带引导页的网站seo如何优化图片
目录
前言
堆
堆的常用操作
堆的实现(大根堆)
1. 堆的存储与表示
2. 访问堆顶元素
3. 元素入堆
4. 堆顶元素出堆
Top-k 问题
方法一:遍历选择
方法二:排序
方法三:堆
总结
前言
秋招复习之堆。
堆
「堆 heap」是一种满足特定条件的完全二叉树,主要可分为两种类型,如图所示。
- 「小顶堆 min heap」:任意节点的值 ≤ 其子节点的值。
- 「大顶堆 max heap」:任意节点的值 ≥ 其子节点的值。

堆作为完全二叉树的一个特例,具有以下特性。
- 最底层节点靠左填充,其他层的节点都被填满。
- 我们将二叉树的根节点称为“堆顶”,将底层最靠右的节点称为“堆底”。
- 对于大顶堆(小顶堆),堆顶元素(根节点)的值是最大(最小)的。
堆的常用操作
许多编程语言提供的是「优先队列 priority queue」,这是一种抽象的数据结构,定义为具有优先级排序的队列。
实际上,堆通常用于实现优先队列,大顶堆相当于元素按从大到小的顺序出队的优先队列。从使用角度来看,我们可以将“优先队列”和“堆”看作等价的数据结构。

在实际应用中,我们可以直接使用编程语言提供的堆类(或优先队列类)。
类似于排序算法中的“从小到大排列”和“从大到小排列”,我们可以通过设置一个 flag 或修改 Comparator 实现“小顶堆”与“大顶堆”之间的转换。代码如下所示:
/* 初始化堆 */
// 初始化小顶堆
Queue<Integer> minHeap = new PriorityQueue<>();
// 初始化大顶堆(使用 lambda 表达式修改 Comparator 即可)
Queue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);/* 元素入堆 */
maxHeap.offer(1);
maxHeap.offer(3);
maxHeap.offer(2);
maxHeap.offer(5);
maxHeap.offer(4);/* 获取堆顶元素 */
int peek = maxHeap.peek(); // 5/* 堆顶元素出堆 */
// 出堆元素会形成一个从大到小的序列
peek = maxHeap.poll(); // 5
peek = maxHeap.poll(); // 4
peek = maxHeap.poll(); // 3
peek = maxHeap.poll(); // 2
peek = maxHeap.poll(); // 1/* 获取堆大小 */
int size = maxHeap.size();/* 判断堆是否为空 */
boolean isEmpty = maxHeap.isEmpty();/* 输入列表并建堆 */
minHeap = new PriorityQueue<>(Arrays.asList(1, 3, 2, 5, 4));/* 初始化堆 */
// 初始化小顶堆
priority_queue<int, vector<int>, greater<int>> minHeap;
// 初始化大顶堆
priority_queue<int, vector<int>, less<int>> maxHeap;/* 元素入堆 */
maxHeap.push(1);
maxHeap.push(3);
maxHeap.push(2);
maxHeap.push(5);
maxHeap.push(4);/* 获取堆顶元素 */
int peek = maxHeap.top(); // 5/* 堆顶元素出堆 */
// 出堆元素会形成一个从大到小的序列
maxHeap.pop(); // 5
maxHeap.pop(); // 4
maxHeap.pop(); // 3
maxHeap.pop(); // 2
maxHeap.pop(); // 1/* 获取堆大小 */
int size = maxHeap.size();/* 判断堆是否为空 */
bool isEmpty = maxHeap.empty();/* 输入列表并建堆 */
vector<int> input{1, 3, 2, 5, 4};
priority_queue<int, vector<int>, greater<int>> minHeap(input.begin(), input.end());堆的实现(大根堆)
1. 堆的存储与表示
完全二叉树非常适合用数组来表示。由于堆正是一种完全二叉树,因此我们将采用数组来存储堆。

