网站建设与管期末试题最近国际时事热点事件
视频资料:黑马程序员大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程
文章目录
- Map阶段执行过程
- Reduce阶段执行过程
- Python代码实现MapReduce的WordCount实例
- mapper.py
- reducer.py
- 在Hadoop HDFS文件系统中运行
Map阶段执行过程
- 把输入目录下文件按照一定的标准逐个进行
逻辑切片,每个块的默认大小为Split size = Block size(128M),不足128M的为一个块,每一个切片由一个MapTask处理。 - 对切片中的数据按照一定的规则读取解析返回
<key, value>对。 - 调用Mapper类中的map方法处理数据。每读取解析出一个<key, value>,调用一次map方法。
- 按照一定的规则对Map输出的键值对进行
分区partition。默认不分区,因为只有一个reducetask。分区的数量就是reducetask运行的数量。 - Map输出数据写入
内存缓冲区Memory Buffer,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort。默认根据key字典序排序。 - 对所有溢出文件进行最终的
合并merge,成为一个文件。

Reduce阶段执行过程
- ReduceTask会主动从MapTask
复制拉取属于需要自己处理的数据。 - 把拉取来的数据全部进行合并
merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。 - 对排序后的键值对调用reduce方法。
键相同的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
Python代码实现MapReduce的WordCount实例
首先介绍一个叫做Hadoop Streaming的工具,它能够帮助用户创建一类特殊的map/reduce作业,这些特殊的作业是由一些可执行文件或脚本文件充当mapper或者reducer。例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \-input myInputDirs \-output myOutputDir \-mapper mapper.py \-reducer reducer.py
Mapper任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入STDIN。 同时,mapper收集可执行文件进程标准输出STDOUT的内容,并把收到的每一行内容转化成key/value对,作为mapper的输出。
Reducer任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,reducer收集可执行文件进程标准输出的内容,并把每一行内容转化成key/value对,作为reducer的输出。
以下内容是代码示例:
新建文件夹WordCountTask,并在该文件夹下新建文本文档word.txt,输入以下内容:
Hello World
Hello Hadoop
Hello MapReduce
在WordCountTask文件夹下分别创建mapper.py和reducer.py两个文件:
mapper.py
#!/usr/bin/python3import sysfor line in sys.stdin:# 去除输入内容首位的空白字符line = line.strip()# 将输入内容分割为单词words = line.split()for word in words:# 将结果写到标准输出STDOUT,作为Reduce阶段代码的输入print("%s\t%s" % (word, 1))
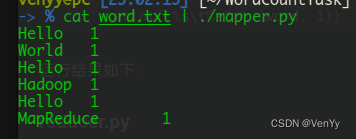
输入命令cat word.txt | ./mapper.py,运行结果如下:
reducer.py
#!/usr/bin/python3import syscurrent_word = None
current_count = 0
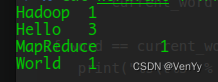
word = Nonefor line in sys.stdin:line = line.strip()word, count = line.split("\t", 1)try:count = int(count)except ValueError:continueif current_word == word:current_count += countelse:if current_word:print("%s\t%s" % (current_word, current_count))current_count = countcurrent_word = wordif word == current_word:print("%s\t%s" % (current_word, current_count))输入命令cat word.txt | ./mapper.py | sort | ./reducer.py,运行结果如下:
- 解释一下,符号
|是Linux系统中的管道符,管道符主要用于多重命令处理,前面命令的打印结果作为后面命令的输入。 sort命令用于将文本文件内容加以排序。
在Hadoop HDFS文件系统中运行
在三台虚拟机搭建的Hadoop伪分布式系统上运行刚刚写的mapper和reducer
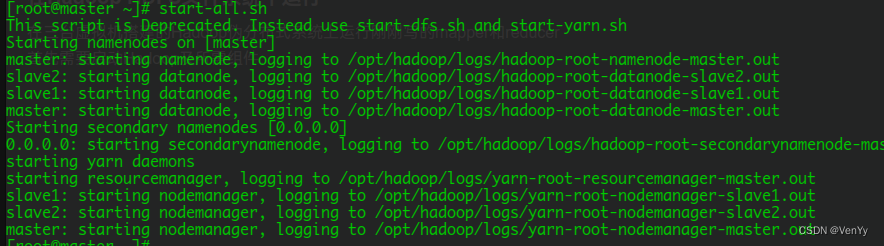
- 首先需要启动Hadoop及所需组件:
- 在HDFS文件系统根目录下新建文件夹WordCountTask,并将word.txt上传到该目录下:
[root@master ~]# hadoop fs -mkdir /WordCountTask
[root@master ~]# hadoop fs -put WordCountTask/word.txt /WordCountTask
- 运行命令:
[root@master ~]# hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar \
-input /WordCountTask/ \
-output /WordCountTask/out \
-file /root/WordCountTask/mapper.py \
-mapper /root/WordCountTask/mapper.py \
-file /root/WordCountTask/reducer.py \
-reducer /root/WordCountTask/reducer.py
- 最终程序的结果在
-output参数指定的路径中,此路径为程序自动生成,程序执行前不能有该路径。Hadoop Streaming是Hadoop自带的流处理包。程序的流程是原文本以流式方式传到Map函数,Map函数处理之后把结果传到Reduce函数,最终结果会保存在HDFS上。