泉州网页模板建站高佣金app软件推广平台
微信公众号“dotNET跨平台”的文章《c#实现图片文体提取》(参考文献3)介绍了C#图像文本识别模块Tesseract,后者是tesseract-ocr(参考文献2) 的C#封装版本,目前版本为5.2,关于Tesseract的详细介绍请见参考文献1和5,本文主要测试Tesseract模块的基本用法。
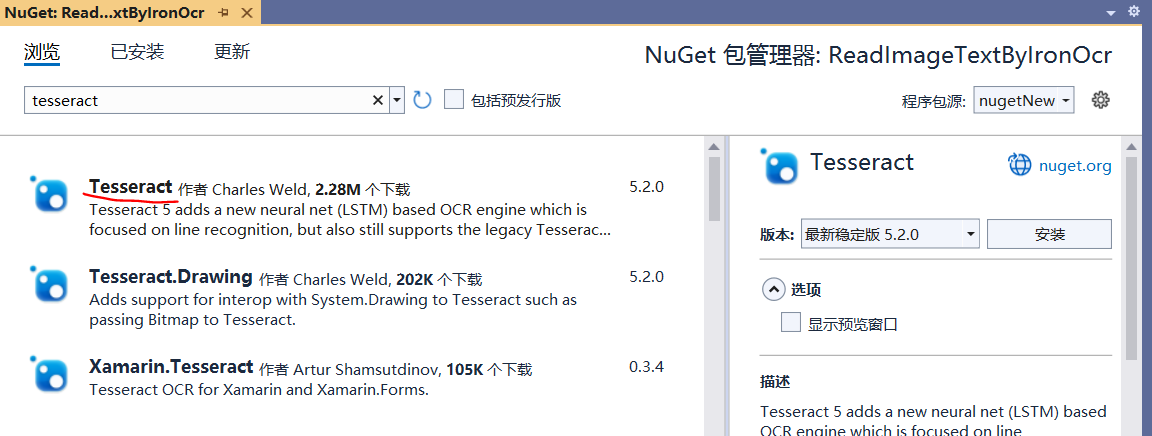
之前测试过IronOCR和PaddleSharp,本文复用IronOCR的测试代码,在NuGet包管理器中安装Tesseract包,如下图所示:
主要调用TesseractEngine类加载语言包、设置识别语言等,其构造函数原型如下所示。其中输入参数中的datapath指定语言包路径,安装NuGet包时不会安装语言包,需要单独下载,可以在参考文献2或者Tesseract官网中下载,language参数指定识别语言,语言名称对应语言包中文件名的开头部分(如chi_sim.traineddata对应的简体中文语言为chi_sim,eng.traineddata对应的英文为eng),engineMode参数对应的是识别引擎类型,其可选值如下所示。
public TesseractEngine(string datapath, string language, EngineMode engineMode)public enum EngineMode
{//// 摘要:// Only the legacy tesseract OCR engine is used.TesseractOnly,//// 摘要:// Only the new LSTM-based OCR engine is used.LstmOnly,//// 摘要:// Both the legacy and new LSTM based OCR engine is used.TesseractAndLstm,//// 摘要:// The default OCR engine is used (currently LSTM-ased OCR engine).Default
}
调用TesseractEngine类中的Process函数识别图片内容,其函数原型如下,第一个参数指定待识别的图片(Pix类为Tesseract模块自带类,可以调用Pix.LoadFromFile函数生成实例对象),第二个参数为图片处理方式,取值见下面代码所示。Process函数返回Page类实例对象,从中可以获取识别结果。
public Page Process(Pix image, PageSegMode? pageSegMode = null)public enum PageSegMode
