济宁有做企业网站吗市场监督管理局是干什么的
在「X」Embedding in NLP 进阶系列中,我们介绍了自然语言处理的基础知识——自然语言中的 Token、N-gram 和词袋语言模型。今天,我们将继续和大家一起“修炼”,深入探讨神经网络语言模型,特别是循环神经网络,并简要了解如何生成 Embedding 向量。
01.深入了解神经网络
首先,简要回顾一下神经网络的构成,即神经元、多层网络和反向传播算法。如果还想更详细深入了解这些基本概念可以参考其他资源,如 CS231n 课程笔记。
在机器学习中,神经元是构成所有神经网络的基本单元。本质上,神经元是神经网络中的一个单元,它对其所有输入进行加权求和,并加上一个可选的偏置项。方程式表示如下所示:
在这里, x 0 , x 1 , . . . , x n − 1 代表上一层神经元的输出, w 0 , w 1 , . . . , w n − 1 代表这个神经元用来综合输出值的权重。
如果一个多层神经网络仅由上述方程中的加权和组成,我们可以将所有项合并为一个单一的线性层——这对于建模 Token 之间的关系或编码复杂文本并不是很理想。这就是为什么所有神经元在加权和之后都包含一个非线性激活函数,其中我们最熟知的例子就是修正线性单元(ReLU)函数:
对于大多数现代神经网络语言模型来说,高斯误差线性单元(GELU)激活函数更常见:
在这里, Φ q 代表高斯累积分布函数,可以用 G E L U ( q ) ≈ q 1 + e − 1.702 q 来表示。这个激活函数在上述的加权求和之后被应用。总而言之,一个单一的神经元看起来像这样:
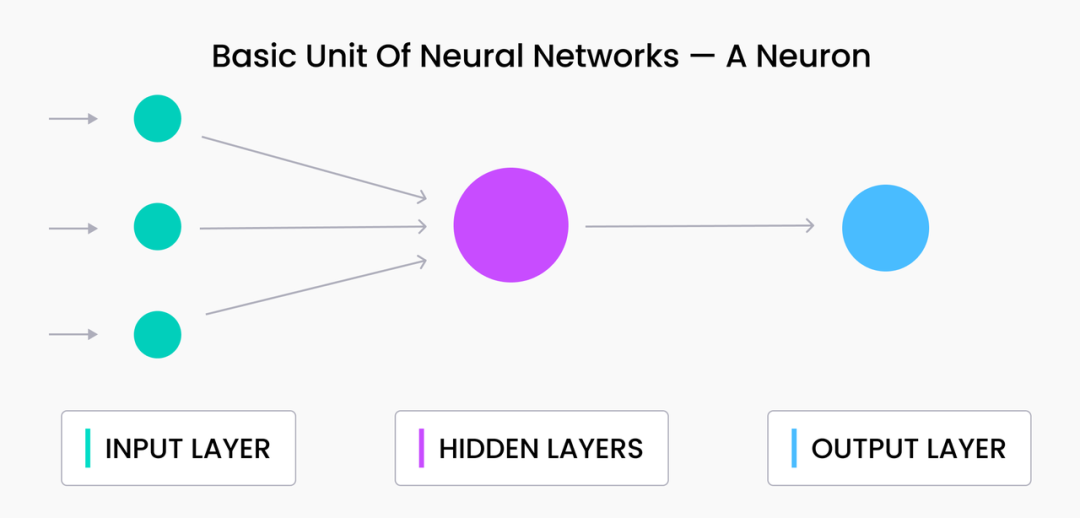
为了学习更复杂的函数,我们可以将神经元堆叠起来——一个接一个地形成一个层。同一层中的所有神经元接收相同的输入;它们之间唯一的区别是权重 w 和偏置 b 。我们可以用矩阵符号将上述方程表示一个单层:
在这里, w 是一个二维矩阵,包含应用于输入 x 的所有权重;矩阵的每一行对应一个神经元的权重。这种类型的层通常被称为密集层或全连接层,因为所有输入 x 都连接到所有输出 y 。
我们可以将这两个层串联起来,创建一个基本的前馈网络:
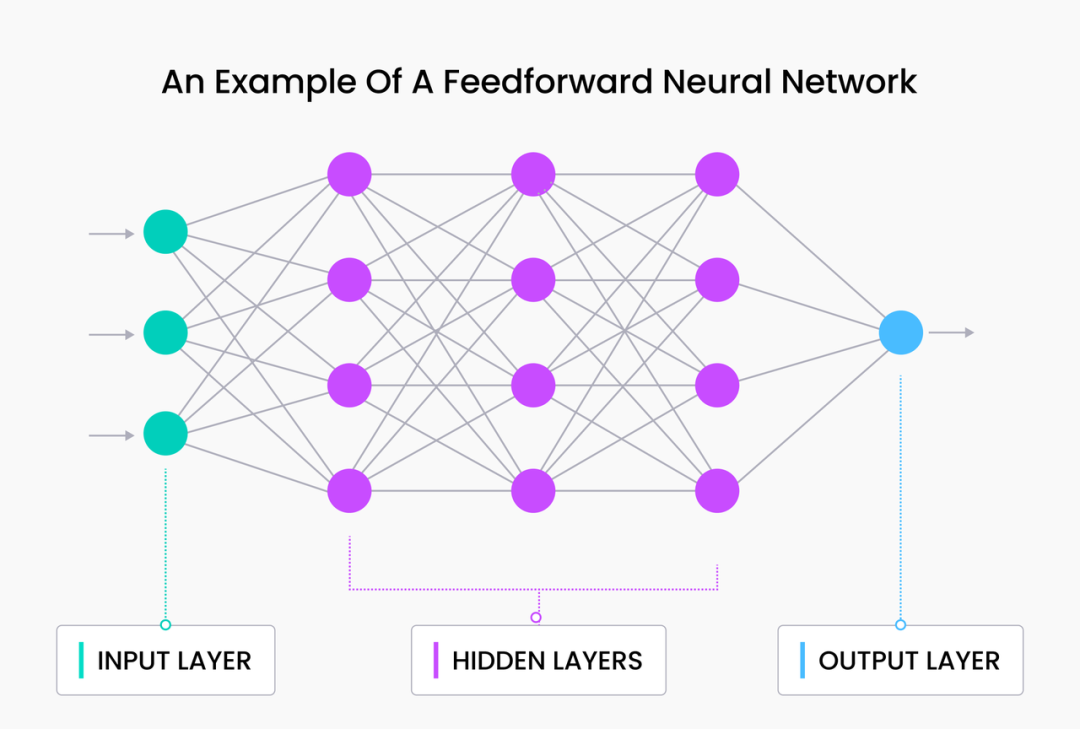
