哪个网站可以做私单培训课程网站
背景
随着业务爆炸式增长与云原生技术的日渐成熟,大量云原生分布式数据库产品如雨后春笋般涌现,其中一部分主打 OLTP 场景的分布式数据库强调的是从计算-存储分离架构获得弹性收益;对于业界各种计算-存储分离架构的数据库而言,怎么用真实的端到端数据库 workload 去 benchmark 其底层存储系统一直存在以下难题:
对于数据库专用存储系统,不存在如 fio 一样的“事实标准” benchmark 模型
数据库专用存储系统实现与经典存储差别较大。若仍然将其当作经典存储来设计 benchmark,没有考虑数据库特点,会导致端到端存在“脱节”现象
为了解决上述问题,我们希望为字节跳动 veDB 底层的专用存储系统设计出契合数据库特点的 benchmark 模型。本次我们提出了 CDSBen 模型,利用 机器学习 方法,根据真实的数据库 端到端 事务 pattern 预测出对存储层的 IO pattern,从而对存储系统实现真实、精准的 benchmark。 相关文章 《 CDSBen: Benchmarking the Performance of Storage Services in Cloud-native Database System at ByteDance 》 发表于 VLDB 2023。
veDB 简介
veDB 是字节跳动基于计算-存储分离架构实现的,服务于 OLTP 场景的云原生分布式数据库,其目标是:
高弹性 : 计算层 & 存储层解耦,可独立按需扩缩容,解决单机扩展性问题。
高性价比 : 通过一系列深度的计算/存储内核优化,最终提升性能降低成本。
高易用性 : 完全兼容 MySQL、PG 等开源数据库引擎,降低学习/使用开销。
高可靠/高可用 : 计算/存储支持多副本、跨数据中心部署、快速 PITR 等能力,提升系统可用性 & 可靠性。
veDB 的系统架构如下所示:
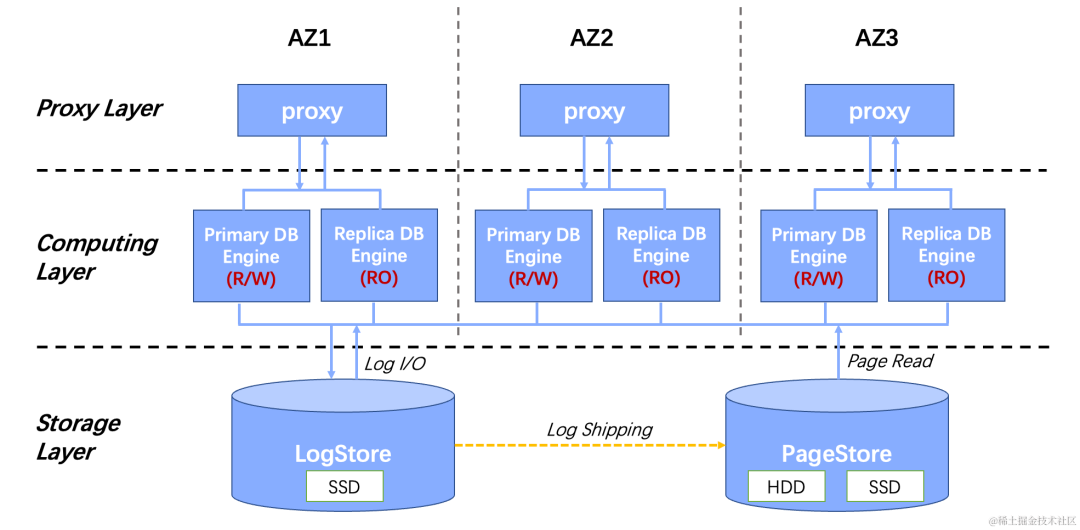
从上图可知,veDB 整体分为三层:
接入层: 提供鉴权、流控、读写路由等功能。
计算层: 完全兼容 MySQL、PG 等开源数据库引擎,支持 DML、DDL、事务。
存储层: 为数据库设计的专用分布式存储系统,可以插件的形式支持不同数据库引擎。
veDB 存储层 Benchmark 存在的问题与挑战
veDB 的底层存储是专门为数据库设计的专用分布式存储系统,称为 veDB DBStore。在veDB DBStore 内部,又分为专门持久化 WAL 的日志存储模块和管理多版本数据 page 的 PageStore 模块。在此架构下,如果我们要对 veDB DBStore 进行 benchmark,之前我们常用的两种方式是:
采用数据库端到端的 benchmark 模型(如 TPC系列 & sysbench 系列),调整各种参数进行压测。
采用改造后的 YCSB/类 fio 工具,调整各种参数进行压测。
然而,以上的两种方式对于 veDB Store 来说存在以下挑战:
端到端 benchmark 模型(TPC/sysbench)本质都是并发执行 SQL statement,而存储层无法直接处理 SQL,所以用 TPC/sysbench 就不能脱离计算层来单独对存储层进行压测。
经改造的 ycsb/类 fio 工具可以单独对存储层进行压测,其对于经典存储系统而言具有普适性,但是经典存储的 IO pattern 又跟数据库的事务场景没太大关联,跟数据库“脱节”。
基于这些问题与挑战,我们针对 veDB Store 里管理多版本数据 page 的 PageStore 设计了 CDSBen 模型。我们尝试将端到端的数据库事务执行 pattern 跟存储系统的 IO pattern 匹配起来,从而在脱离计算层的情况下,能够以最真实的、端到端的 pattern 对 PageStore 进行 benchmark。
CDSBen 方案
Learning-based 模型
CDSBen 包括两个学习模型,一个是 IOPS 序列预测模型,基于循环神经网络;另一个是联合分布预测模型,基于随机森林,这个模型主要被用于预测读写请求的目标地址(PageStore segment ID)和写入数据量的联合分布。
CDSBen 的工作流程如下:
选择一个/多个真实业务场景,从 veDB 的计算层和存储层的 running log 中提取 workload 特征,并用所提取的特征训练 CDSBen 模型。
用户向 CDSBen 输入计算层的 workload 特征,CDSBen 会预测存储层对应的 workload 特征。
CDSBen 使用经过改造的 YCSB 生成具体的读写请求并直接在 veDB DBStore上运行,从而进行基准测试。
接下来,我们介绍 CDSBen 的具体细节,主要包括特征提取 ,模型设计和负荷生成三个部分。
特征提取指从计算层和存储层的 running log 中分别提取特征,这些特征会被分别用于 IOPS 预测模型和联合分布预测模型的输入和输出。
计算层的 workload 由多种事务类型混合构成,我们统计每一种事务的 TPS 作为计算层 workload 的特征向量,比如 veDB_OSS 业务包含四种单 SQL statement 的事务,分别为 SELECT、INSERT、UPDATE和DELETE;TPC-C 包含五种长事务,分别为 Line-Order、Payment、Order-Status、Delivery 和 Stock-Level。我们统计每一种事务的 TPS 作为计算层 workload 的特征向量。
存储层的 workload 由对 PageStore segment 的读写请求构成,针对读请求,我们关注该请求的时间戳和目标地址(Segment ID);针对写请求,我们关注时间戳,目标地址和写入数据量。我们从存储引擎的日志中得到每一个读写请求的具体信息,通过每个请求的时间戳,我们可以得出存储层 workload 的 IOPS 序列,其包含的信息可以同时描述存储层 workload 的强度和波动程度。我们也关注读写请求的目标地址和写入数据量的联合分布。
为了简化数据处理,我们将所有读请求看作写入数据量为0的写请求。我们使用一个二维数组表示读写请求在目标地址和写入数据量上的分布情况,如数组中的第 i 列第 j 个表示对于目标地址 i,写入数据量为 j 的读写请求的比例。
