日本设计类网站大全seo求职
文章目录
- CSDN质量分查询
- selenium
- 爬取博客地址
- 单篇测试
- 批量查询
- 分析
CSDN质量分查询
CSDN对博客有一套分数评价标准,其查询入口在这里:质量分查询,效果大致如下
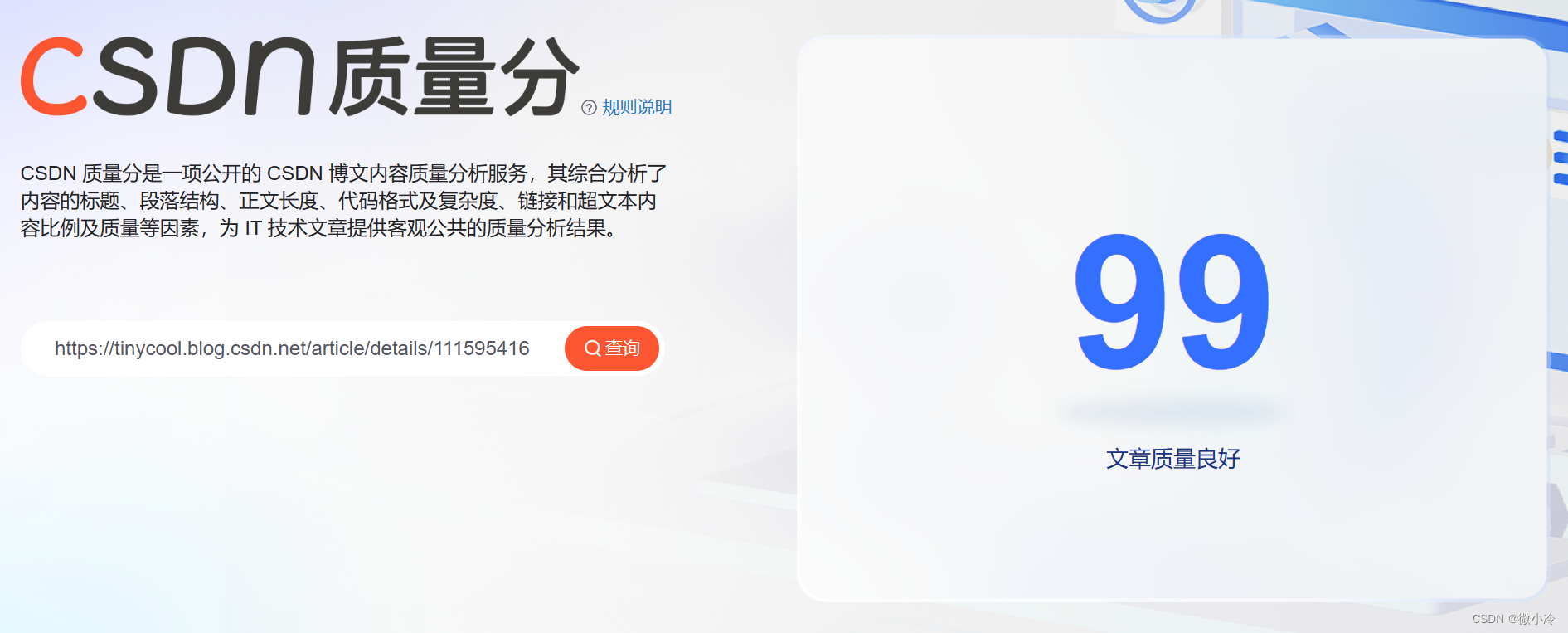
如果质量分太低,就会在博文的标题下面出现黄底黄字:
这个提示其实已经很客气了,我记得去年刚上线的时候写的是低质量博客,总之很有攻击性。
但是,这个评分标准毕竟不是一早就有的,所以早些年间写的博客不可能完全符合现在的CSDN的要求,为了找到需要改进质量的博客,可以通过爬虫的方式,逐一对博客质量进行检测。
selenium
考虑到查询需要有一个交互过程,所以这里采用selenium作为爬虫工具。如果没装的话,需要安装一下
pip install selenium
然后需要下载webdriver,各浏览器下载地址如下
| Edge | Chrome | Firefox | IEx |
|---|---|---|---|
| Webdriver | geckodriver | chromedriver | IEDriverServer |
下载之后解压,并将解压地址添加到环境变量,就可以顺利调用了。
爬取博客地址
首先第一步是获取所有需要查询的博客的地址,这一步并不需要用到selenium,urllib可以轻松搞定,这一步如果有疑问可以参考这篇:用Python标准库统计CSDN阅读量
import urllib.request as ur
import re
article = r'details/[0-9]*'
blogId = []
for i in range(1, 25):print(i)url = f'https://tinycool.blog.csdn.net/article/list/{i}'res = ur.urlopen(url)text = res.read().decode('utf-8')details = re.findall(article, text)blogId += [int(d.split('/')[-1]) for d in details]if len(details)==61:breakblogId = list(set(blogId))
网址https://tinycool.blog.csdn.net/article/list/是个人主页,好处是可以指定页码。但网页中除了博客栏之外,其他地方也会出现博客地址,从而导致最终得到的网址会重复,故而最后通过set去重。
单篇测试
在批量查询之前,先来测试一下单篇博客查询是否可行
from selenium import webdriver
from selenium.webdriver.common.by import Byinput_xpath = '/html/body/div[2]/div/div/div/div/div/div/div[1]/div/div/div[2]/div[1]/div[1]/input'
btn_xpath = '/html/body/div[2]/div/div/div/div/div/div/div[1]/div/div/div[2]/div[2]'