这里我们引入了一个新的隐藏层 h1,它既没有直接连接到输入 x ,也没有直接连接到输出 y 。这一层有效地增加了网络的深度,增加了总的参数数量(多个权重矩阵 w )。此时,需要注意:随着添加的隐藏层增多,靠近输入层的隐藏值(激活值)与 x 更“相似”,而靠近输出的激活值则与 y 更相似。
我们在后续的文章中将基于这个原则探讨 Embedding 向量。隐藏层的概念对理解向量搜索至关重要。
前馈网络中单个神经元的参数可以通过一个称为反向传播的过程进行更新,本质上就是微积分中链式法则的重复应用。大家可以搜索一些专门讲解反向传播的课程,这些课程会介绍反向传播为什么对训练神经网络如此有效。这里我们不多做赘述,其基本过程如下所示:
-
通过神经网络输入一批数据。
-
计算损失。这通常是回归的 L2 损失(平方差)和分类的交叉熵损失。
-
使用这个损失来计算与最后一个隐藏层权重的损失梯度 ∂ Λ ∂ W n 。
-
计算通过最后一个隐藏层的损失,即 ∂ Λ ∂ h n − 1 。
-
将这个损失反向传播到倒数第二个隐藏层的权重 ∂ Λ ∂ W n − 1 。
-
重复步骤 4 和 5,直到计算出所有权重的偏导数。
在计算出与网络中所有权重相关的损失的偏导数后,可以根据优化器和学习率进行一次大规模的权重更新。这个过程会重复进行,直到模型达到收敛或所有轮次都完成。
02.循环神经网络
所有形式的文本和自然语言本质上都是顺序性的,也就是说单词 /Token 是一个接一个地处理的。看似简单的变化,比如增加一个单词、颠倒两个连续的 Token,或增加标点符号,都可能导致解释上的巨大差异。例如,“let's eat, Charles”和“let's eat Charles”两个短语完全是两回事。由于自然语言具备顺序性这一特性,因此循环神经网络(RNNs)是自然而然成为了语言建模的不二之选。
递归是一种独特的递归形式,其中函数是神经网络而不是代码。RNN 还有着生物学起源——人类大脑可以类比为一个(人工)神经网络,我们输入的单词或说出的话语都是生物学处理的结果。
RNN 由两个组成部分:1)一个标准的前馈网络和2)一个递归组件。前馈网络与我们在前一节中讨论的相同。对于递归组件,最后一个隐藏状态被反馈到输入中,以便网络可以保持先前的上下文。因此,先前的知识(以前一个时间步的隐藏层的形式)在每一个新的时间步被注入网络。
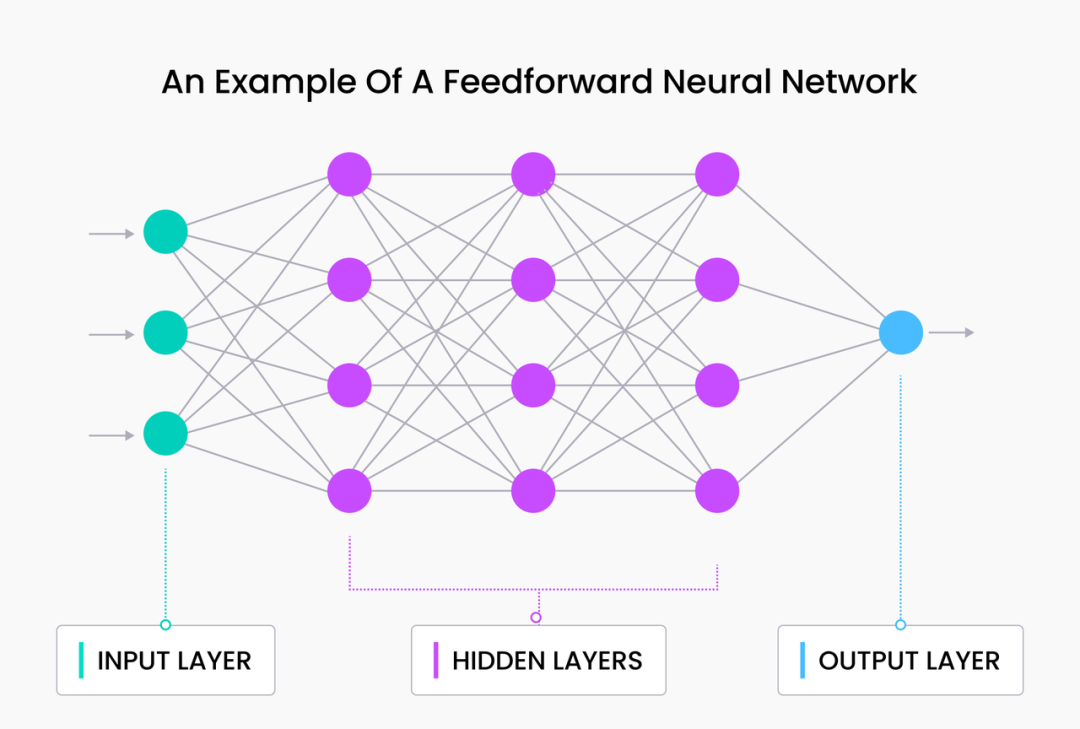
基于上述对 RNN 的宏观定义和解释,我们可以大致了解其实现方式以及为什么 RNN 在语义建模时表现良好。
