平台开发的基本流程域名查询seo
理解线程池 C++
文章目录
- 理解线程池 C++
- 程序源码
- 知识点
- emplace_back 和 push_back有什么区别?
- 互斥锁 mutex
- condition_variable
- std::move()函数
- bind()函数
- join 函数
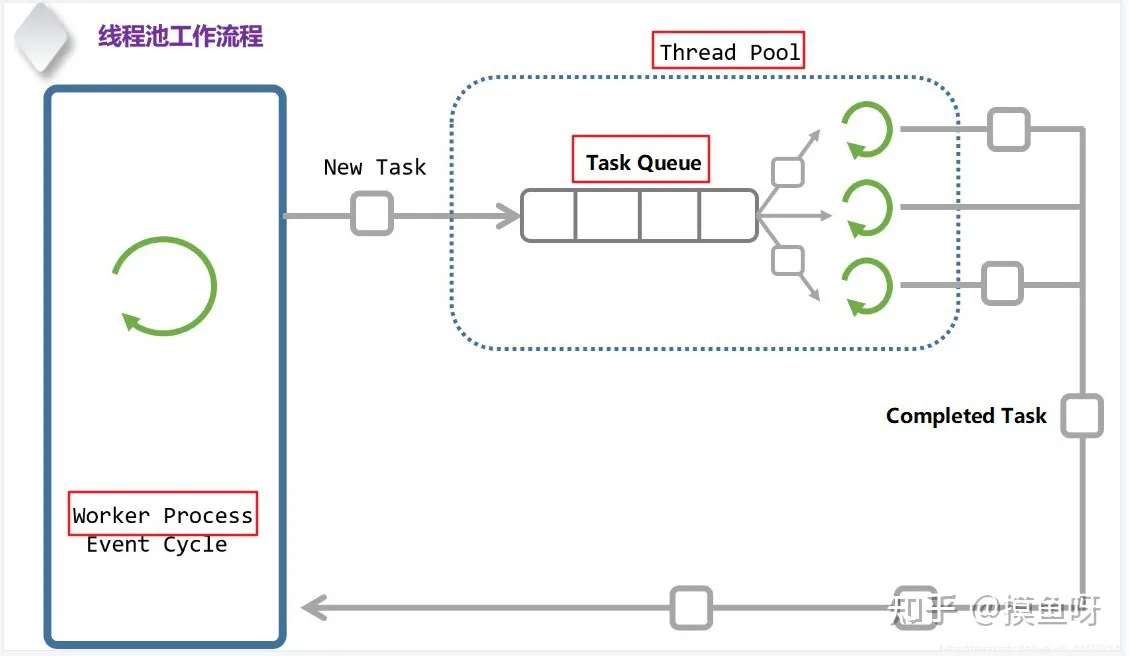
线程池的原理就是管理一个任务队列和一个工作线程队列。
工作线程不断的从任务队列取任务,然后执行。如果没有任务就等待新任务的到来。添加新任务的时候先添加到任务队列,然后通知任意(条件变量notify_one/notify_all)一个线程有新的任务来了。
优势包括:
-
资源管理:线程池有效地管理线程的创建、销毁和重用,避免了频繁创建和销毁线程的开销,节省了系统资源。
-
减少线程创建时间:线程创建和销毁是开销较大的操作。线程池在初始化时创建一组线程,并将它们保持在就绪状态,从而在需要时可以快速执行任务,而不必每次都重新创建线程。
-
任务队列:线程池通常与任务队列结合使用,任务可以被提交到队列中,线程池中的线程会按照队列中任务的顺序依次执行,确保了任务的有序执行。
-
限制并发数:线程池可以限制并发执行的任务数量,以避免系统资源过度占用,提高系统稳定性。
-
节省内存:线程池的线程可以被重复使用,避免了频繁创建线程的内存占用。
应用场景包括:
服务器应用:线程池在服务器应用中常用来处理客户端请求。当服务器需要处理大量的连接请求时,线程池可以有效地复用线程,提高服务器性能。
I/O密集型任务:线程池适用于I/O密集型任务,如文件读写、网络通信等。在这些情况下,线程可以在I/O操作等待时执行其他任务,提高了系统的效率。
并行计算:线程池可以用于并行计算,将任务拆分为多个子任务,由线程池中的线程并行执行,加速计算过程。
定时任务:线程池可用于执行定时任务,例如定期备份数据、清理日志等。
多任务并行处理:当需要处理多个任务,但不想为每个任务创建一个线程时,线程池是一种有效的方式。它可以控制并发任务的数量,从而避免系统过度负载。
程序源码
class ThreadPool {public:// 构造函数,传入线程数ThreadPool(size_t);template <class F, class... Args>auto enqueue(F&& f, Args&&... args)-> std::future<typename std::result_of<F(Args...)>::type>;~ThreadPool();private:// 线程组std::vector<std::thread> workers;// 任务队列std::queue<std::function<void()> > tasks;// synchronizationstd::mutex queue_mutex; //互斥锁std::condition_variable condition;//条件变量bool stop;//停止标志
};// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool(size_t threads) : stop(false) {for (size_t i = 0; i < threads; ++i)//thread 禁用了拷贝构造和赋值运算,因此这边最好用emplace_backworkers.emplace_back([this] {for (;;) { //死循环的作用是一直让线程执行任务直至结束std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);// 如果线程终止了 或者 任务队列不为空 就等待this->condition.wait(lock, [this] { return this->stop || !this->tasks.empty(); });// 如果线程终止了 且 任务队列空了 函数结束if (this->stop && this->tasks.empty()) return;task = std::move(this->tasks.front());this->tasks.pop();}task();}});
}// add new work item to the pool
template <class F, class... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)-> std::future<typename std::result_of<F(Args...)>::type> {using return_type = typename std::result_of<F(Args...)>::type;auto task = std::make_shared<std::packaged_task<return_type()> >(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);// don't allow enqueueing after stopping the poolif (stop) throw std::runtime_error("enqueue on stopped ThreadPool");tasks.emplace([task]() { (*task)(); });}condition.notify_one();return res;
