网站未在腾讯云备案网站之家
今天的议题是:如何快速处理kafka的消息积压
通常的做法有以下几种:
- 增加消费者数
- 增加 topic 的分区数,从而进一步增加消费者数
- 调整消费者参数,如
max.poll.records - 增加硬件资源
常规手段不是本文的讨论重点或者当上面的手段已经使用过依然存在很严重的消息积压时该怎么办?本文给出一种增加消费者消费速率的方案。我们知道消息积压往往是因为生产速率远大于消费速率,本文的重点就是通过提高消费速率来解决消息积压。
经验判断,消费速率低下的主要原因往往都是数据处理时间长,业务逻辑复杂最终导致一次 poll 的时间被无限拉长,如果可以通过增加数据处理的线程数来降低一次 poll 的时间那么问题就解决了。但是需要注意一下几点:
- 业务逻辑对乱序数据不敏感,因为并行一定会导致乱序问题
- kafka 的消费者是线程不安全的
- 如何提交 offset
基于上述几点,思路就是消费者 poll 下来一批数据,交给多个线程去并行处理,消费者等待所有线程执行完后提交。为了减少线程的创建与销毁则维护一个线程池。代码如下:
第一步:创建一个MultipleConsumer类用于封装消费者和线程池
public class MultipleConsumer {private final KafkaConsumer<String, String> consumer;private final int threadNum;private final ExecutorService threadPool;private boolean isRunning = true;public MultipleConsumer(Properties properties, List<String> topics, int threadNum) {// 实例化消费者consumer = new KafkaConsumer<>(properties);// 订阅主题consumer.subscribe(topics);this.threadNum = threadNum;this.threadPool = Executors.newFixedThreadPool(threadNum);}
}
理论上相较于传统的消费速率可以提升 threadNum 倍。
第二步:因为需要并行处理一批 poll 数据,因此需要对数据进行切分,切分逻辑如下
private Map<Integer, List<ConsumerRecord<String, String>>> splitTask(ConsumerRecords<String, String> consumerRecords) {HashMap<Integer, List<ConsumerRecord<String, String>>> tasks = new HashMap<>();for (int i = 0; i < threadNum; i++) {tasks.put(i, new ArrayList<>());}int recordIndex = 0;for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {tasks.get(recordIndex % threadNum).add(consumerRecord);recordIndex++;}return tasks;}
这里采用轮训的方式且切分的个数与 threadNum 一致,尽可能保证每个线程处理的数据数量相差不大
第三步:定义一个静态内部类用来处理数据,并处理同步逻辑(因为需要等待所有线程执行完再提交 offset)
private static class InnerProcess implements Runnable {private final List<ConsumerRecord<String, String>> records;private final CountDownLatch countDownLatch;public InnerProcess(List<ConsumerRecord<String, String>> records, CountDownLatch countDownLatch) {this.records = records;this.countDownLatch = countDownLatch;}@Overridepublic void run() {try {// 处理消息for (ConsumerRecord<String, String> record : records) {System.out.println("topic: " + record.topic() + ", partition: " + record.partition() + ", offset: " + record.offset() + ", key: " + record.key() + ", value: " + record.value());TimeUnit.SECONDS.sleep(1);}} catch (InterruptedException e) {e.printStackTrace();} finally {countDownLatch.countDown();}}}
使用 CountDownLatch 实现线程同步逻辑,假设每条数据的业务处理时间为 1 s
第四步:消费者 poll 逻辑
public void start() {while (isRunning) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(5));if (!consumerRecords.isEmpty()) {// 分割任务Map<Integer, List<ConsumerRecord<String, String>>> splitTask = splitTask(consumerRecords);CountDownLatch countDownLatch = new CountDownLatch(threadNum);// 提交任务for (int i = 0; i < threadNum; i++) {threadPool.submit(new InnerProcess(splitTask.get(i), countDownLatch));}// 等待任务执行结束try {countDownLatch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}// 提交偏移量consumer.commitAsync((map, e) -> {if (e != null) {System.out.println("提交偏移量失败");}});}}}
完整代码如下:
import org.apache.kafka.clients.consumer.*;import java.time.Duration;
import java.time.temporal.ChronoUnit;
import java.util.*;
import java.util.concurrent.*;/*** @author wjun* @date 2023/3/1 14:50* @email wjunjobs@outlook.com* @describe*/