首先,RNN 的循环结构使它们能够根据顺序捕捉和处理数据,其数据处理方式类似于人类说话、阅读和写作方式。此外,RNN 还可以有效访问来自较早时间的“信息”,比 n-gram 模型和纯前馈网络更能理解自然语言。
大家可以试试用 PyTorch 来实现一个 RNN。注意,这需要对 PyTorch 基础有深入的理解;如果对 PyTorch 还不太熟悉 ,建议大家先阅读该链接。
首先定义一个简单的前馈网络,然后将其扩展为一个简单的 RNN,先定义层:
from torch import Tensor
import torch.nn as nn
class BasicNN(nn.Module):
def __init__(self, in_dims: int, hidden_dims: int, out_dims: int):
super(BasicNN, self).__init__()
self.w0 = nn.Linear(in_dims, hidden_dims)
self.w1 = nn.Linear(hidden_dims, out_dims)
注意,由于我们仅仅输出原始的逻辑值,我们还没有定义损失的样式。在训练时,可以根据实际情况加上某种标准,比如 nn.CrossEntropyLoss。
现在,我们可以实现前向传递:
def forward(self, x: Tensor):
h = self.w0(x)
y = self.w1(h)
return y
这两段代码片段结合在一起形成了一个非常基础的前馈神经网络。为了将其变成 RNN,我们需要从最后一个隐藏状态添加一个反馈回路回到输入:
def forward(self, x: Tensor, h_p: Tensor):
h = self.w0(torch.cat(x, h_p))
y = self.w1(h)
return (y, h)
上述基本上就是全部步骤。由于我们现在增加了由 w0 定义的神经元层的输入数量,我们需要在 __init__中更新它的定义。现在让我们来完成这个操作,并将所有内容整合到一个代码片段中:
import torch.nn as nn
from torch import Tensor
class SimpleRNN(nn.Module):
def __init__(self, in_dims: int, hidden_dims: int, out_dims: int):