{//// 摘要:// Orientation and script detection (OSD) only.OsdOnly,//// 摘要:// Automatic page sementation with orientantion and script detection (OSD).AutoOsd,//// 摘要:// Automatic page segmentation, but no OSD, or OCR.AutoOnly,//// 摘要:// Fully automatic page segmentation, but no OSD.Auto,//// 摘要:// Assume a single column of text of variable sizes.SingleColumn,//// 摘要:// Assume a single uniform block of vertically aligned text.SingleBlockVertText,//// 摘要:// Assume a single uniform block of text.SingleBlock,//// 摘要:// Treat the image as a single text line.SingleLine,//// 摘要:// Treat the image as a single word.SingleWord,//// 摘要:// Treat the image as a single word in a circle.CircleWord,//// 摘要:// Treat the image as a single character.SingleChar,SparseText,//// 摘要:// Sparse text with orientation and script detection.SparseTextOsd,//// 摘要:// Treat the image as a single text line, bypassing hacks that are specific to Tesseract.RawLine,//// 摘要:// Number of enum entries.Count
}
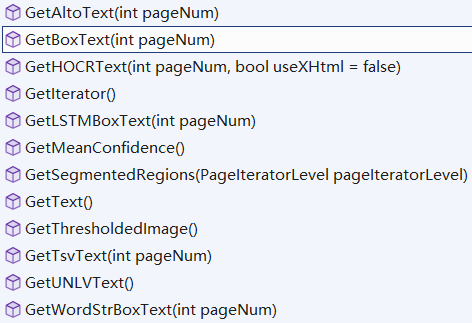
Page类中通过调用GetText函数获取图片中所有识别出的汇总的文本,其还支持如下函数获取文本内容或文本区域信息,后续会继续学习其用法。
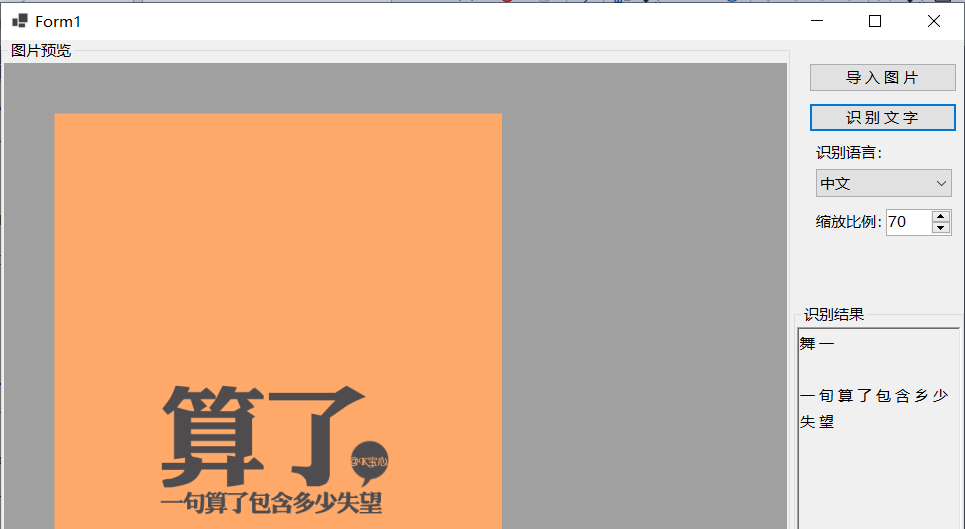
采用Tesseract模块的基本用法得到的图片文字识别效果如下所示。大部分可以识别出来,但是识别带车牌的图片不管是Tesseract,还是之前的IronOCR和PaddleSharp,效果都比较差,不清楚是设置的问题,还是语言包用得不对。
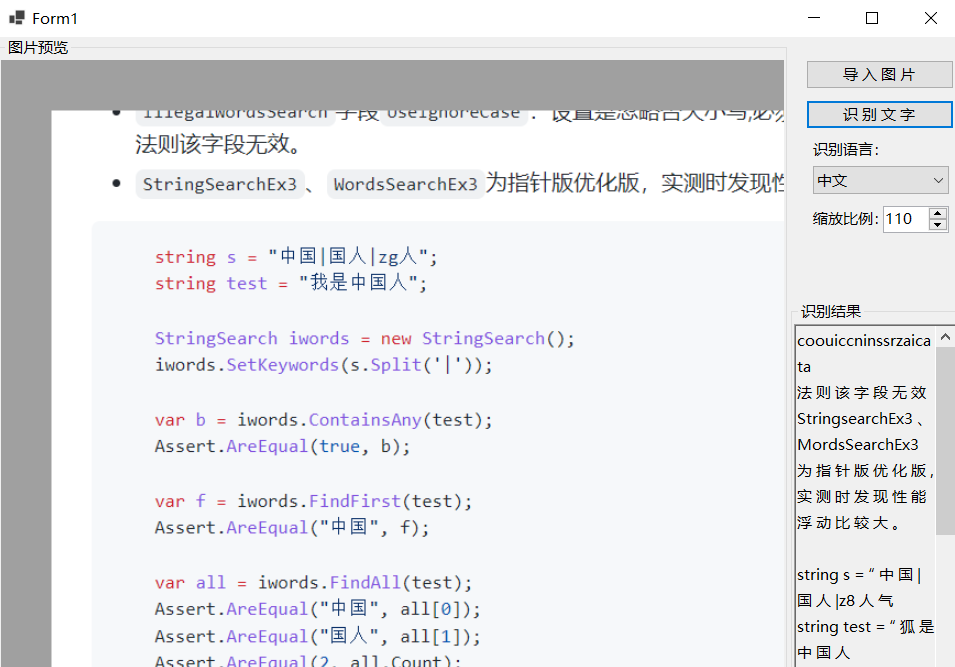
参考文献
[1]https://github.com/charlesw/tesseract/
[2]https://github.com/tesseract-ocr/tesseract/tree/main/src
[3]https://www.sohu.com/a/722507167_121124363
[4]https://github.com/tesseract-ocr/tessdata/
[5]https://zhuanlan.zhihu.com/p/578700314