将索引映射公式封装成函数
/* 获取左子节点的索引 */
int left(int i) {return 2 * i + 1;
}/* 获取右子节点的索引 */
int right(int i) {return 2 * i + 2;
}/* 获取父节点的索引 */
int parent(int i) {return (i - 1) / 2; // 向下整除
}/* 获取左子节点的索引 */
int left(int i) {return 2 * i + 1;
}/* 获取右子节点的索引 */
int right(int i) {return 2 * i + 2;
}/* 获取父节点的索引 */
int parent(int i) {return (i - 1) / 2; // 向下整除
}2. 访问堆顶元素
/* 访问堆顶元素 */
int peek() {return maxHeap.get(0);
}/* 访问堆顶元素 */
int peek() {return maxHeap[0];
}3. 元素入堆
给定元素 val ,我们首先将其添加到堆底。添加之后,由于 val 可能大于堆中其他元素,堆的成立条件可能已被破坏,因此需要修复从插入节点到根节点的路径上的各个节点,这个操作被称为「堆化 heapify」。
考虑从入堆节点开始,从底至顶执行堆化。如图所示,我们比较插入节点与其父节点的值,如果插入节点更大,则将它们交换。然后继续执行此操作,从底至顶修复堆中的各个节点,直至越过根节点或遇到无须交换的节点时结束。(就是一直和父比较,大就换)

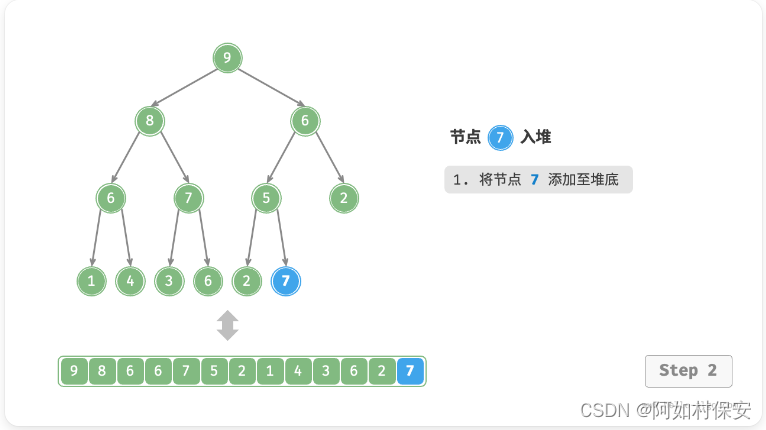
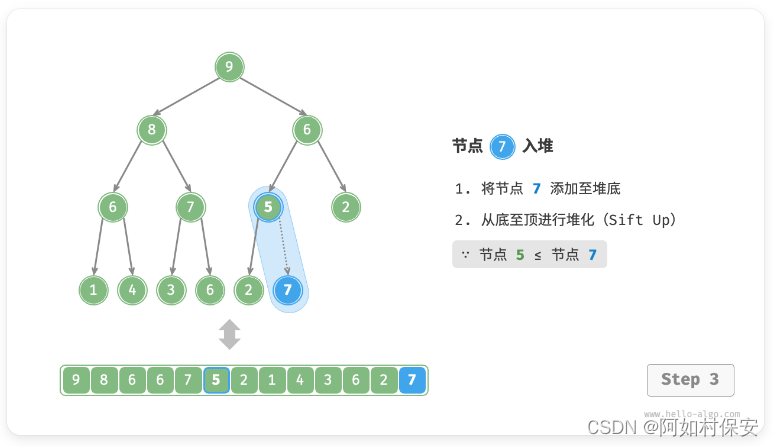

