电脑本地网站建设百度热门关键词排名
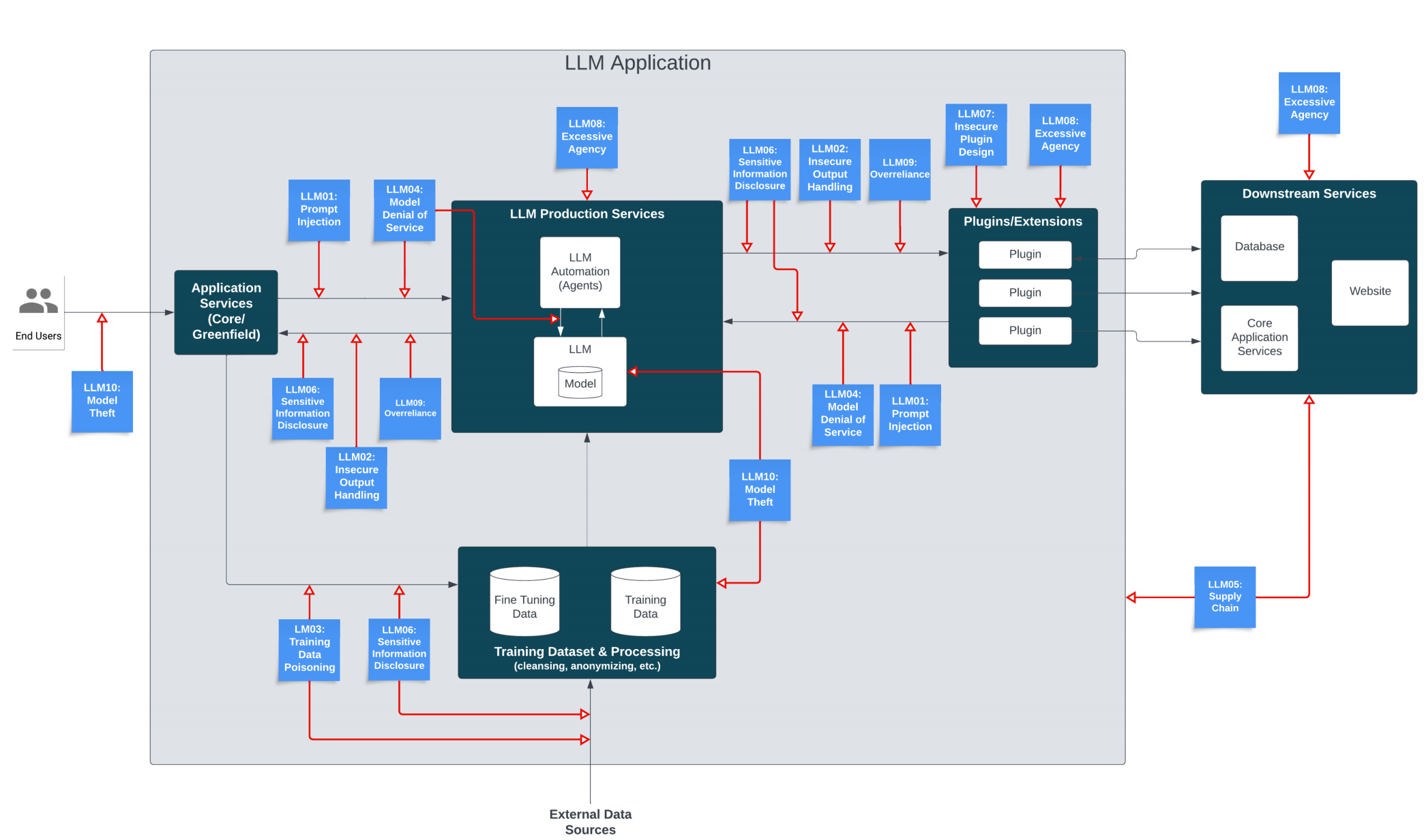
OWASP大型语言模型应用程序前十名项目旨在教育开发人员、设计师、架构师、经理和组织在部署和管理大型语言模型(LLM)时的潜在安全风险。该项目提供了LLM应用程序中常见的十大最关键漏洞的列表,强调了它们的潜在影响、易利用性和在现实应用程序中的普遍性。完整的项目报告可点此下载(访问密码: 6277)。
1. 产生背景
大语言模型(LLM,Large Language Model)是指参数量巨大、能够处理海量数据的模型, 此类模型通常具有大规模的参数,使得它们能够处理更复杂的问题,并学习更广泛的知识。自2022 年以来,LLM技术在得到了广泛的应用和发展,GPT 系列模型因其惊人的语言生成能力获得世界瞩目,国内外各大厂商也在此领域展开了激烈竞争。2023 年 8 月 15 日,国家六个部委发布的《生成式人工智能服务管理暂行办法》正式施行,更是强调了大语言模型安全的重要性,防止生成潜在隐私泄露、违法犯罪内容。

