无锡网站建设信息有限怎么去推广自己的网站
目录
1. 联邦学习介绍
2. 实验流程
3. 数据加载
4. 模型构建
5. 数据采样函数
6. 模型训练

1. 联邦学习介绍
联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备)。联邦学习的模式是在各分支节点分别利用本地数据训练模型,再将训练好的模型汇合到中心节点,获得一个更好的全局模型。
联邦学习的提出是为了充分利用用户的数据特征训练效果更佳的模型,同时,为了保证隐私,联邦学习在训练过程中,server和clients之间通信的是模型的参数(或梯度、参数更新量),本地的数据不会上传到服务器。
本项目主要是升级1.8版本的联邦学习fedavg算法至2.3版本,内容取材于基于PaddlePaddle实现联邦学习算法FedAvg - 飞桨AI Studio星河社区
2. 实验流程
联邦学习的基本流程是:
1. server初始化模型参数,所有的clients将这个初始模型下载到本地;
2. clients利用本地产生的数据进行SGD训练;
3. 选取K个clients将训练得到的模型参数上传到server;
4. server对得到的模型参数整合,所有的clients下载新的模型。
5. 重复执行2-5,直至收敛或达到预期要求
import os
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import random
import time
import paddle
import paddle.nn as nn
import numpy as np
from paddle.io import Dataset,DataLoader
import paddle.nn.functional as F
3. 数据加载
mnist_data_train=np.load('data/data2489/train_mnist.npy')
mnist_data_test=np.load('data/data2489/test_mnist.npy')
print('There are {} images for training'.format(len(mnist_data_train)))
print('There are {} images for testing'.format(len(mnist_data_test)))
# 数据和标签分离(便于后续处理)
Label=[int(i[0]) for i in mnist_data_train]
Data=[i[1:] for i in mnist_data_train]
There are 60000 images for training
There are 10000 images for testing
4. 模型构建
class CNN(nn.Layer):def __init__(self):super(CNN,self).__init__()self.conv1=nn.Conv2D(1,32,5)self.relu = nn.ReLU()self.pool1=nn.MaxPool2D(kernel_size=2,stride=2)self.conv2=nn.Conv2D(32,64,5)self.pool2=nn.MaxPool2D(kernel_size=2,stride=2)self.fc1=nn.Linear(1024,512)self.fc2=nn.Linear(512,10)# self.softmax = nn.Softmax()def forward(self,inputs):x = self.conv1(inputs)x = self.relu(x)x = self.pool1(x)x = self.conv2(x)x = self.relu(x)x = self.pool2(x)x=paddle.reshape(x,[-1,1024])x = self.relu(self.fc1(x))y = self.fc2(x)return y
5. 数据采样函数
# 均匀采样,分配到各个client的数据集都是IID且数量相等的
def IID(dataset, clients):num_items_per_client = int(len(dataset)/clients)client_dict = {}image_idxs = [i for i in range(len(dataset))]for i in range(clients):client_dict[i] = set(np.random.choice(image_idxs, num_items_per_client, replace=False)) # 为每个client随机选取数据image_idxs = list(set(image_idxs) - client_dict[i]) # 将已经选取过的数据去除client_dict[i] = list(client_dict[i])return client_dict
