是一种常见的图像文件格式,特别适用于存储以像素为基础的图像。
在使用convert_from_path函数时,库首先将PDF文件转换为一系列PPM格式的图像文件,然后再将它们转换为目标格式(例如PNG)。生成的PPM文件通常被存储在临时目录中,以便后续处理。在处理完成后,这些临时文件将被清理掉。
如果你想要控制生成的临时文件的位置,你可以在调用convert_from_path函数时指定output_folder参数,将其设置为你想要的目录。这样,生成的临时文件就会保存在指定的目录中。例如:
images = convert_from_path(pdf_path, output_folder="/path/to/your/temporary/folder")
请确保指定的目录存在,且有写入权限。如果你不想保留这些临时文件,可以在处理完成后手动删除它们,或者在使用convert_from_path函数时设置clean参数为True,以在处理完成后自动删除。例如:
images = convert_from_path(pdf_path, output_folder="/path/to/your/temporary/folder", clean=True)
这样,生成的临时文件将在处理完成后被自动删除。
注意:poppler 安装
如果你在Windows上无法安装poppler-utils,你可以尝试以下替代方法:
-
使用自包含的poppler工具:
-
在 poppler-for-windows 下载最新的Windows版本的zip文件。
-
解压缩zip文件,将其中的
bin目录添加到系统的环境变量中。这可以通过编辑系统环境变量中的Path来完成。
-
-
使用Chocolatey进行安装(如果你已经安装了Chocolatey):
choco install poppler这将自动安装poppler并将其添加到系统的环境变量中。
-
使用conda进行安装(如果你已经安装了conda):
conda install -c conda-forge poppler
请注意,你只需选择其中一种方法。安装完poppler之后,你应该能够在命令行中运行pdftoppm(poppler的一部分)来验证安装是否成功。如果成功,你应该能够使用上面提供的Python脚本将PDF转换为图片。