}// the destructor joins all threads
inline ThreadPool::~ThreadPool() {{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for (std::thread& worker : workers) worker.join();
}
知识点
emplace_back 和 push_back有什么区别?
《c++ primer》书里说明:
1.当调用push或insert成员函数时,我们将元素类型的对象传递给它们,这些对象被拷贝到容器中。而当我们调用一个emplace成员函数时,则是将参数传递给元素类型的构造函数。emplace成员使用这些参数在容器管理的内存空间中直接构造元素。
2.其中对emplace_back的调用和第二个push_back调用都会创建新的Sales_data对象。在调用emplace_back时,会在容器管理的内存空间中直接创建对象。而调用push_back则会创建一个局部临时对象
3.标准库容器的emplace_back成员是一个可变参数成员模板,而push_back只能传入单个参数

总结就是emplace_back资源消耗更小,不会创建临时对象,同事可以进行多参数的传入,应用于像vector中T有多个参数的场景。
互斥锁 mutex
一种同步原语,用于多线程管理,确保临界资源只有一个线程访问,其中mtx.lock()表示上锁,mtx.unlock()表示解锁。上述线程池中为什么没有unlock呢?因 std::unique_lockstd::mutex 这个智能指针在退出{}代码块之后就会自动销毁。
condition_variable
condition_variable 条件变量是一种对象,能够阻止调用线程,直到收到通知才能恢复。一般配合 unique_lock 一起使用。当其中一个等待函数被调用时,线程保持阻塞状态,直到被另一个线程唤醒,该线程在同一condition_variable对象上调用通知函数。
//通过notify_one或者notify_all进行唤醒
void wait (unique_lock<mutex>& lck);
//只有pred返回false时才会阻塞,pred变为true时才能被唤醒
void wait (unique_lock<mutex>& lck, Predicate pred);
std::move()函数
左值变右值,可以参考C++ 左值右值以及std::move函数解释
bind()函数
每个参数可以绑定到一个值或者作为占位符:
- 如果绑定到一个值,调用返回的函数对象将总是使用该值作为参数。
- 如果作为占位符,调用返回的函数对象将转发传递给调用的参数(由占位符指定顺序号)
double my_divide (double x, double y) {return x/y;}int main () {auto fn_five = std::bind (my_divide,10,2); // returns 10/2std::cout << fn_five() << '\n'; // 5auto fn_half = std::bind (my_divide,_1,2); // returns x/2std::cout << fn_half(10) << '\n'; // 5auto fn_invert = std::bind (my_divide,_2,_1); // returns y/xstd::cout << fn_invert(10,2) << '\n'; // 0.2auto fn_rounding = std::bind<int> (my_divide,_1,_2); // returns int(x/y)std::cout << fn_rounding(10,3) << '\n'; // 3
}
join 函数
C++中用于线程同步的一个方法,它通常用于等待一个线程的执行完成。当你创建一个线程并希望等待它完成执行。
int main() {std::thread t1(foo);std::thread t2(bar);t1.join(); // 主线程等待 t1 完成t2.join(); // 主线程等待 t2 完成std::cout << "Both threads have finished!" << std::endl;return 0;
}