营销公司有哪些seo技术培训
InstDisc
提出了个体判别任务,而且利用这个代理任务与NCE Loss去做对比学习从而得到了不错的无监督表征学习的结果;同时提出了别的数据结构——Memory Bank来存储大量负样本;解决如何对特征进行动量式的更新

翻译:
有监督学习的结果激励了我们的无监督学习方法。对于来自豹的图像,从已经训练过的神经网络分类器中获得最高响应的类都是视觉上相关的,例如,美洲虎和猎豹。无关语义标记,而是数据本身明显的相似性使一些类比其他类更接近。我们的无监督方法将这种按类判别的无监督信号发挥到了极致,并学习了区分单个实例的特征表示。
总结:
把每个实例(也就是图片)都看作一个类别,目标是学一种特征,从而让我们能把每一个图片都区分开来
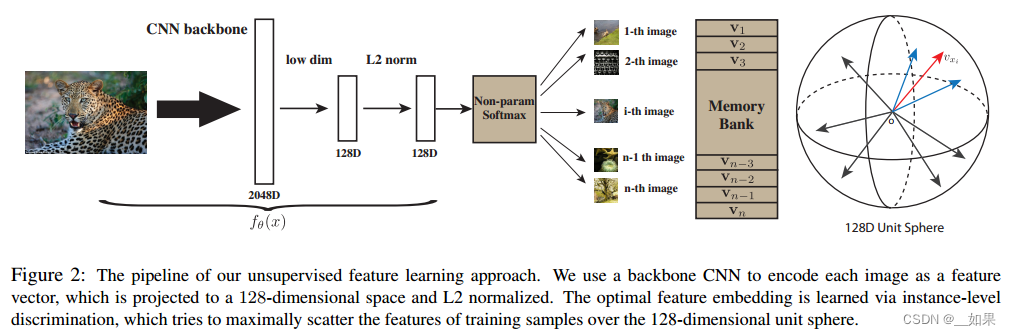
翻译:
这是无监督特征学习方法的整体流程。我们使用主干CNN将每张图像编码为特征向量,将其投影到128维空间并进行L2归一化。最优的特征嵌入是通过实例级判别来学习的,它试图最大限度地将训练样本的特征分散在128维单位球面上。
总结:
通过CNN把所有图片编码成特征,希望这些特征在最后的特征空间里能够尽可能的分开
利用对比学习训练CNN,正样本是图片本身(可能加一些数据增强),负样本则是数据集中其他图片
大量的负样本特征存在哪呢?运用Memory Bank的形式,把特征存进去,有多少特征就有多少行,因此特征的维度不能太大
Memory Bank随机初始化维单位向量
正样本利用CNN降低维度后,从Memory Bank中随机抽取负样本,然后可以用NCE Loss计算这个对比学习的目标函数,更新完网络后,可以把这些数据样本对应的特征放进Memory Bank更换掉
Proximal Regularization
给模型加了个约束,从而能让Memory Bank中的那些特征进行动量式的更新
Unlike typical classification settings where each class has many instances, we only have one instance per class.During each training epoch, each class is only visited once.
Therefore, the learning process oscillates a lot from random sampling fluctuation. We employ the proximal optimization method [29] and introduce an additional term to encourage the smoothness of the training dynamics. At current iteration t, the feature representation for data xi is computed from the network v (t) i = fθ(xi). The memory bank of all the representation are stored at previous iteration V = fv (t−1)g. The loss function for a positive sample from Pd is:
翻译:
与每个类有许多实例的典型分类设置不同,我们每个类只有一个实例。在每个训练阶段,每个类只访问一次。因此,学习过程在随机抽样波动中振荡很大。我们采用了最接近优化方法[29],并引入了一个额外的术语来鼓励训练动态的平滑性。在当前迭代t中,数据xi的特征表示是从网络v (t) i = fθ(xi)中计算出来的。所有表示的存储库都存储在前一次迭代V = fv (t−1)g。Pd阳性样本的损失函数为:
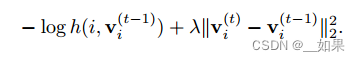
As learning converges, the difference between iterations, i.e. v (t) i − v (t−1) i , gradually vanishes, and the augmented loss is reduced to the original one. With proximal regularization, our final objective becomes:
翻译:
随着学习的收敛,迭代之间的差值即v (t) i - v (t - 1) i逐渐消失,增广损失减小到原始损失。通过近端正则化,我们的最终目标变成:
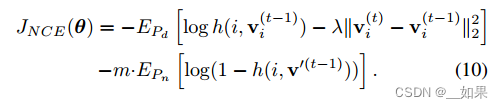
InvaSpreed
对于相似的图片,它的特征应该保持不变性;对不相似的图片,它的特征应该尽可能分散开
端到端;不需要借助外部数据结构去存储负样本
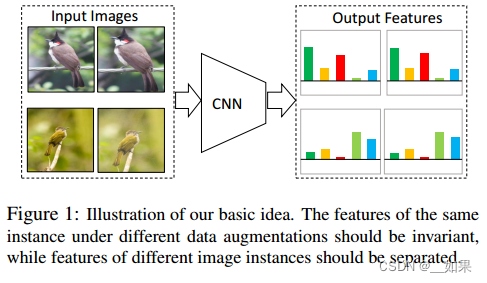
同样的图片通过编码器后得到的特征应该很相似,而不同的则不相似
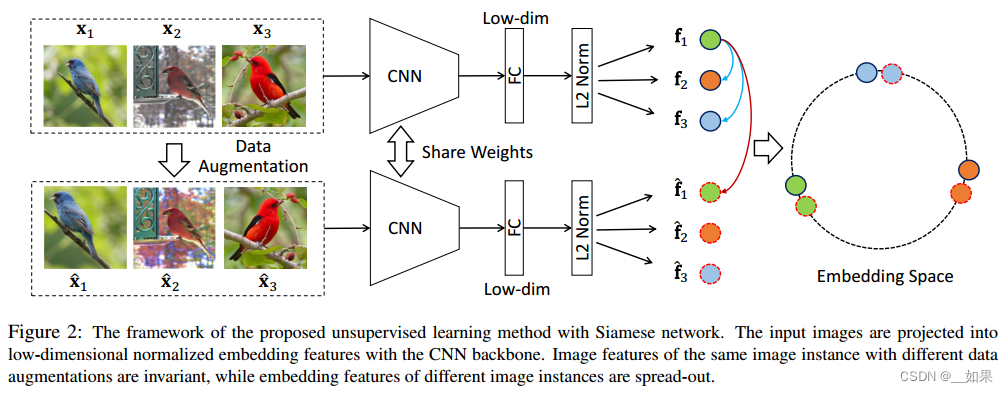