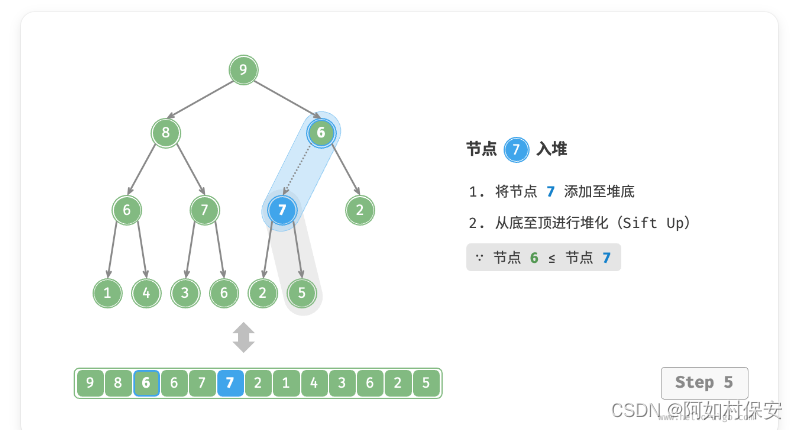

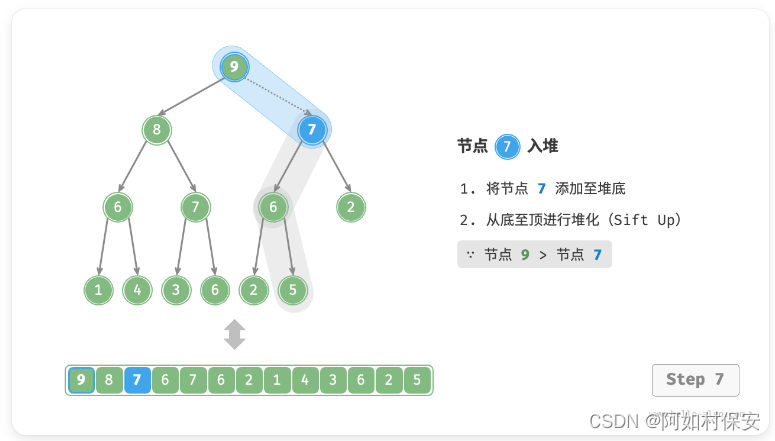


设节点总数为 n ,则树的高度为 O(logN) 。由此可知,堆化操作的循环轮数最多为 O(logN) ,元素入堆操作的时间复杂度为 O(logN) 。
/* 元素入堆 */
void push(int val) {// 添加节点maxHeap.add(val);// 从底至顶堆化siftUp(size() - 1);
}/* 从节点 i 开始,从底至顶堆化 */
void siftUp(int i) {while (true) {// 获取节点 i 的父节点int p = parent(i);// 当“越过根节点”或“节点无须修复”时,结束堆化if (p < 0 || maxHeap.get(i) <= maxHeap.get(p))break;// 交换两节点swap(i, p);// 循环向上堆化i = p;}
}/* 元素入堆 */
void push(int val) {// 添加节点maxHeap.push_back(val);// 从底至顶堆化siftUp(size() - 1);
}/* 从节点 i 开始,从底至顶堆化 */
void siftUp(int i) {while (true) {// 获取节点 i 的父节点int p = parent(i);// 当“越过根节点”或“节点无须修复”时,结束堆化if (p < 0 || maxHeap[i] <= maxHeap[p])break;// 交换两节点swap(maxHeap[i], maxHeap[p]);// 循环向上堆化i = p;}
}4. 堆顶元素出堆
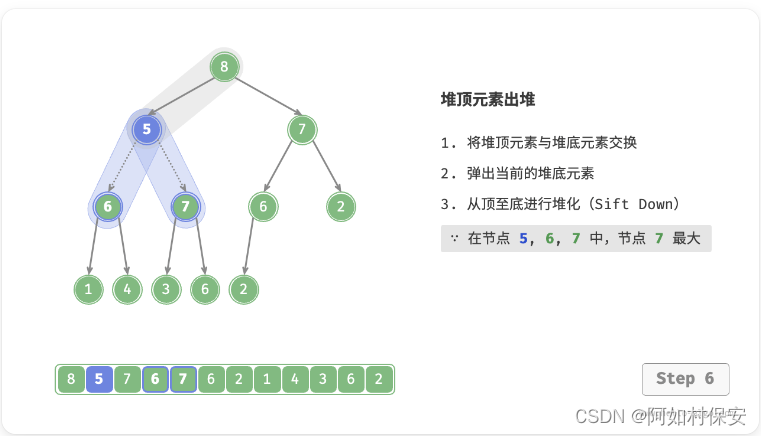
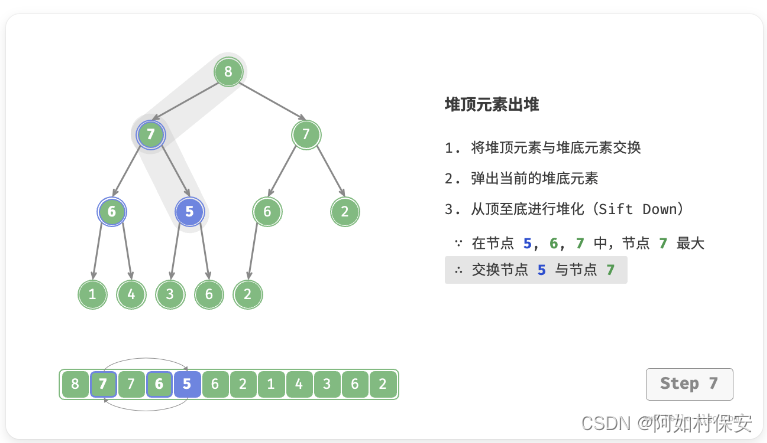
堆顶元素是二叉树的根节点,即列表首元素。如果我们直接从列表中删除首元素,那么二叉树中所有节点的索引都会发生变化,这将使得后续使用堆化进行修复变得困难。为了尽量减少元素索引的变动,我们采用以下操作步骤。
- 交换堆顶元素与堆底元素(交换根节点与最右叶节点)。
- 交换完成后,将堆底从列表中删除(注意,由于已经交换,因此实际上删除的是原来的堆顶元素)。
- 从根节点开始,从顶至底执行堆化。
如图所示,“从顶至底堆化”的操作方向与“从底至顶堆化”相反,我们将根节点的值与其两个子节点的值进行比较,将最大的子节点与根节点交换。然后循环执行此操作,直到越过叶节点或遇到无须交换的节点时结束。