在特征提取完成之后,我们使用收集到的数据训练这两个模型。这两个模型的输入是计算层 workload 的特征向量,输出分别是 IOPS 序列和联合分布。在训练完成之后,我们输入所想要模拟的计算层 workload 的特征向量,CDSBen 会预测对应的存储层 workload 的特征向量。然后我们使用YCSB,基于预测出的存储层 workload 的特征向量,随机生成出读写请求并在存储层运行,进行性能测试。
需要注意的是,因为CDSBen在特征提取的过程中只关注计算层的TPS,而不关注 workload 内容本身(跑了什么SQL statement),因此针对每一种 workload,CDSBen 的模型必须被重新训练一次。但是在实践中我们发现,训练模型的开销较小(取决于模型本身的复杂度),这种开销是可以接受的。
CDSBen 的优势主要是准确,灵活,和易用。准确可直接参考论文中的实验结果或本文下面4.2节的部分截图。灵活和易用在于 CDSBen 可以像 YCSB 一样直接在存储层上运行,不需要像 TPC/sysbench 一样部署计算层,同时CDSBen 可以让用户在只输入想要模拟的计算层负荷的特征向量这一简单输入的情况下,生成贴近真实情况的读写请求,且有能力回答 what-if question( TPS 变化和事务比例变化)。
在实验中我们发现,与 YCSB 相比, CDSBen 生成的读写请求测量出的性能明显更贴近真实业务流量下的性能 。
模型效果
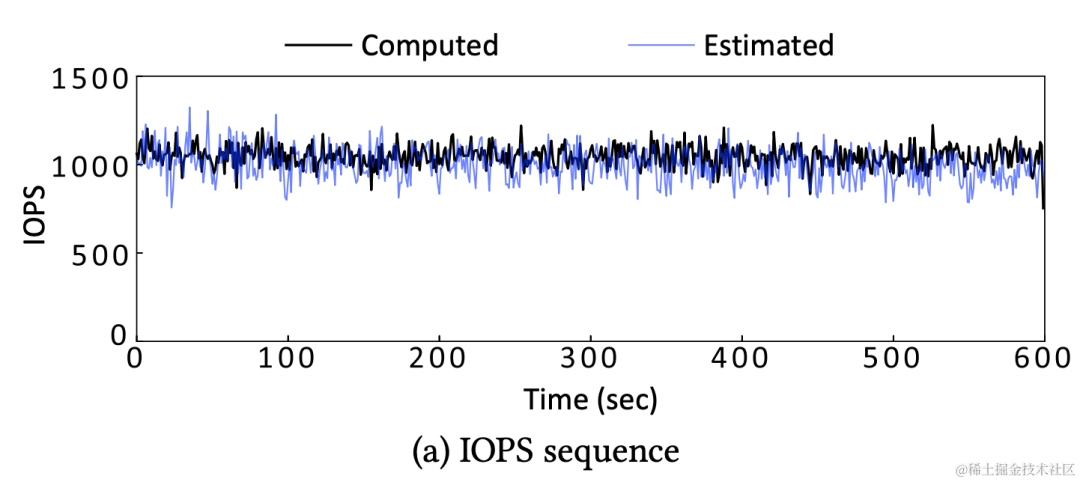
上图是模型生成的 IOPS 曲线 & 真实线上业务 IOPS 曲线的对比图。在验证过程中,我们采样了线上一个代号 SYNC 的业务,图中的黑线是真实的业务对 veDB DBStore 造成的 IOPS 曲线,蓝线是 CDSBen 模型预测的 IOPS 曲线。从图中可以看出两条曲线的重合度很高,且两条曲线的一些数学特征匹配度很高(真实 IOPS 的区间平均值是1046、预测 IOPS 的区间平均值是999)。
总结
在没有 CDSBen 模型的阶段,如果想 benchmark 底层的存储系统(veDB DBStore)的性能,我们无法在脱离计算层的情况下,用真实的业务 workload 对存储层进行压测。
CDSBen 的作用,就是帮我们在事务 pattern(SQL statement)和存储 IO pattern(segment 读写)之间搭起了转换的桥梁,让我们可以脱离计算层,用较真实的业务 workload 对 veDB DBStore 进行测试。其收益在于:
帮助数据库研发工程师在开发阶段对底层存储系统进行精准调优,保证 veDB 每个版本端到端上线时性能的稳定性,持续给用户提供高性能的数据库服务。
精准地 benchmark 存储系统在真实 workload 下的(极限)性能,是我们在分布式数据库存储层实现精准流控的前提条件,无论哪种业务场景都能平滑、稳定地服务大量 veDB 实例的真实业务流量。