淘宝客做自已的网站网上互联网推广
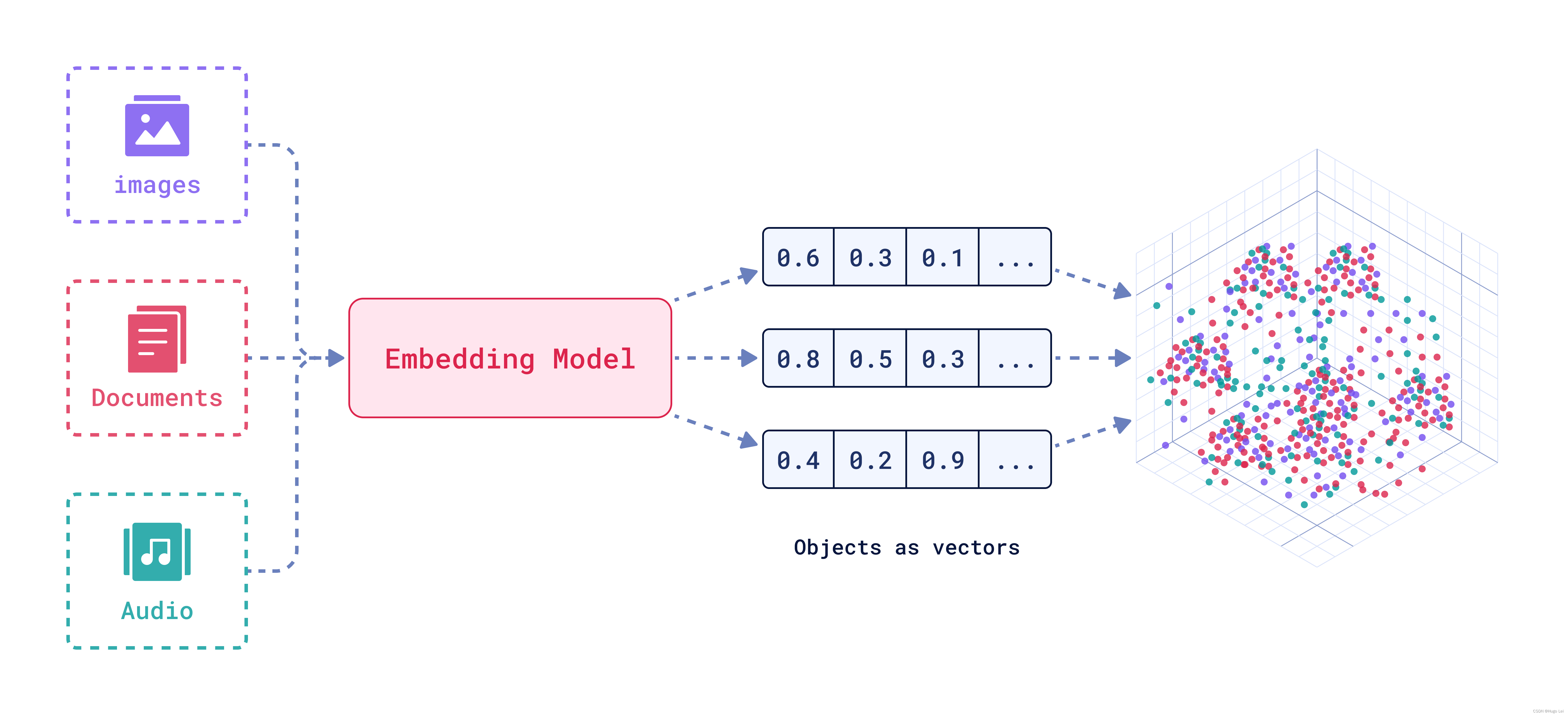
背景
BGE embedding系列模型是由智源研究院研发的中文版文本表示模型。
可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。
BAAI/BGE embedding系列模型
模型列表
| Model | Language | Description | query instruction for retrieval [1] | |
|---|---|---|---|---|
| BAAI/bge-m3 | Multilingual | 推理 微调 | 多功能(向量检索,稀疏检索,多表征检索)、多语言、多粒度(最大长度8192) | |
| LM-Cocktail | English | 微调的Llama和BGE模型,可以用来复现LM-Cocktail论文的结果 | ||
| BAAI/llm-embedder | English | 推理 微调 | 专为大语言模型各种检索增强任务设计的向量模型 | 详见 README |
| BAAI/bge-reranker-large | Chinese and English | 推理 微调 | 交叉编码器模型,精度比向量模型更高但推理效率较低 [2] | |
| BAAI/bge-reranker-base | Chinese and English | 推理 微调 | 交叉编码器模型,精度比向量模型更高但推理效率较低 [2] | |
| BAAI/bge-large-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | English | 推理 微调 | 向量模型,将文本转换为向量 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | English | 推理 微调 | base-scale 向量模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | English | 推理 微调 | small-scale 向量模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | Chinese | 推理 微调 | 向量模型,将文本转换为向量 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Chinese | 推理 微调 | base-scale 向量模型 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | Chinese | 推理 微调 | small-scale 向量模型 | 为这个句子生成表示以用于检索相关文章: |
C_MTEB榜单:Embedding
目前看榜单的话BAAI/bge-large-zh-v1.5是居于榜首的。(这里仅就刷榜而言)
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|---|---|---|---|---|---|---|---|---|
| BAAI/bge-large-zh-v1.5 | 1024 | 64.53 | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| BAAI/bge-base-zh-v1.5 | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| BAAI/bge-small-zh-v1.5 | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| BAAI/bge-large-zh | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| BAAI/bge-large-zh-noinstruct | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| BAAI/bge-base-zh | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| multilingual-e5-large | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| BAAI/bge-small-zh | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| m3e-base | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| m3e-large | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| multilingual-e5-base | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| multilingual-e5-small | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| text-embedding-ada-002(OpenAI) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| luotuo | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| text2vec-base | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| text2vec-large | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
bge-large-zh-v1.5
发布bge-*-v1.5向量模型,缓解相似度分布问题,提升无指令情况下的检索能力(但检索任务仍建议使用指令)
使用示例:
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5', query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T使用示例2:
在上篇文章LLM大语言模型(七):部署ChatGLM3-6B并提供HTTP server能力_failed to parse tool call, maybe the response is n-CSDN博客
中部署ChatGLM3-6B并提供HTTP server能力时,也是显示的用了 bge-large-zh-v1.5 embedding,可以让用户测试输入对应的embedding。(LLM实际使用的是tokenizer,默认包含了分词和embedding等)
@app.post("/v1/embeddings", response_model=EmbeddingResponse)
async def get_embeddings(request: EmbeddingRequest):embeddings = [embedding_model.encode(text) for text in request.input]embeddings = [embedding.tolist() for embedding in embeddings]参考
- LLM大语言模型(七):部署ChatGLM3-6B并提供HTTP server能力
- LLM大语言模型(四):在ChatGLM3-6B中使用langchain_chatglm3-6b langchain-CSDN博客
- LLM大语言模型(一):ChatGLM3-6B本地部署-CSDN博客