与元素入堆操作相似,堆顶元素出堆操作的时间复杂度也为 O(logn) 。代码如下所示:
/* 元素出堆 */
int pop() {// 判空处理if (isEmpty())throw new IndexOutOfBoundsException();// 交换根节点与最右叶节点(交换首元素与尾元素)swap(0, size() - 1);// 删除节点int val = maxHeap.remove(size() - 1);// 从顶至底堆化siftDown(0);// 返回堆顶元素return val;
}/* 从节点 i 开始,从顶至底堆化 */
void siftDown(int i) {while (true) {// 判断节点 i, l, r 中值最大的节点,记为 maint l = left(i), r = right(i), ma = i;if (l < size() && maxHeap.get(l) > maxHeap.get(ma))ma = l;if (r < size() && maxHeap.get(r) > maxHeap.get(ma))ma = r;// 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出if (ma == i)break;// 交换两节点swap(i, ma);// 循环向下堆化i = ma;}
}/* 元素出堆 */
void pop() {// 判空处理if (isEmpty()) {throw out_of_range("堆为空");}// 交换根节点与最右叶节点(交换首元素与尾元素)swap(maxHeap[0], maxHeap[size() - 1]);// 删除节点maxHeap.pop_back();// 从顶至底堆化siftDown(0);
}/* 从节点 i 开始,从顶至底堆化 */
void siftDown(int i) {while (true) {// 判断节点 i, l, r 中值最大的节点,记为 maint l = left(i), r = right(i), ma = i;if (l < size() && maxHeap[l] > maxHeap[ma])ma = l;if (r < size() && maxHeap[r] > maxHeap[ma])ma = r;// 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出if (ma == i)break;swap(maxHeap[i], maxHeap[ma]);// 循环向下堆化i = ma;}
}Top-k 问题
Q:给定一个长度为 n的无序数组 nums ,请返回数组中最大的 k个元素。
方法一:遍历选择
其时间复杂度趋向于O(n2) ,非常耗时。

当 k=n 时,可以得到完整的有序序列,此时等价于“选择排序”算法。
方法二:排序
如图所示,我们可以先对数组 nums 进行排序,再返回最右边的 k 个元素,时间复杂度为 O(nlogn) 。
显然,该方法“超额”完成任务了,因为我们只需找出最大的k个元素即可,而不需要排序其他元素。

