网站长春网站建设sem代运营
汇编语言中的函数(或过程)是指一段可以被调用和执行的代码块;它们用于组织和重用代码,并使程序结构更加清晰;由于汇编语言没有高层次语言的语法糖,编写和调用函数涉及直接的堆栈操作和寄存器管理;以下详细介绍汇编函数的定义、调用、参数传递、返回值处理及一些最佳实践。
汇编语言中的函数调用和高层语言类似,但需要手动处理参数传递、堆栈管理和返回值。
函数的定义
函数在汇编中被定义为一个带有标签的代码块,通常使用 proc 和 endp 关键字来定义函数的开始和结束。
my_function proc; 函数体
my_function endp示例:计算两个整数的和
assume cs:code
code segment//函数readd proc add si,dimov ax,siretreadd endp
start:mov si,5 mov di,6//函数调用call readd//终止程序并返回dosmov ax,4c00hint 21h
code ends
end start这段汇编代码展示了一个简单的程序,其中包含一个名为 readd 的函数,用于将两个寄存器 SI 和 DI 中的值相加,并将结果存储在 AX 寄存器中。然后在程序的开始部分调用该函数,最后终止程序。
start:为程序的入口点,mov si, 5:将立即数 5 存储到 SI 寄存器中;mov di, 6:将立即数 6 存储到 DI 寄存器中;call readd:调用 readd 函数;调用 readd 函数后,SI 中的值变为 11(16进制B),并且 AX 也将包含 B。
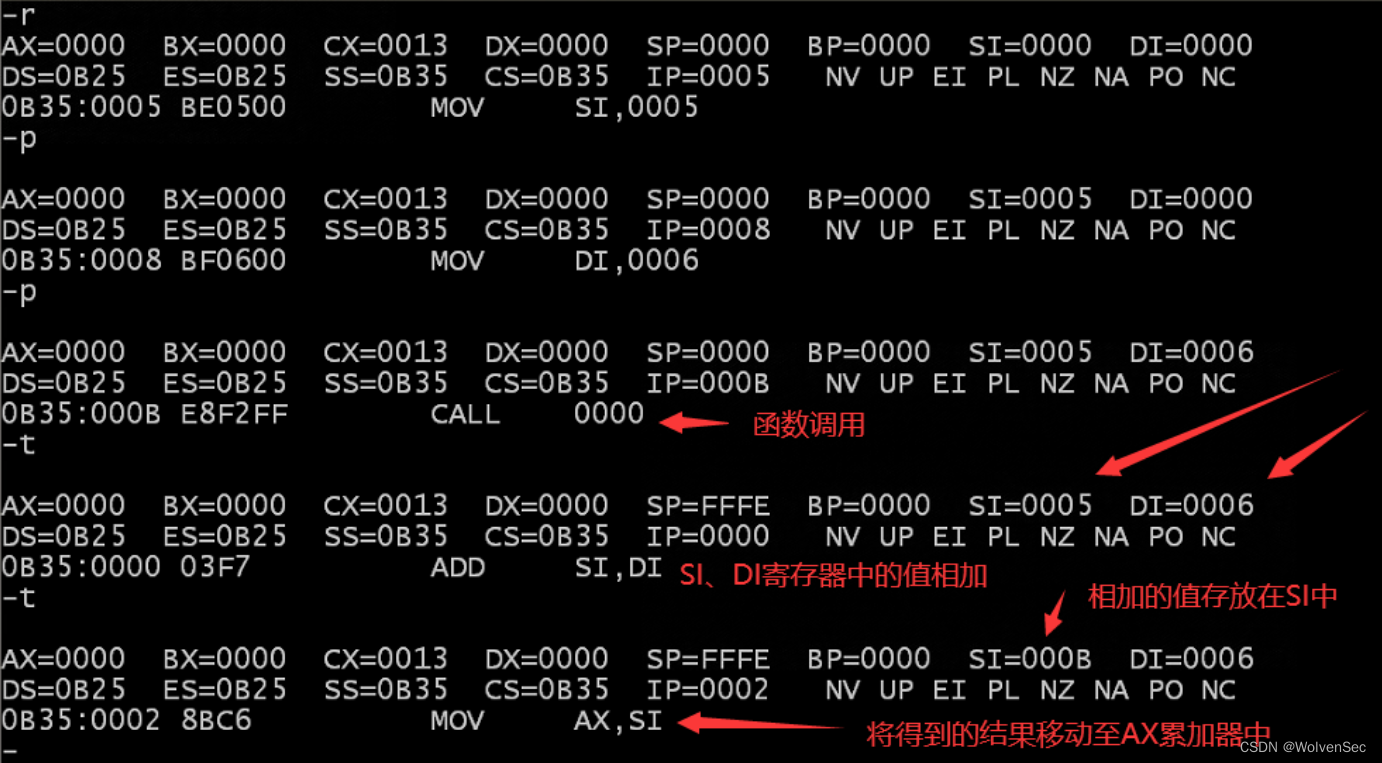

上述函数是通过寄存器传递参数;在这个示例中,参数 5 和 6 被分别存储在寄存器 SI 和 DI 中,然后调用 readd 函数进行处理。
start:mov si,5 ; 将 5 存储到 SI 寄存器中mov di,6 ; 将 6 存储到 DI 寄存器中call readd ; 调用 readd 函数通过寄存器传递参数虽然有速度快、效率高的优点,但是由于寄存器数量有限,只适合参数数量较少的情况。
堆栈传参
堆栈传参相对于寄存器传参是一个更通用和灵活的方式,尤其是在需要传递大量参数、处理复杂调用关系或编写递归函数时可以使用这种传参方式。
1.堆栈的基本结构
要了解堆栈传参首先我们需要理解堆栈帧(stack frame)的结构及其在函数调用中的变化;堆栈是一个后进先出(LIFO)数据结构,用于存储函数调用的返回地址、局部变量、参数等;当一个函数被调用时,会创建一个新的堆栈帧,用于存储该函数的局部变量和传递的参数。堆栈帧通常包括以下内容:
调用函数的返回地址 保存的基指针(BP) 函数参数 局部变量
下面是一个简单的堆栈帧结构示意图:
(高地址)High Address、+----------------+| 局部变量1 |+----------------+| 局部变量2 |+----------------+| ... |+----------------+| 参数1 |+----------------+| 参数2 |+----------------+| 参数3 |+----------------+| ... |+----------------+| 函数的返回地址 | <- 堆栈顶 (SP)+----------------+| 保存的基指针 | <- 当前基指针 (BP)+----------------+
(低地址)Low Address
堆栈从高地址向低地址增长,SP 指向堆栈顶部,BP 用于定位局部变量和参数的位置。
以下是一个简单的堆栈传参示例:
assume cs:code
code segmentadd_numbers procpush bp mov bp, sp mov ax, [bp+4] //参数取出 add ax, [bp+6] //结果存放在ax中pop bp retadd_numbers endp
start:mov ax,10mov bx,5//参数传入push ax ; 将ax寄存器中的值压入栈中push bx ; 将bx寄存器中的值压入栈中call add_numbers ;函数调用add sp, 4 mov ax, 4C00hint 21h
code ends
end start①add_numbers proc 和 add_numbers endp:定义了一个名为add_numbers的过程,该过程用于计算两个数的和。
push bp:保存当前函数调用前的基址指针值。
保存当前函数调用前的基址指针值通常是为了确保在函数执行期间能够正确访问调用该函数的上一级函数的栈帧信息。这是因为函数调用时,会产生一个新的栈帧,新的栈帧通常需要访问上一级函数的栈帧信息,比如参数、局部变量和返回地址等。
mov bp, sp:将栈顶指针赋值给基址指针,以便访问函数参数和局部变量。
mov ax, [bp+4]:将第一个参数(位于偏移量为4的位置)加载到寄存器ax中。
add ax, [bp+6]:将第二个参数(位于偏移量为6的位置)加到寄存器ax中。
pop bp:恢复基址指针的原始值。
ret:函数返回。
②start:程序的入口点。
mov ax,10:将常数10加载到寄存器ax中。
mov bx,5:将常数5加载到寄存器bx中。
push ax 和 push bx:将ax和bx中的值分别推送到堆栈中,作为add_numbers函数的参数。
call add_numbers:调用add_numbers函数。
add sp, 4:将堆栈指针移动4个字节,以清除函数调用时推送的参数。
mov ax, 4C00h:将退出程序的DOS功能号加载到寄存器ax中。
int 21h:调用DOS中断,终止程序。
解释了上述的汇编程序的后,我们将目光聚焦到函数参数传递中。
2. 堆栈帧的创建和销毁
此处补充:参数的压栈顺序是由调用约定(calling convention)决定的。在一些常见的调用约定中,如 cdecl、stdcall 等,参数的压栈顺序一般是从右往左的,即先压入的参数在内存中的地址更高,后压入的参数在内存中的地址更低。
假设我们有一个调用 add_numbers 函数的过程,如下所示:
start:mov ax,10mov bx,5push ax ; 将ax寄存器中的值压入栈中push bx ; 将bx寄存器中的值压入栈中call add_numbers ; 调用 add_numbers 函数add sp, 4 ; 清理堆栈函数调用前,堆栈帧的图示
函数调用前堆栈的内容(从高地址到低地址):
high
|-------------|
| 参数 10 |
|-------------|
| 参数 5 |<-- SP (堆栈指针)
|-------------|
low执行call add_numbers指令后,即函数调用后,堆栈帧的图示:
|-------------|
| 参数 10 |
|-------------|
| 参数 5 |
|-------------|
| 返回地址 | <-- SP
|-------------|此时我们转入函数代码中;
函数 add_numbers 的代码
add_numbers procpush bp mov bp, sp mov ax, [bp+4] add ax, [bp+6] pop bp ret
add_numbers endp执行 push bp 指令时,堆栈变化:
|-------------|
| 参数 10 |
|-------------|
| 参数 5 |
|-------------|
| BP 的旧值 |
|-------------|
| 返回地址 | <-- SP
|-------------|执行 mov bp, sp 指令时,BP 指向 SP:
|-------------|
| 参数 10 |
|-------------|
| 参数 5 |
|-------------|
| 返回地址 |
|-------------|
| BP 的旧值 | <-- BP, SP
|-------------|获取参数的过程:
在计算机体系结构中,堆栈单元的大小通常由体系结构和编译器的约定确定。在x86架构中,包括16位、32位和64位模式,堆栈单元的大小通常是以字节为单位来计算的。
以下是几种常见情况下堆栈单元大小的概述:
①16位模式:在16位模式下,堆栈单元大小通常为2个字节。这意味着每个压入堆栈的元素都占用2个字节的空间。 这种模式下,CPU指令使用基于16位的地址和数据操作。 ②32位模式:在32位模式下,堆栈单元大小通常为4个字节。每个压入堆栈的元素占用4个字节的空间。 这种模式下,CPU指令使用32位的地址和数据操作。 ③64位模式:在64位模式下,堆栈单元大小通常为8个字节。每个压入堆栈的元素占用8个字节的空间。 这种模式下,CPU指令使用64位的地址和数据操作。
16位汇编函数获取第一个参数:
指令:mov ax, [bp+4]:BP 指向 BP 的旧值,[BP+4] 即为第一个参数的位置(参数 5)。
16位汇编函数获取第二个参数:
指令:add ax, [bp+6]
BP 指向 BP 的旧值,[BP+6] 即为第二个参数的位置(参数 10)。
BP+4表示相对于基址寄存器(Base Pointer,通常是BP)的偏移地址,即BP中的地址加上4(字节)为第一个参数,BP中的地址+6(字节)获得第二个参数;
至此函数参数传递/调用完毕。