怎样申请做p2p融资网站关键词排名关键词优化
前言
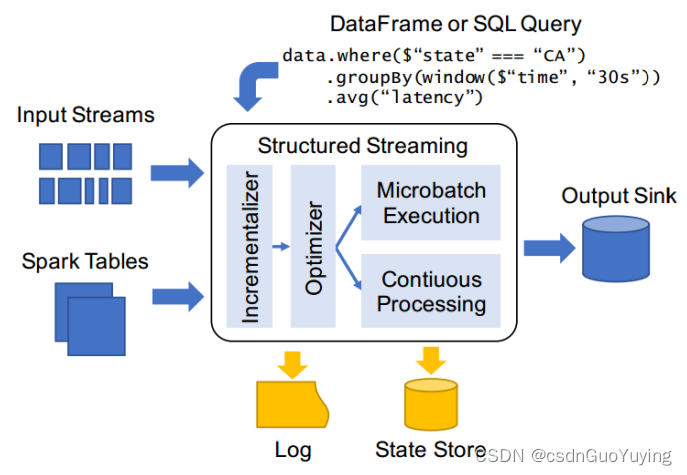
Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
Structured Streaming并不是对Spark Streaming的简单改进,而是吸取了在开发Spark SQL和Spark Streaming过程中的经验教训,以及Spark社区和Databricks众多客户的反馈,重新开发的全新流式引擎,致力于为批处理和流处理提供统一的高性能API。同时,在这个新的引擎中,也很容易实现之前在Spark Streaming中很难实现的一些功能,比如Event Time(事件时间)的支持,Stream-Stream Join(2.3.0 新增的功能),毫秒级延迟(2.3.0 即将加入的 Continuous Processing)。
第一章 Structured Streaming
Spark Streaming是Apache Spark早期基于RDD开发的流式系统,用户使用DStream API来编写代码,支持高吞吐和良好的容错。其背后的主要模型是Micro Batch(微批处理),也就是将数据流切成等时间间隔(BatchInterval)的小批量任务来执行。
Structured Streaming则是在Spark 2.0加入的,经过重新设计的全新流式引擎。它的模型十分简洁,易于理解。一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾,用户可以使用Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html
1.1 Spark Streaming 不足
Spark Streaming 会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。

本质上,这是一种micro-batch(微批处理)的方式处理,用批的思想去处理流数据。这种设计让Spark Streaming面对复杂的流式处理场景时捉襟见肘。
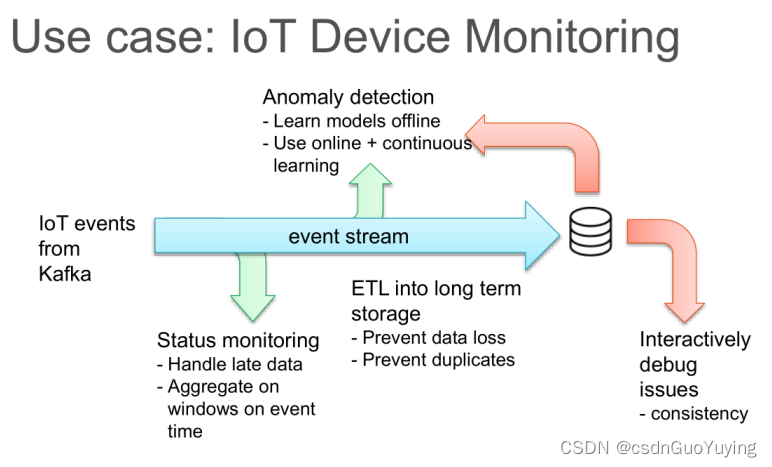
Spark Streaming 存在哪些不足,总结一下主要有下面几点:
第一点:使用 Processing Time 而不是 Event Time
- Processing Time 是数据到达 Spark 被处理的时间,而 Event Time 是数据自带的属性,一般表示数据产生于数据源的时间。
- 比如 IoT 中,传感器在 12:00:00 产生一条数据,然后在 12:00:05 数据传送到 Spark,那么 Event Time 就是 12:00:00,而 Processing Time 就是 12:00:05。
- Spark Streaming是基于DStream模型的micro-batch模式,简单来说就是将一个微小时间段(比如说 1s)的流数据当前批数据来处理。如果要统计某个时间段的一些数据统计,毫无疑问应该使用 Event Time,但是因为 Spark Streaming 的数据切割是基于Processing Time,这样就导致使用 Event Time 特别的困难。
第二点:Complex, low-level api
- DStream(Spark Streaming 的数据模型)提供的API类似RDD的API,非常的low level;
- 当编写Spark Streaming程序的时候,本质上就是要去构造RDD的DAG执行图,然后通过Spark Engine运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别;
第三点:reason about end-to-end application
- end-to-end指的是直接input到out,如Kafka接入Spark Streaming然后再导出到HDFS中;
- DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证;