对X1来说,经过数据增强的X1‘就是它的正样本,负样本则是其他所有图片(包括数据增强后的)
为什么要从同一个mini-batch中选正负样本呢?这样就可以用一个编码器去做端到端的训练
图片过编码器再过全连接层,把特征维度降低,目标函数则使用NCE Loss的变体
之所以被SimCLR打败,是因为没有钞能力:mini-batch太小,导致负样本太少
CPC
以上两个都使用个体判别式的代理任务,CPC则是使用生成式的代理任务
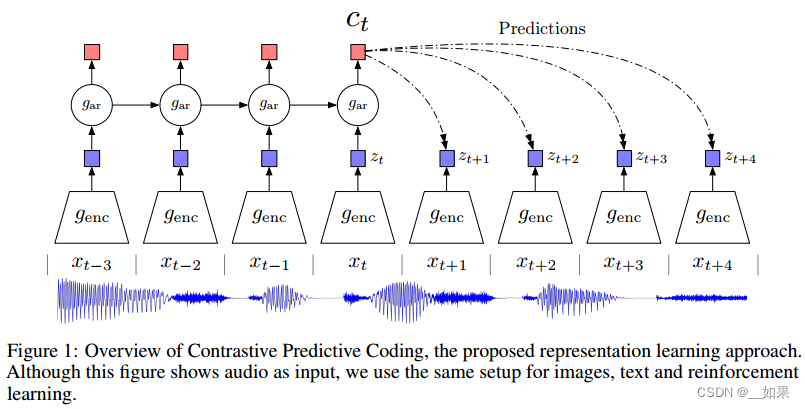
不光可以处理音频,还可以处理文字、图片、以及在强化学习中使用
我们有一个语音序列,从xt-3到xt代表过去到现在的输入,将其全扔给一个编码器,把编码器返回的特征喂给一个自回归模型gar(RNN或LSTM),得到ct(上下文的特征表示),如果ct足够好,那么认为它可以对未来的zt+1到zt+4做出合理预测
这里的正样本是未来的输入通过编码器得到的未来时刻的特征输出,也就是真正正确的zt+1到zt+4
负样本的定义倒是很广泛,任意输入通过编码器得到的特征输出都是负样本
CMC
定义正样本的方式更广泛:一个物体的很多视角都可以当作正样本
Abstract
Humans view the world through many sensory channels, e.g., the long-wavelength light channel, viewed by the left eye, or the high-frequency vibrations channel, heard by the right ear. Each view is noisy and incomplete, but important factors, such as physics, geometry, and semantics, tend to be shared between all views (e.g., a “dog” can be seen, heard, and felt). We investigate the classic hypothesis that a powerful representation is one that models view-invariant factors. We study this hypothesis under the framework of multiview contrastive learning, where we learn a representation that aims to maximize mutual information between different views of the same scene but is otherwise compact.
Our approach scales to any number of views, and is viewagnostic. We analyze key properties of the approach that make it work, finding that the contrastive loss outperforms a popular alternative based on cross-view prediction, and that the more views we learn from, the better the resulting representation captures underlying scene semantics. Our approach achieves state-of-the-art results on image and video unsupervised learning benchmarks.
翻译:
人类通过许多感官通道来观察世界,例如,左眼看到的长波长光通道,或右耳听到的高频振动通道。每个视图都是嘈杂和不完整的,但重要的因素,如物理,几何和语义,倾向于在所有视图之间共享(例如,可以看到、听到和感觉到“狗”)。我们研究了一个经典的假设,即一个强大的表示是一个模型的观点不变的因素。我们在多视图对比学习的框架下研究这一假设,在多视图对比学习中,我们学习的表征旨在最大化同一场景的不同视图之间的相互信息,但除此之外是紧凑的。
我们的方法适用于任意数量的视图,并且是视图不可知论的。我们分析了使其有效的方法的关键属性,发现对比损失优于基于交叉视图预测的流行替代方案,并且我们学习的视图越多,结果表示捕获底层场景语义的效果就越好。我们的方法在图像和视频无监督学习基准上取得了最先进的结果。
总结:
增大所有视觉间的互信息,从而学得一个能抓住不同视角下的关键因素的特征

选取的NYU RGBD数据集有四个视角,分别是原始的图像、图像对于的深度信息、surface normal(表面法线)、物体的分割图像
虽然输入来自于不同的视角,但都属于一张图片,因此这四个特征在特征空间中应该尽可能靠近,互为正样本;不配对的视角应该尽可能远离