code_xpath = '/html/body/div[2]/div/div/div/div/div/div/div[1]/div/div[2]/p[1]'url = 'https://tinycool.blog.csdn.net/article/details/111595416'driver = webdriver.Edge()
driver.get("https://www.csdn.net/qc?utm_source=1966961068")
driver.find_element(By.XPATH, input_xpath).send_keys(url)
driver.find_element(By.XPATH, btn_xpath).click()
code = driver.find_element(By.XPATH, code_xpath).text
# 得到code=99
批量查询
单篇博客查询没问题,那么批量无非是外面套一个循环而已
import time
blogCode = []
def getOneCode(path):driver.find_element(By.XPATH, input_xpath).clear()driver.find_element(By.XPATH, input_xpath).send_keys(path)driver.find_element(By.XPATH, btn_xpath).click()time.sleep(0.5) # 给一个延时,否则点击未必会响应code = driver.find_element(By.XPATH, code_xpath).textreturn int(code)for id in blogId:path = f"https://tinycool.blog.csdn.net/article/details/{id}"try:blogCode.append([id, getOneCode(path)])except:blogCode.append([id, -1]) print(blogCode[-1])
效果如下

分析
没统计之前其实没意识到,统计之后发现一共有14篇博客得到了99分,超过60分的博客数目分别如下
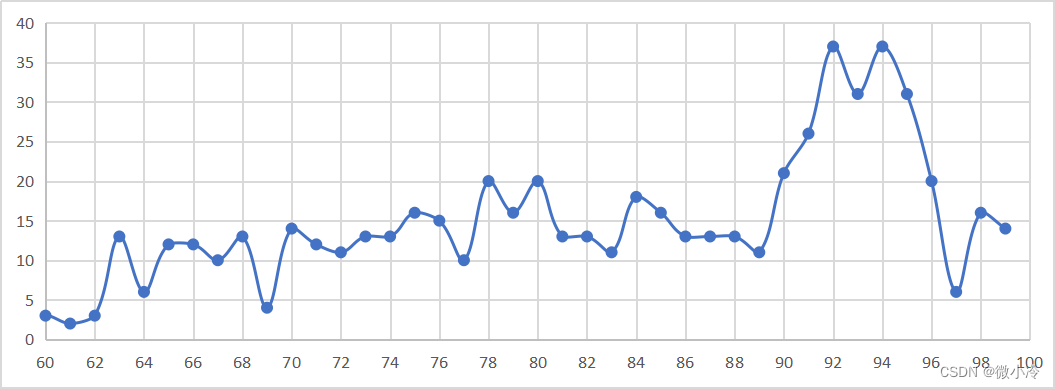
c99 = [bc for bc in blogCode if bc[1] == 99]
print(len(c99))
# 14
from pprint import pprint
## 下面是99分的博客id
[[103475445, 99],[103465319, 99],[100534775, 99],[103439486, 99],[103398694, 99],[103769447, 99],[103519671, 99],[103669180, 99],[103568966, 99],[103964310, 99],[100175523, 99],[97750903, 99],[111595416, 99],[103847843, 99]]
- Julia数值微积分
- Julia实现数值代数中的经典算法
- F#语言快速教程
- C语言实现八种排序算法
- Julia实现经典的插值算法
- C++面向对象入门这一篇就够了
- C语言实现链表、堆栈和队列
- C语言实现高级数据结构之B树
- 确定不收藏一下吗?你想要的语言环境这里都有
- Clojure极简教程
- python实现光线追迹(中):空间关系
- 用C语言写一个计算器
- go语言实现图的广度优先与深度优先搜索