第四点:批流代码不统一
- 尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,有时候确实需要将的流处理逻辑运行到批数据上面;
- Streaming尽管是对RDD的封装,但是要将DStream代码完全转换成RDD还是有一点工作量的,更何况现在Spark的批处理都用DataSet/DataFrameAPI;
流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年Google发表了The Dataflow Model的论文( https://yq.aliyun.com/articles/73255 )。Google开源Apache Beam项目,基本上就是对Dataflow模型的实现,目前已经成为Apache的顶级项目,但是在国内使用不多。
国内使用的更多的是Apache Flink,因为阿里大力推广Flink,甚至把花7亿元把Flink母公司收购。
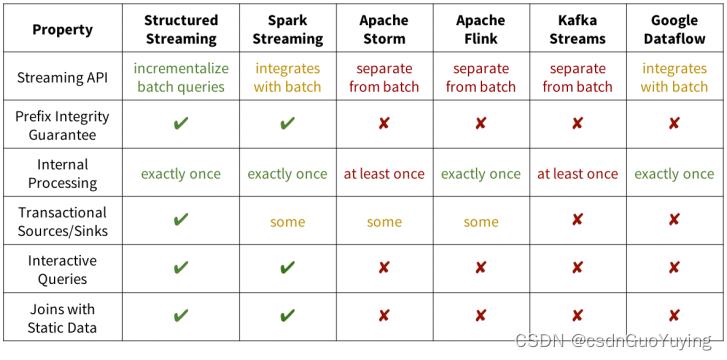
使用Yahoo的流基准平台,要求系统读取广告点击事件,并按照活动ID加入到一个广告活动的静态表中,并在10秒的event-time窗口中输出活动计数。比较了Kafka Streams 0.10.2、Apache Flink 1.2.1和Spark 2.3.0,在一个拥有5个c3.2*2大型Amazon EC2 工作节点和一个master节点的集群上(硬件条件为8个虚拟核心和15GB的内存)。
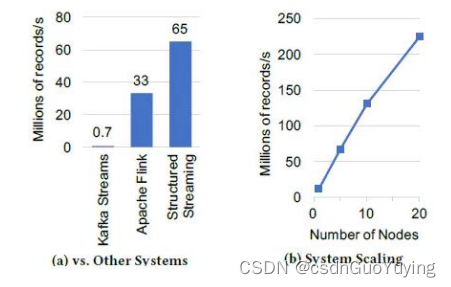
上图(a)展示了每个系统最大稳定吞吐量(积压前的吞吐量),Flink可以达到3300万,而Structured Streaming可以达到6500万,近乎两倍于Flink。这个性能完全来自于Spark SQL的内置执行优化,包括将数据存储在紧凑的二进制文件格式以及代码生成。
1.2 Structured Streaming 概述
或许是对Dataflow模型的借鉴,也许是英雄所见略同,Spark在2.0版本中发布了新的流计算的API:Structured Streaming结构化流。Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,可以使用静态数据批处理一样的方式来编写流式计算操作,并且支持基于event_time的时间窗口的处理逻辑。随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。

模块介绍
Structured Streaming 在 Spark 2.0 版本于 2016 年引入,设计思想参考很多其他系统的思想,比如区分 processing time 和 event time,使用 relational 执行引擎提高性能等。同时也考虑了和 Spark 其他组件更好的集成。
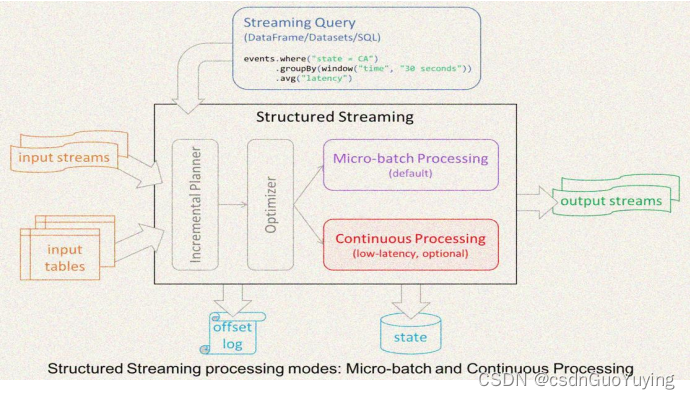
Structured Streaming 和其他系统的显著区别主要如下:
第一点:Incremental query model(增量查询模型)
- Structured Streaming 将会在新增的流式数据上不断执行增量查询,同时代码的写法和批处理 API(基于Dataframe和Dataset API)完全一样,而且这些API非常的简单。
第二点:Support for end-to-end application(支持端到端应用)
- Structured Streaming 和内置的 connector 使的 end-to-end 程序写起来非常的简单,而且 “correct by default”。数据源和sink满足 “exactly-once” 语义,这样我们就可以在此基础上更好地和外部系统集成。
第三点:复用 Spark SQL 执行引擎
- Spark SQL 执行引擎做了非常多的优化工作,比如执行计划优化、codegen、内存管理等。这也是Structured Streaming取得高性能和高吞吐的一个原因。