2. 风险概览

| 编号 | 风险名称 | 风险描述 |
|---|---|---|
| LLM01:2023 | 提示词注入 | 绕过过滤器或使用精心制作的提示操作LLM,使模型忽略先前的指令或执行非计划的操作。 |
| LLM02:2023 | 数据泄漏 | 通过LLM的回复意外泄露敏感信息、专有算法或其他机密细节。 |
| LLM03:2023 | 不完善的沙盒隔离 | 当LLM可以访问外部资源或敏感系统时,未能正确隔离LLM,从而允许潜在的利用和未经授权的访问。 |
| LLM04:2023 | 未授权代码执行 | 利用LLM通过自然语言提示在底层系统上执行恶意代码、命令或操作。 |
| LLM05:2023 | SSRF漏洞 | 利用LLM执行意外请求或访问受限制的资源,如内部服务、API或数据存储。 |
| LLM06:2023 | 过度依赖大语言模型生成的内容 | 在没有人为监督的情况下过度依赖法LLM生成的内容可能会导致不良后果。 |
| LLM07:2023 | 人工智能未充分对齐 | 未能确保LLM的目标和行为与预期用例保持一致,从而导致不良后果或漏洞。 |
| LLM08:2023 | 访问控制不足 | 未正确实现访问控制或身份验证,将允许未经授权的用户与LLM交互,并可能导致漏洞被利用。 |
| LLM09:2023 | 错误处置不当 | 暴露错误消息或调试信息,将导致敏感信息、系统详细信息或潜在攻击向量的泄露。 |
| LLM10:2023 | 训练数据投毒 | 恶意操纵训练数据或微调程序,将漏洞或后门引入LLM。 |
3. 风险详情
3.1. 提示词注入
提示词注入包括绕过过滤器或者通过精心构造的提示词来操控大语言模型(LLM)使得该模型忽略先前的指令或者执行意外操作。这些漏洞导致数据泄漏、未经授权的访问或者其他安全漏洞等意想不到的后果。
恶意用户通过利用特定的语言模式、词元或者编码机制来绕过内容过滤器,从而允许该
用户执行那些本应被阻止的操作。
3.2. 数据泄露
当大语言模型通过响应恶意请求意外泄漏敏感信息、专有算法或者其他机密细节时,就会发生数据泄漏。这可能导致未经授权访问敏感数据、窃取知识产品、侵犯隐私或其他安全漏洞。
比如,用户无意中向大语言模型提了一个可能导致敏感信息泄漏的问题。大语言模型缺乏恰当的输出过滤,响应内容中包括了敏感数据而导致敏感数据泄漏。

3.3. 不完善的沙盒隔离
当大语言模型访问外部资源或者敏感系统时,如果没有合适的隔离,就会导致大语言模型的潜在利用、未经授权的访问或者意外的操作。
攻击者通过精心构造提示词,指示大语言模型提取和暴露敏感信息,可利用大语言模型访问敏感数据库。
3.4. 未授权代码执行
当攻击者利用大语言模型通过自然语言提示词在底层系统上执行恶意代码、命令或操作时,就会发生未经授权的代码执行。

攻击者制作一个提示词来指示大语言模型执行一个命令,在底层系统上启动反向 shell,授予攻击者未经授权的访问权限。
3.5. SSRF 漏洞
当攻击者利用大语言模型执行意外请求或访问受限资源(如内部服务、API 或数据存储)时,会出现服务器端请求伪造漏洞 (SSRF)。
攻击者制作一个提示词,指示大语言模型向内部服务发出请求,绕过访问控制并获得对敏感信息的未授权访问。
3.6. 过度依赖大语言模型生成的内容
过度依赖大语言模型生成的内容,会导致误导或散播不正确信息。组织和用户可能会在未经验证的情况下信任大语言模型生成的内容,从而导致错误结果、沟通不畅乃至意料之外的后果。
3.7. 人工智能未充分对齐
当大语言模型的目标和行为与预期用例不一致时,就会出现人工智能未充分对齐的现象,从而导致非预期的后果或漏洞。常见的人工智能对齐漏洞如下:
- 未明确定义的目标,导致大语言模型优先考虑非预期的或有害的行为;
经过训练以优化用户参与度的某大语言模型,无意中优先推送有争议的或极端的内容,导致了错误信息或有害内容的广泛传播。
- 错误对齐的奖励函数或训练数据,导致非预期的模型行为;
- 在各种上下文和场景中,对大语言模型行为的测试和验证不足。
3.8. 访问控制不足
当访问控制或身份验证机制未正确实施时,会出现访问控制不足的情况,从而允许未经授权的用户与大语言模型进行交互,并可能对漏洞进行利用。
3.9. 训练数据投毒
训练数据投毒是指攻击者操纵大语言模型的训练数据或微调程序,引入可能危及模型安全性、有效性或伦理行为的漏洞、后门或偏见。
某攻击者侵入训练数据管道并注入恶意数据,导致大语言模型产生有害的或不恰当的响应。
4. 参考
[1] OWASP大语言模型应用程序十大风险V1.0.pdf (访问密码: 6277)
[2] https://owasp.org/www-project-top-10-for-large-language-model-applications/