方法三:堆
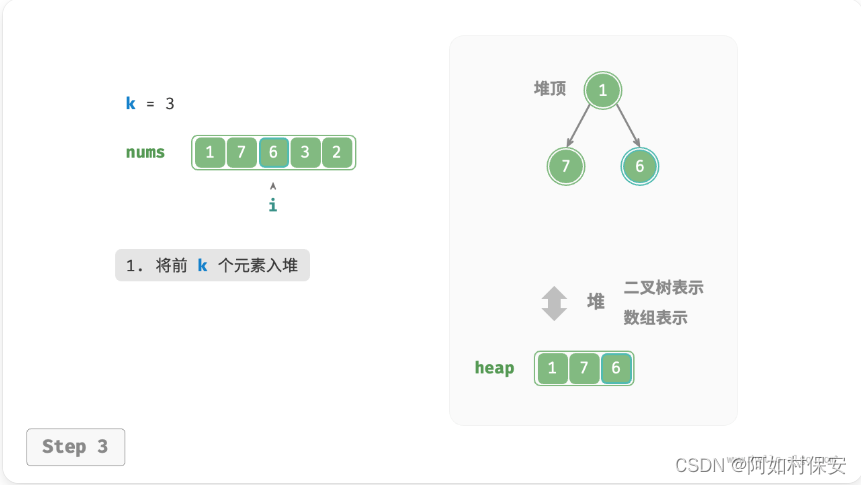
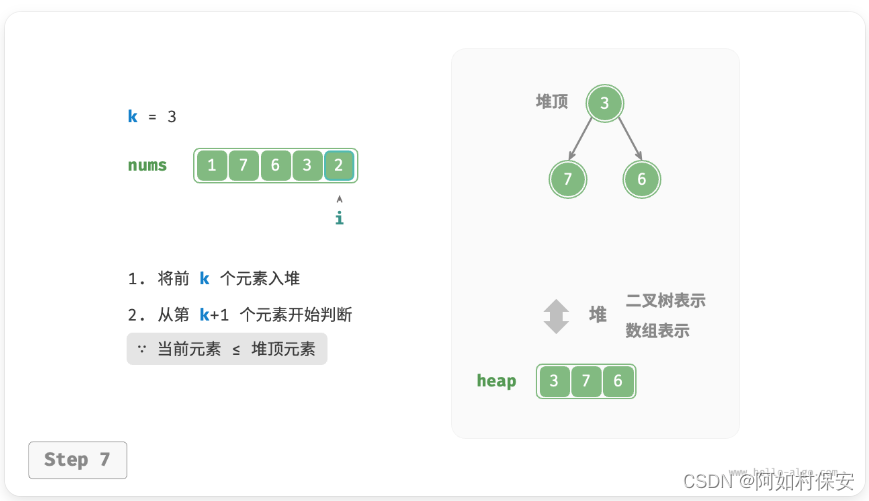
可以基于堆更加高效地解决 Top-k 问题,流程如图所示。
- 初始化一个小顶堆,其堆顶元素最小。
- 先将数组的前 k 个元素依次入堆。
- 从第 k+1 个元素开始,若当前元素大于堆顶元素,则将堆顶元素出堆,并将当前元素入堆。
- 遍历完成后,堆中保存的就是最大k 个元素。
天才!!!







/* 基于堆查找数组中最大的 k 个元素 */
Queue<Integer> topKHeap(int[] nums, int k) {// 初始化小顶堆Queue<Integer> heap = new PriorityQueue<Integer>();// 将数组的前 k 个元素入堆for (int i = 0; i < k; i++) {heap.offer(nums[i]);}// 从第 k+1 个元素开始,保持堆的长度为 kfor (int i = k; i < nums.length; i++) {// 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆if (nums[i] > heap.peek()) {heap.poll();heap.offer(nums[i]);}}return heap;
}/* 基于堆查找数组中最大的 k 个元素 */
priority_queue<int, vector<int>, greater<int>> topKHeap(vector<int> &nums, int k) {// 初始化小顶堆priority_queue<int, vector<int>, greater<int>> heap;// 将数组的前 k 个元素入堆for (int i = 0; i < k; i++) {heap.push(nums[i]);}// 从第 k+1 个元素开始,保持堆的长度为 kfor (int i = k; i < nums.size(); i++) {// 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆if (nums[i] > heap.top()) {heap.pop();heap.push(nums[i]);}}return heap;
}总共执行了 n轮入堆和出堆,堆的最大长度为 k ,因此时间复杂度为 O(nlogk) 。该方法的效率很高,当 k 较小时,时间复杂度趋向 O(n) ;当 n 较大时,时间复杂度不会超过 O(nlogn) 。
另外,该方法适用于动态数据流的使用场景。在不断加入数据时,我们可以持续维护堆内的元素,从而实现最大的 k个元素的动态更新。
总结
- 堆是一棵完全二叉树,根据成立条件可分为大顶堆和小顶堆。大(小)顶堆的堆顶元素是最大(小)的。
- 优先队列的定义是具有出队优先级的队列,通常使用堆来实现。
- 堆的常用操作及其对应的时间复杂度包括:元素入堆 O(logn)、堆顶元素出堆 O(logn) 和访问堆顶元素 O(1) 等。
- 完全二叉树非常适合用数组表示,因此我们通常使用数组来存储堆。
- 堆化操作用于维护堆的性质,在入堆和出堆操作中都会用到。
- 输入 n 个元素并建堆的时间复杂度可以优化至 O(n) ,非常高效。
- Top-k 是一个经典算法问题,可以使用堆数据结构高效解决,时间复杂度为 O(nlogK) 。