super(RNN, self).__init__()
self.w0 = nn.Linear(in_dims + hidden_dims, hidden_dims)
self.w1 = nn.Linear(hidden_dims, out_dims)
def forward(self, x: Tensor, h_p: Tensor):
h = self.w0(torch.cat(x, h_p))
y = self.w1(h)
return (y, h)
在每次前向传递中,隐藏层h的激活值与输出一起返回。这些激活值随后可以与序列中的每个新 Token一起再次传回模型中。这样一个过程如下所示(以下代码仅作示意):
model = SimpleRNN(n_in, n_hidden, n_out)
...
h = torch.zeros(1, n_hidden)
for token in range(seq):
(out, h) = model(token, )
至此,我们成功定义了一个简单的前馈网络,并将其扩展为一个简单的 RNN。
03.语言模型 Embedding
我们在上面例子中看到的隐藏层有效地将已经输入到 RNN 的所有内容(所有 Token)进行编码。更具体而言,所有解析 RNN 已看到的文本所需的信息应包含在激活值 h 中。换句话说,h 编码了输入序列的语义,而由 h 定义的有序浮点值集合就是 Embedding 向量,简称为 Embedding。
这些向量表示广泛构成了向量搜索和向量数据库的基础。尽管当今自然语言的 Embedding 是由另一类称为 Transformer 的机器学习模型生成的,而不是 RNN,但本质概念基本相同:将文本内容编码为计算机可理解的 Embedding 向量。我们将在下一篇博客文章中详细讨论如何使用 Embedding 向量。
04.总结
我们在 PyTorch 中实现了一个简单的循环神经网络,并简要介绍了语言模型Embedding。虽然循环神经网络是理解语言的强大工具,并且可以广泛应用于各种应用中(机器翻译、分类、问答等),但它们仍然不是用于生成 Embedding 向量的 ML 模型类型。
在接下来的教程中,我们将使用开源的 Transformer 模型来生成 Embedding 向量,并通过对它们进行向量搜索和运算来展示向量的强大功能。此外,我们也将回到词袋模型的概念,看看这两者如何一起用于编码词汇和语义。敬请期待!
本文由 mdnice 多平台发布