# 非均匀采样,同时各个client上的数据分布和数量都不同
def NonIID(dataset, clients, total_shards, shards_size, num_shards_per_client):shard_idxs = [i for i in range(total_shards)]client_dict = {i: np.array([], dtype='int64') for i in range(clients)}idxs = np.arange(len(dataset))data_labels = Labellabel_idxs = np.vstack((idxs, data_labels)) # 将标签和数据ID堆叠label_idxs = label_idxs[:, label_idxs[1,:].argsort()]idxs = label_idxs[0,:]for i in range(clients):rand_set = set(np.random.choice(shard_idxs, num_shards_per_client, replace=False)) shard_idxs = list(set(shard_idxs) - rand_set)for rand in rand_set:client_dict[i] = np.concatenate((client_dict[i], idxs[rand*shards_size:(rand+1)*shards_size]), axis=0) # 拼接return client_dict
class MNISTDataset(Dataset):def __init__(self, data,label):self.data = dataself.label = labeldef __getitem__(self, idx):image=np.array(self.data[idx]).astype('float32')image=np.reshape(image,[1,28,28])label=np.array(self.label[idx]).astype('int64')return image, labeldef __len__(self):return len(self.label)6. 模型训练
class ClientUpdate(object):def __init__(self, data, label, batch_size, learning_rate, epochs):dataset = MNISTDataset(data,label)self.train_loader = DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)self.learning_rate = learning_rateself.epochs = epochsdef train(self, model):optimizer=paddle.optimizer.SGD(learning_rate=self.learning_rate,parameters=model.parameters())criterion = nn.CrossEntropyLoss(reduction='mean')model.train()e_loss = []for epoch in range(1,self.epochs+1):train_loss = []for image,label in self.train_loader:# image=paddle.to_tensor(image)# label=paddle.to_tensor(label.reshape([label.shape[0],1]))output=model(image)loss= criterion(output,label)# print(loss)loss.backward()optimizer.step()optimizer.clear_grad()train_loss.append(loss.numpy()[0])t_loss=sum(train_loss)/len(train_loss)e_loss.append(t_loss)total_loss=sum(e_loss)/len(e_loss)return model.state_dict(), total_loss
train_x = np.array(Data)
train_y = np.array(Label)
BATCH_SIZE = 32
# 通信轮数
rounds = 100
# client比例
C = 0.1
# clients数量
K = 100
# 每次通信在本地训练的epoch
E = 5
# batch size
batch_size = 10
# 学习率
lr=0.001
