房屋租赁网站开发背景网络推广引流有哪些渠道
疑惑的起因
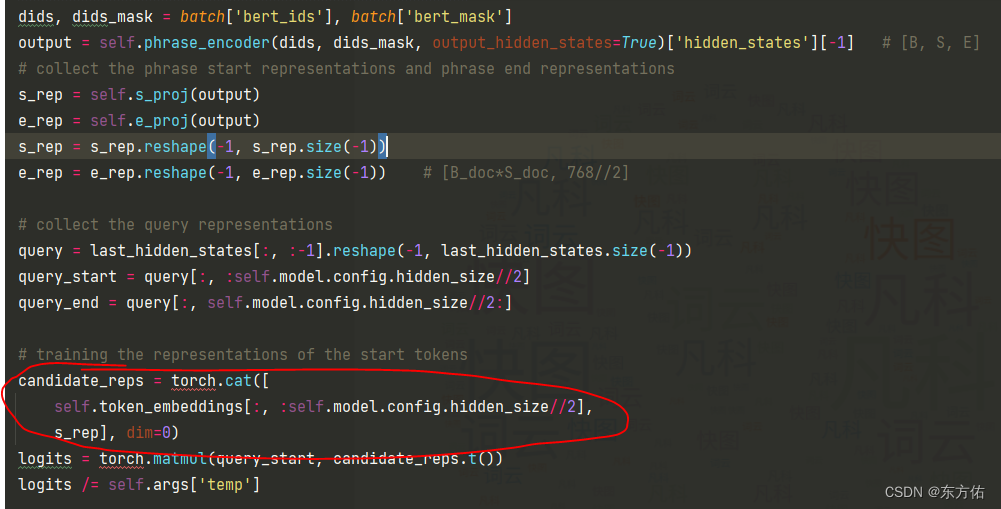
简化前向图
GPT4解释
这段代码实现了一个神经网络模型,包含了BERT、GPT-2和MLP等模块。主要功能是给定一个文本序列和一个查询序列,预测查询序列中的起始和结束位置,使其对应文本序列中的一个短语。具体实现细节如下:
首先,使用BERT将文本序列编码成一个张量作为输入,并从GPT-2模型中提取查询序列的表示。然后,将查询序列的表示拆分为起始和结束两部分,并使用MLP将短语的起始和结束点表示投影到另一个空间中。
接下来,利用生成式模型计算每个查询起始和结束位置之间的所有令牌的概率分布,并根据此生成预测位置。使用交叉熵损失函数来计算这些预测和真实值之间的差距。
最后,计算起始和结束位置的准确性和整个短语的准确性,并返回损失和准确性的值来优化模型的性能。
import torch
from transformers import AutoModel, AutoTokenizer, GPT2LMHeadModel
from torch import nn
from torch.nn import functional as Fclass Copyisallyouneed(nn.Module):def __init__(self, **args):super(Copyisallyouneed, self).__init__()self.args = args# bert-encoder modelself.phrase_encoder = AutoModel.from_pretrained(self.args['phrase_encoder_model'][self.args['lang']])self.bert_tokenizer = AutoTokenizer.from_pretrained(self.args['phrase_encoder_tokenizer'][self.args['lang']])self.bert_tokenizer.add_tokens(['<|endoftext|>', '[PREFIX]'])self.prefix_token_id = self.bert_tokenizer.convert_tokens_to_ids('[PREFIX]')self.phrase_encoder.resize_token_embeddings(self.phrase_encoder.config.vocab_size + 2)# model and tokenizerself.tokenizer = AutoTokenizer.from_pretrained(self.args['prefix_encoder_tokenizer'][self.args['lang']])self.vocab_size = len(self.tokenizer)self.pad = self.tokenizer.pad_token_id if self.args['lang'] == 'zh' else self.tokenizer.bos_token_idself.model = GPT2LMHeadModel.from_pretrained(self.args['prefix_encoder_model'][self.args['lang']])self.token_embeddings = nn.Parameter(list(self.model.lm_head.parameters())[0])# MLP: mapping bert phrase start representationsself.s_proj = nn.Sequential(nn.Dropout(p=args['dropout']),nn.Tanh(),nn.Linear(self.model.config.hidden_size, self.model.config.hidden_size // 2))# MLP: mapping bert phrase end representationsself.e_proj = nn.Sequential(nn.Dropout(p=args['dropout']),nn.Tanh(),nn.Linear(self.model.config.hidden_size, self.model.config.hidden_size // 2))self.gen_loss_fct = nn.CrossEntropyLoss(ignore_index=self.pad)@torch.no_grad()def get_query_rep(self, ids):self.eval()output = self.model(input_ids=ids, output_hidden_states=True)['hidden_states'][-1][:, -1, :]return outputdef get_token_loss(self, ids, hs, ids_mask):# no pad tokenlabel = ids[:, 1:]logits = torch.matmul(hs[:, :-1, :],self.token_embeddings.t())# TODO: inner loss function remove the temperature factorlogits /= self.args['temp']loss = self.gen_loss_fct(logits.view(-1, logits.size(-1)), label.reshape(-1))chosen_tokens = torch.max(logits, dim=-1)[1]gen_acc = (chosen_tokens.reshape(-1) == label.reshape(-1)).to(torch.long)valid_mask = (label != self.pad).reshape(-1)valid_tokens = gen_acc & valid_maskgen_acc = valid_tokens.sum().item() / valid_mask.sum().item()return loss, gen_accdef forward(self, batch):## gpt2 query encoderids, ids_mask = batch['gpt2_ids'], batch['gpt2_mask']last_hidden_states = \self.model(input_ids=ids, attention_mask=ids_mask, output_hidden_states=True).hidden_states[-1]# get token lossloss_0, acc_0 = self.get_token_loss(ids, last_hidden_states, ids_mask)## encode the document with the BERT encoder modeldids, dids_mask = batch['bert_ids'], batch['bert_mask']output = self.phrase_encoder(dids, dids_mask, output_hidden_states=True)['hidden_states'][-1] # [B, S, E]# collect the phrase start representations and phrase end representationss_rep = self.s_proj(output)e_rep = self.e_proj(output)s_rep = s_rep.reshape(-1, s_rep.size(-1))e_rep = e_rep.reshape(-1, e_rep.size(-1)) # [B_doc*S_doc, 768//2]# collect the query representationsquery = last_hidden_states[:, :-1].reshape(-1, last_hidden_states.size(-1))query_start = query[:, :self.model.config.hidden_size // 2]query_end = query[:, self.model.config.hidden_size // 2:]# training the representations of the start tokenscandidate_reps = torch.cat([self.token_embeddings[:, :self.model.config.hidden_size // 2],s_rep], dim=0)logits = torch.matmul(query_start, candidate_reps.t())logits /= self.args['temp']# build the padding mask for query sidequery_padding_mask = ids_mask[:, :-1].reshape(-1).to(torch.bool)# build the padding mask: 1 for valid and 0 for maskattention_mask = (dids_mask.reshape(1, -1).to(torch.bool)).to(torch.long)padding_mask = torch.ones_like(logits).to(torch.long)# Santiy check overpadding_mask[:, self.vocab_size:] = attention_mask# build the position mask: 1 for valid and 0 for maskpos_mask = batch['pos_mask']start_labels, end_labels = batch['start_labels'][:, 1:].reshape(-1), batch['end_labels'][:, 1:].reshape(-1)position_mask = torch.ones_like(logits).to(torch.long)query_pos = start_labels > self.vocab_size# ignore the padding maskposition_mask[query_pos, self.vocab_size:] = pos_maskassert padding_mask.shape == position_mask.shape# overall maskoverall_mask = padding_mask * position_mask## remove the position mask# overall_mask = padding_masknew_logits = torch.where(overall_mask.to(torch.bool), logits, torch.tensor(-1e4).to(torch.half).cuda())mask = torch.zeros_like(new_logits)mask[range(len(new_logits)), start_labels] = 1.loss_ = F.log_softmax(new_logits[query_padding_mask], dim=-1) * mask[query_padding_mask]loss_1 = (-loss_.sum(dim=-1)).mean()## split the token accuaracy and phrase accuracyphrase_indexes = start_labels > self.vocab_sizephrase_indexes_ = phrase_indexes & query_padding_maskphrase_start_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == start_labels[phrase_indexes_]phrase_start_acc = phrase_start_acc.to(torch.float).mean().item()phrase_indexes_ = ~phrase_indexes & query_padding_masktoken_start_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == start_labels[phrase_indexes_]token_start_acc = token_start_acc.to(torch.float).mean().item()# training the representations of the end tokenscandidate_reps = torch.cat([self.token_embeddings[:, self.model.config.hidden_size // 2:],e_rep], dim=0)logits = torch.matmul(query_end, candidate_reps.t()) # [Q, B*] logits /= self.args['temp']new_logits = torch.where(overall_mask.to(torch.bool), logits, torch.tensor(-1e4).to(torch.half).cuda())mask = torch.zeros_like(new_logits)mask[range(len(new_logits)), end_labels] = 1.loss_ = F.log_softmax(new_logits[query_padding_mask], dim=-1) * mask[query_padding_mask]loss_2 = (-loss_.sum(dim=-1)).mean()# split the phrase and token accuracyphrase_indexes = end_labels > self.vocab_sizephrase_indexes_ = phrase_indexes & query_padding_maskphrase_end_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == end_labels[phrase_indexes_]phrase_end_acc = phrase_end_acc.to(torch.float).mean().item()phrase_indexes_ = ~phrase_indexes & query_padding_masktoken_end_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == end_labels[phrase_indexes_]token_end_acc = token_end_acc.to(torch.float).mean().item()return (loss_0, # token lossloss_1, # token-head lossloss_2, # token-tail lossacc_0, # token accuracyphrase_start_acc,phrase_end_acc,token_start_acc,token_end_acc)