如何让网站速度快商丘网站seo
目录
Flink关键特性
流式处理
丰富的状态管理
丰富的时间语义支持
Data pipeline
容错机制
Flink SQL
CEP in SQL
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种sink中。

Apache Flink由于其广泛的特性,是开发和运行许多不同类型应用的优秀选择。Flink的特性包括对流和批处理的支持、复杂的状态管理、event-time处理语义、以及exactly-once保证。此外,Flink可以部署在各种资源管理平台上,例如Yarn、Mesos和Kubernetes,也可以作为一个standalone的集群。Flink具有高可用性,没有单点故障的情况。Flink已经被证明可以扩展到数千个核和TB级的应用,并提供高吞吐量和低延迟。
Flink关键特性
-
流式处理
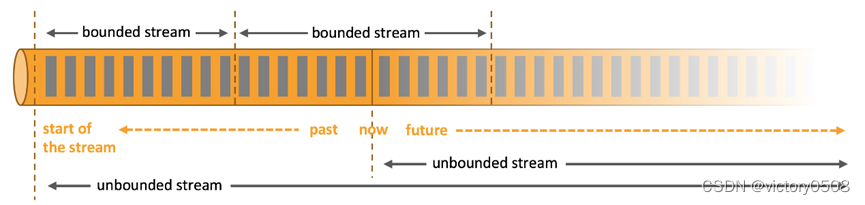
无界流是有始无终的数据流,即无限数据流,程序必须持续不断地对到达的数据进行处理。有界流是限定大小的有始有终的数据集合,即有限数据流,批处理是有界数据流处理的范例。可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
-
丰富的状态管理
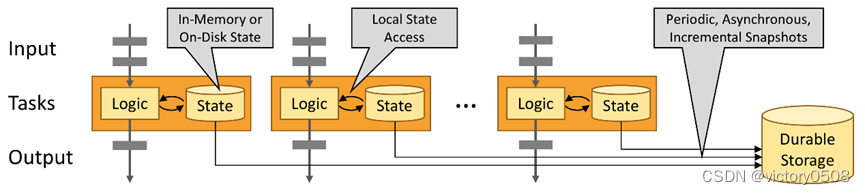
状态由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态,可以认为状态就是一个本地变量,可以被任务的业务逻辑访问。
Flink会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。Flink提供丰富的状态管理,包括多种基础状态类型、丰富的State Backend,State可以存储在内存上或RocksDB等上,并支持异步以及增量的Checkpoint机制、精确一次语义等等。
Flink 应用程序的状态访问都在本地进行,因为这有助于其提高吞吐量和降低延迟。通常情况下 Flink 应用程序都是将状态存储在 JVM 堆上,但如果状态太大,我们也可以选择将其以结构化数据格式存储在高速磁盘中。
时间是流处理应用的重要组成部分,对于实时流处理应用来说,基于时间语义的窗口聚合、检测、匹配等运算是非常常见的。Flink提供了丰富的时间语义支持。
-
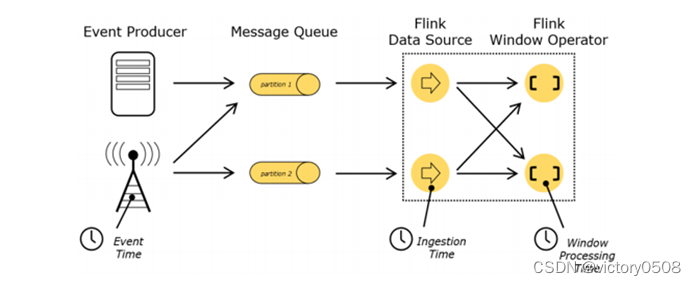
- Event-time:使用事件本身自带的时间戳进行计算,使乱序到达或延迟到达的事件处理变得更加简单。
- Ingestion Time:是数据进入Flink的时间
- Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,如默认的时间属性。
- Watermark支持:Flink引入Watermark概念,用以衡量事件时间的发展。Watermark也为平衡处理时延和数据完整性提供了灵活的保障。当处理带有Watermark的事件流时,在计算完成之后仍然有相关数据到达时,Flink提供了多种处理选项,如将数据重定向(side output)或更新之前完成的计算结果。
- 高度灵活的流式窗口支持:Flink能够支持时间窗口、计数窗口、会话窗口,以及数据驱动的自定义窗口,可以通过灵活的触发条件定制,实现复杂的流式计算模式。
-
Data pipeline
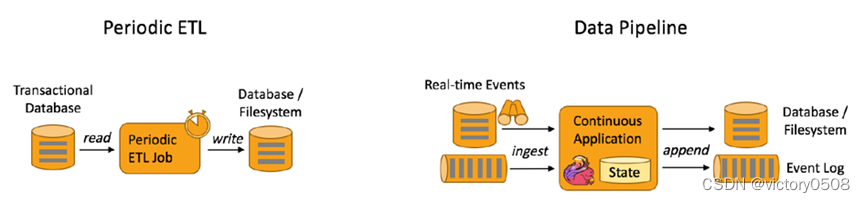
ETL(抽取-转换-加载)是在存储系统间转换和移动数据的一种常用方法。通常,ETL任务会定期的触发,将业务数据系统中的数据拷贝到分析数据库或数据仓库中。
data pipeline的作用和ETL任务类似。它们转换数据,将数据从一个存储系统移动到另一个存储系统。然而,data pipeline操作不是定期的触发,而是作为一个连续不断的流处理方式处理数据。因此,它们能从不断产生数据的源中读取记录,并以较低延迟将其移动到目的地。
连续的data pipelines相比周期性的ETL作业,其最大的优点使具有更低的延迟。此外,data pipeline更加通用,可以用于更多场景,因为它们能连续地使用和发出数据。
-
容错机制
分布式系统,单个task或节点的崩溃或故障,往往会导致整个任务的失败。Flink提供了任务级别的容错机制,保证任务在异常发生时不会丢失用户数据,并且能够自动恢复。
Flink的Checkpoint和故障恢复能力保证了任务在故障发生前后的应用状态一致性,为某些特定的存储支持了事务型输出的功能,即使在发生故障的情况下,也能够保证精确一次的输出。
Flink基于Checkpoint实现容错,用户可以自定义对整个任务的Checkpoint策略,当任务出现失败时,可以将任务恢复到最近一次Checkpoint的状态,从数据源重发快照之后的数据。即重置数据源从状态中记录的上次消费的偏移量开始重新进行消费处理。而且状态快照在执行时会异步获取状态并存储,并不会阻塞正在进行的数据处理逻辑。
Savepoint:一个Savepoint就是应用状态的一致性快照,Savepoint与Checkpoint机制相似,但Savepoint需要手动触发,Savepoint保证了任务在升级或迁移时,不丢失掉当前流应用的状态信息,便于任何时间点的任务暂停和恢复。
-
Flink SQL
SELECT userId, COUNT(*)
FROM clicks
GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
-
CEP in SQL
Flink允许用户在SQL中表示CEP(Complex Event Processing)查询结果以用于模式匹配,并在Flink上对事件流进行评估。
CEP SQL 通过MATCH_RECOGNIZE的SQL语法实现。MATCH_RECOGNIZE子句自Oracle Database 12c起由Oracle SQL支持,用于在SQL中表示事件模式匹配。CEP SQL使用举例如下:
SELECT T.aid, T.bid, T.cid
FROM MyTableMATCH_RECOGNIZE (PARTITION BY useridORDER BY proctimeMEASURESA.id AS aid,B.id AS bid,C.id AS cidPATTERN (A B C)DEFINEA AS name = 'a',B AS name = 'b',C AS name = 'c') AS T