重庆中环建设有限公司网站百度指数查询入口
1. ThreadLocal内存泄漏
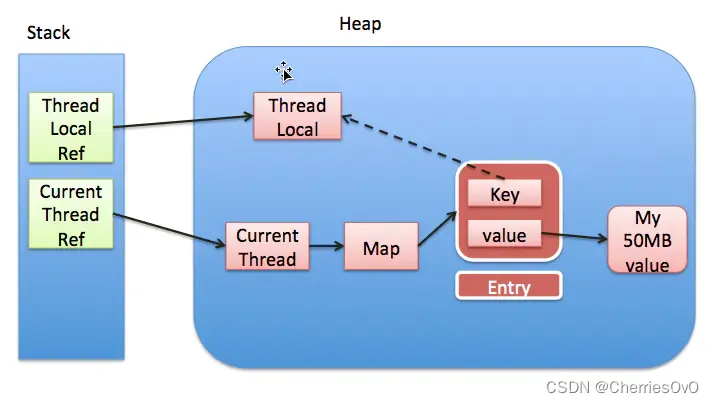
ThreadLocal 内存泄漏是指由于没有及时清理 ThreadLocal 实例所存储的数据,导致这些数据在线程池或长时间运行的应用中累积过多,最终导致内存占用过高的情况。
内存泄漏通常发生在以下情况下:
- 线程池场景下的 ThreadLocal 使用不当: 在使用线程池时,如果线程被重用而没有正确清理 ThreadLocal 中的数据,那么下次使用这个线程时,它可能会携带上一次执行任务所遗留的数据,从而导致数据累积并消耗内存。
- 长时间运行的应用中未清理 ThreadLocal 数据: 在一些长时间运行的应用中,比如 Web 应用,可能会创建很多 ThreadLocal 实例并存储大量数据。如果这些数据在使用完后没有及时清理,就会导致内存泄漏问题。
- 没有使用
remove()方法清理 ThreadLocal 数据: 在使用完 ThreadLocal 存储的数据后,如果没有调用remove()方法清理数据,就会导致数据长时间存在于 ThreadLocal 中,从而可能引发内存泄漏。
实线代表强引用,虚线代表弱引用
每一个Thread维护一个ThreadLocalMap, key为使用弱引用的ThreadLocal实例,value为线程变量的副本。
强引用,使用最普遍的引用,一个对象具有强引用,不会被垃圾回收器回收。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不回收这种对象。
如果想取消强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样可以使JVM在合适的时间就会回收该对象。
弱引用,JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。
2. 文章详情
2.1 接口说明
接口url:/articles/view/{id}
请求方式:POST
请求参数:
| 参数名称 | 参数类型 | 说明 |
|---|---|---|
| id | long | 文章id(路径参数) |
返回数据:
{"success": true,"code": 200,"msg": "success","data": "token"
}
2.2 涉及到的表
CREATE TABLE `blog`.`ms_article_body` (`id` bigint(0) NOT NULL AUTO_INCREMENT,`content` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL,`content_html` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NULL,`article_id` bigint(0) NOT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `article_id`(`article_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 38 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
package com.cherriesovo.blog.dao.pojo;import lombok.Data;@Data
public class ArticleBody { //文章详情表private Long id;private String content;private String contentHtml;private Long articleId;
}
#文章分类
CREATE TABLE `blog`.`ms_category` (`id` bigint(0) NOT NULL AUTO_INCREMENT,`avatar` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,`category_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,`description` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
package com.cherriesovo.blog.dao.pojo;import lombok.Data;@Data
public class Category {private Long id;private String avatar;private String categoryName;private String description;
}
2.3 Controller
//json数据进行交互
@RestController
@RequestMapping("articles")
public class ArticleController {/** 通过id获取文章* */@PostMapping("view/{id}")//@PathVariable("id") 注解用于将 URL 中的 {id} 赋值给 articleId 参数。public Result findArticleById(@PathVariable("id") Long articleId) { return articleService.findArticleById(articleId);}
}2.4 Service
ArticleVo findArticleById(Long id);
public interface ArticleService {//查看文章详情Result findArticleById(Long articleId);
}package com.cherriesovo.blog.vo;import lombok.Data;import java.util.List;@Data
public class ArticleVo {private Long id;private String title;private String summary;private int commentCounts;private int viewCounts;private int weight;/*** 创建时间*/private String createDate;private String author;private ArticleBodyVo body;private List<TagVo> tags;private CategoryVo category;}
@Service
public class ArticleServiceImpl implements ArticleService {@Autowiredprivate ArticleMapper articleMapper;@Autowiredprivate TagService tagService;@Autowiredprivate SysUserService sysUserService;@Autowiredprivate CategoryService categoryService;public ArticleVo copy(Article article,boolean isAuthor,boolean isBody,boolean isTags,boolean isCategory){ArticleVo articleVo = new ArticleVo();BeanUtils.copyProperties(article, articleVo);articleVo.setCreateDate(new DateTime(article.getCreateDate()).toString("yyyy-MM-dd HH:mm"));//并不是所有的接口都需要标签,作者信息if(isTags){Long articleId = article.getId();articleVo.setTags(tagService.findTagsByArticleId(articleId));}if(isAuthor){Long authorId = article.getAuthorId();//getNickname()用于获取某个对象或实体的昵称或别名articleVo.setAuthor(sysUserService.findUserById(authorId).getNickname());}if (isBody){Long bodyId = article.getBodyId();articleVo.setBody(findArticleBodyById(bodyId));}if (isCategory){Long categoryId = article.getCategoryId();articleVo.setCategory(categoryService.findCategoryById(categoryId));}return articleVo;}private List<ArticleVo> copyList(List<Article> records,boolean isAuthor,boolean isBody,boolean isTags) {List<ArticleVo> articleVoList = new ArrayList<>();for (Article article : records) {ArticleVo articleVo = copy(article,isAuthor,false,isTags,false);articleVoList.add(articleVo);}return articleVoList;}private List<ArticleVo> copyList(List<Article> records,boolean isAuthor,boolean isBody,boolean isTags,boolean isCategory) {List<ArticleVo> articleVoList = new ArrayList<>();for (Article article : records) {ArticleVo articleVo = copy(article,isAuthor,isBody,isTags,isCategory);articleVoList.add(articleVo);}return articleVoList;}@Autowiredprivate ArticleBodyMapper articleBodyMapper;private ArticleBodyVo findArticleBodyById(Long bodyId) {ArticleBody articleBody = articleBodyMapper.selectById(bodyId);ArticleBodyVo articleBodyVo = new ArticleBodyVo();articleBodyVo.setContent(articleBody.getContent());//setContent()是articleBodyVo的set方法return articleBodyVo;}@Overridepublic List<ArticleVo> listArticlesPage(PageParams pageParams) {// 分页查询article数据库表QueryWrapper<Article> queryWrapper = new QueryWrapper<>();Page<Article> page = new Page<>(pageParams.getPage(),pageParams.getPageSize());Page<Article> articlePage = articleMapper.selectPage(page, queryWrapper);List<ArticleVo> articleVoList = copyList(articlePage.getRecords(),true,false,true);return articleVoList;}@Overridepublic Result hotArticle(int limit) {LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.orderByDesc(Article::getViewCounts); //根据浏览量倒序queryWrapper.select(Article::getId,Article::getTitle);queryWrapper.last("limit " + limit);//select id,title from article order by view_counts desc limit 5List<Article> articles = articleMapper.selectList(queryWrapper);return Result.success(copyList(articles,false,false,false));}@Overridepublic Result newArticles(int limit) {LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.orderByDesc(Article::getCreateDate);queryWrapper.select(Article::getId,Article::getTitle);queryWrapper.last("limit "+limit);//select id,title from article order by create_date desc limit 5List<Article> articles = articleMapper.selectList(queryWrapper);return Result.success(copyList(articles,false,false,false));}@Overridepublic Result listArchives() {List<Archives> archivesList = articleMapper.listArchives();return Result.success(archivesList);}@Overridepublic Result findArticleById(Long articleId) {/** 1、根据id查询文章信息* 2、根据bodyId和categoryId去做关联查询* */Article article = this.articleMapper.selectById(articleId);ArticleVo articleVo = copy(article, true, true, true,true);return Result.success(articleVo);}
}
package com.cherriesovo.blog.vo;import lombok.Data;@Data
public class CategoryVo {private Long id;private String avatar;private String categoryName;
}
package com.cherriesovo.blog.vo;import lombok.Data;@Data
public class ArticleBodyVo {private String content;
}package com.cherriesovo.blog.service;import com.cherriesovo.blog.vo.CategoryVo;import java.util.List;public interface CategoryService {CategoryVo findCategoryById(Long categoryId);
}@Service
public class CategoryServiceImpl implements CategoryService {@Autowiredprivate CategoryMapper categoryMapper;@Overridepublic CategoryVo findCategoryById(Long categoryId) {Category category = categoryMapper.selectById(categoryId);CategoryVo categoryVo = new CategoryVo();BeanUtils.copyProperties(category,categoryVo);return categoryVo;}
}
package com.cherriesovo.blog.dao.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.cherriesovo.blog.dao.pojo.ArticleBody;public interface ArticleBodyMapper extends BaseMapper<ArticleBody> {