# 数据切分
iid_dict = IID(mnist_data_train, 100)
def training(model, rounds, batch_size, lr, ds,L, data_dict, C, K, E, plt_title, plt_color):global_weights = model.state_dict()train_loss = []start = time.time()# clients与server之间通信for curr_round in range(1, rounds+1):w, local_loss = [], []m = max(int(C*K), 1) # 随机选取参与更新的clientsS_t = np.random.choice(range(K), m, replace=False)for k in S_t:# print(data_dict[k])sub_data = ds[data_dict[k]]sub_y = L[data_dict[k]]local_update = ClientUpdate(sub_data,sub_y, batch_size=batch_size, learning_rate=lr, epochs=E)weights, loss = local_update.train(model)w.append(weights)local_loss.append(loss)# 更新global weightsweights_avg = w[0]for k in weights_avg.keys():for i in range(1, len(w)):# weights_avg[k] += (num[i]/sum(num))*w[i][k]weights_avg[k]=weights_avg[k]+w[i][k] weights_avg[k]=weights_avg[k]/len(w)global_weights[k].set_value(weights_avg[k])# global_weights = weights_avg# print(global_weights)#模型加载最新的参数model.load_dict(global_weights)loss_avg = sum(local_loss) / len(local_loss)if curr_round % 10 == 0:print('Round: {}... \tAverage Loss: {}'.format(curr_round, np.round(loss_avg, 5)))train_loss.append(loss_avg)end = time.time()fig, ax = plt.subplots()x_axis = np.arange(1, rounds+1)y_axis = np.array(train_loss)ax.plot(x_axis, y_axis, 'tab:'+plt_color)ax.set(xlabel='Number of Rounds', ylabel='Train Loss',title=plt_title)ax.grid()fig.savefig(plt_title+'.jpg', format='jpg')print("Training Done!")print("Total time taken to Train: {}".format(end-start))return model.state_dict()#导入模型
mnist_cnn = CNN()
mnist_cnn_iid_trained = training(mnist_cnn, rounds, batch_size, lr, train_x,train_y, iid_dict, C, K, E, "MNIST CNN on IID Dataset", "orange")
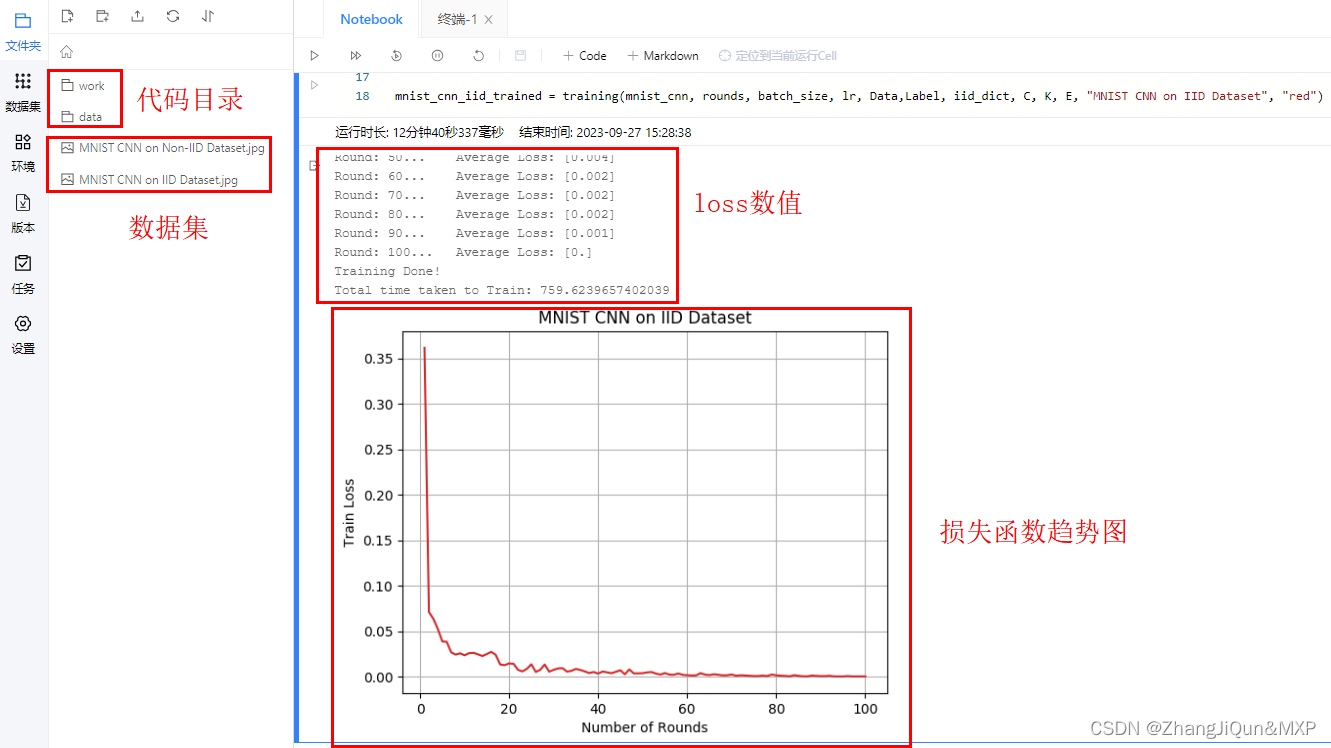
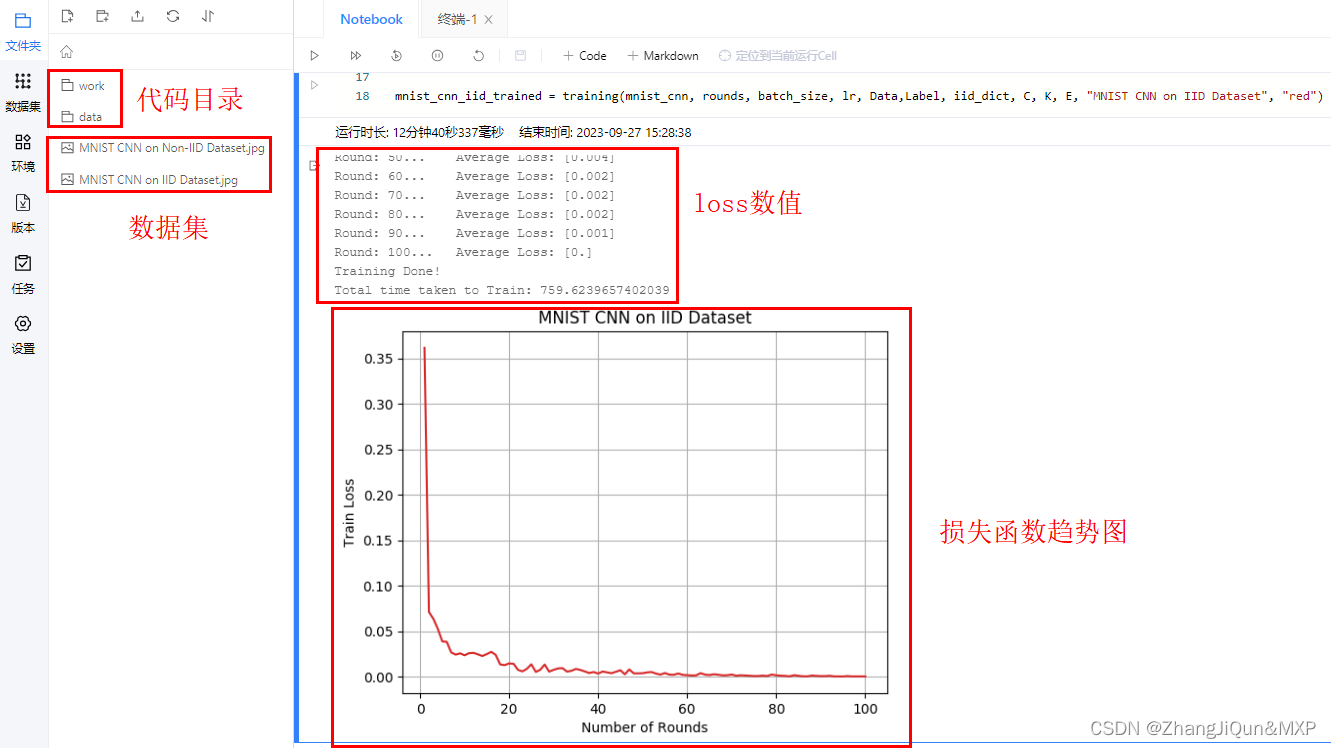
Round: 10... Average Loss: [0.024]
Round: 20... Average Loss: [0.015]
Round: 30... Average Loss: [0.008]
Round: 40... Average Loss: [0.003]
Round: 50... Average Loss: [0.004]
Round: 60... Average Loss: [0.002]
Round: 70... Average Loss: [0.002]
Round: 80... Average Loss: [0.002]
Round: 90... Average Loss: [0.001]
Round: 100... Average Loss: [0.]
Training Done!
Total time taken to Train: 759.6239657402039