public class MultipleConsumer {private final KafkaConsumer<String, String> consumer;private final int threadNum;private final ExecutorService threadPool;private boolean isRunning = true;public MultipleConsumer(Properties properties, List<String> topics, int threadNum) {// 实例化消费者consumer = new KafkaConsumer<>(properties);// 订阅主题consumer.subscribe(topics);this.threadNum = threadNum;this.threadPool = Executors.newFixedThreadPool(threadNum);}public void start() {while (isRunning) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(5));if (!consumerRecords.isEmpty()) {// 分割任务Map<Integer, List<ConsumerRecord<String, String>>> splitTask = splitTask(consumerRecords);CountDownLatch countDownLatch = new CountDownLatch(threadNum);// 提交任务for (int i = 0; i < threadNum; i++) {threadPool.submit(new InnerProcess(splitTask.get(i), countDownLatch));}// 等待任务执行结束try {countDownLatch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}// 提交偏移量consumer.commitAsync((map, e) -> {if (e != null) {System.out.println("提交偏移量失败");}});}}}private Map<Integer, List<ConsumerRecord<String, String>>> splitTask(ConsumerRecords<String, String> consumerRecords) {HashMap<Integer, List<ConsumerRecord<String, String>>> tasks = new HashMap<>();for (int i = 0; i < threadNum; i++) {tasks.put(i, new ArrayList<>());}int recordIndex = 0;for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {tasks.get(recordIndex % threadNum).add(consumerRecord);recordIndex++;}return tasks;}public void stop() {isRunning = false;threadPool.shutdown();}private static class InnerProcess implements Runnable {private final List<ConsumerRecord<String, String>> records;private final CountDownLatch countDownLatch;public InnerProcess(List<ConsumerRecord<String, String>> records, CountDownLatch countDownLatch) {this.records = records;this.countDownLatch = countDownLatch;}@Overridepublic void run() {try {// 处理消息for (ConsumerRecord<String, String> record : records) {System.out.println("topic: " + record.topic() + ", partition: " + record.partition() + ", offset: " + record.offset() + ", key: " + record.key() + ", value: " + record.value());TimeUnit.SECONDS.sleep(1);}} catch (InterruptedException e) {e.printStackTrace();} finally {countDownLatch.countDown();}}}
}
测试一下:
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;import java.util.ArrayList;
import java.util.List;
import java.util.Properties;/*** @author wjun* @date 2023/3/1 16:03* @email wjunjobs@outlook.com* @describe*/
public class MultipleConsumerTest {private static final Properties properties = new Properties();private static final List<String> topics = new ArrayList<>();public static void before() {properties.put("bootstrap.servers", "localhost:9092");properties.put("group.id", "test");properties.put("enable.auto.commit", "false");properties.put("auto.commit.interval.ms", "1000");properties.put("session.timeout.ms", "30000");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");topics.add("multiple_demo");}public static void main(String[] args) {new MultipleConsumer(properties, topics, 5).start();}
}
20 条数据的处理事件只需要 4s(threadNume = 5,即缩短 5 倍)
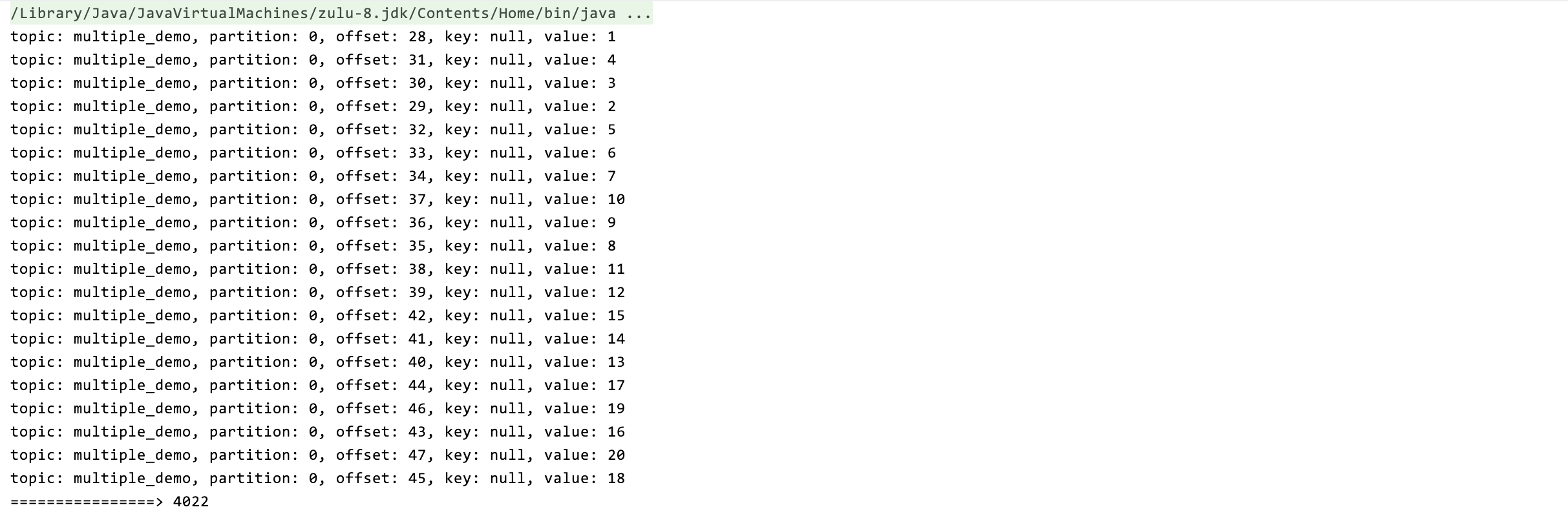
但是此方法的缺点:
- 只适用于业务逻辑复杂导致的处理时间长的场景
- 对数据乱序不敏感的业务场景