}package com.cherriesovo.blog.dao.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.cherriesovo.blog.dao.pojo.Category;public interface CategoryMapper extends BaseMapper<Category> {
}2.5 测试
3. 使用线程池 更新阅读次数
3.1 线程池配置
taskExecutor是一个线程池对象,在这段代码中通过@Bean("taskExecutor")注解定义并配置了一个线程池,并将其命名为 “taskExecutor”。asyncServiceExecutor()方法是一个Bean方法,用于创建并配置一个线程池,并以taskExecutor作为 Bean 的名称。ThreadPoolTaskExecutor是 Spring 框架提供的一个实现了Executor接口的线程池- 在方法中创建了一个
ThreadPoolTaskExecutor实例executor,并对其进行了一系列配置:
setCorePoolSize(5): 设置核心线程数为 5,即线程池在空闲时会保持 5 个核心线程。setMaxPoolSize(20): 设置最大线程数为 20,即线程池中允许的最大线程数量。setQueueCapacity(Integer.MAX_VALUE): 配置队列大小为整数的最大值,即任务队列的最大容量。setKeepAliveSeconds(60): 设置线程活跃时间为 60 秒,即线程在空闲超过该时间后会被销毁。setThreadNamePrefix("CherriesOvO博客项目"): 设置线程名称的前缀为 “CherriesOvO博客项目”。setWaitForTasksToCompleteOnShutdown(true): 设置在关闭线程池时等待所有任务结束。initialize(): 执行线程池的初始化。- 最后,将配置好的线程池返回为一个
ExecutorBean,供其他组件使用。
package com.cherriesovo.blog.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.concurrent.Executor;@Configuration
@EnableAsync //开启多线程
public class ThreadPoolConfig {@Bean("taskExecutor")public Executor asyncServiceExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();// 设置核心线程数executor.setCorePoolSize(5);// 设置最大线程数executor.setMaxPoolSize(20);//配置队列大小executor.setQueueCapacity(Integer.MAX_VALUE);// 设置线程活跃时间(秒)executor.setKeepAliveSeconds(60);// 设置默认线程名称executor.setThreadNamePrefix("CherriesOvO博客项目");// 设置等待所有任务结束后再关闭线程池executor.setWaitForTasksToCompleteOnShutdown(true);//执行初始化executor.initialize();return executor;}
}
3.1 使用
通过
@Async("taskExecutor")注解,该方法标记为异步执行,并指定了使用名为 “taskExecutor” 的线程池。
articleMapper.update(articleUpdate, updateWrapper)是一个 MyBatis-Plus 中的更新操作,用于更新数据库中的文章记录。
update方法接受两个参数:
articleUpdate:表示需要更新的文章对象,其中包含了新的阅读量。updateWrapper:表示更新条件,即确定哪些文章需要被更新的条件。这段代码通过
Thread.sleep(5000)方法在当前线程中休眠了5秒钟。这样做的目的是为了模拟一个耗时操作,以展示在异步线程中执行的任务不会影响到主线程的执行。
package com.cherriesovo.blog.service;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.cherriesovo.blog.dao.mapper.ArticleMapper;
import com.cherriesovo.blog.dao.pojo.Article;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;@Component
public class ThreadService {//期望此操作在线程池中执行,不会影响原有的主线程@Async("taskExecutor")public void updateArticleViewCount(ArticleMapper articleMapper, Article article){int viewCounts = article.getViewCounts();Article articleUpdate = new Article();articleUpdate.setViewCounts(viewCounts + 1);LambdaQueryWrapper<Article> updateWrapper = new LambdaQueryWrapper<>();updateWrapper.eq(Article::getId,article.getId());//设置一个 为了在多线程环境下 线程安全updateWrapper.eq(Article::getViewCounts,article.getViewCounts());//update article set view_count=? where view_count=? and id=?articleMapper.update(articleUpdate,updateWrapper);try {//睡眠5秒 证明不会影响主线程的使用,5秒后数据才会出现Thread.sleep(5000);
// System.out.println("更新完成了");} catch (InterruptedException e) {e.printStackTrace();}}
}@Service
public class ArticleServiceImpl implements ArticleService {@Autowiredprivate ThreadService threadService;@Overridepublic Result findArticleById(Long articleId) {/** 1、根据id查询文章信息* 2、根据bodyId和categoryId去做关联查询* */Article article = this.articleMapper.selectById(articleId);ArticleVo articleVo = copy(article, true, true, true,true);//查看完文章了,新增阅读数,有没有问题?//查看完文章之后,本应该直接返回数据了,这时候做了一个更新操作,更新时加写锁,阻塞其他读操作,性能比较低//更新增加此时接口的耗时,如果一旦更新出问题,不能影响查看文章的操作//线程池 可以把更新操作扔到线程池中去执行,和主线程就不相关了threadService.updateArticleViewCount(articleMapper,article);return Result.success(articleVo);}
}3.3 测试
- 2、根据bodyId和categoryId去做关联查询
* */
Article article = this.articleMapper.selectById(articleId);
ArticleVo articleVo = copy(article, true, true, true,true);
//查看完文章了,新增阅读数,有没有问题?
//查看完文章之后,本应该直接返回数据了,这时候做了一个更新操作,更新时加写锁,阻塞其他读操作,性能比较低
//更新增加此时接口的耗时,如果一旦更新出问题,不能影响查看文章的操作
//线程池 可以把更新操作扔到线程池中去执行,和主线程就不相关了
threadService.updateArticleViewCount(articleMapper,article);
return Result.success(articleVo);
}
}
## 3.3 测试睡眠 ThredService中的方法 5秒,不会影响主线程的使用,即文章详情会很快的显示出来,不受影响