中企动力邮箱手机登录整站优化系统
python-批量下载某短视频平台音视频标题、评论数、点赞数
- 前言
- 一、获取单个视频信息
- 1、获取视频 url
- 2、发送请求
- 3、数据解析
- 二、批量获取数据
- 1、批量导入地址
- 2、批量导出excel文件
- 3、批量存入mysql数据库
- 三、完整代码
前言
1、Cookie中文名称为小型文本文件,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。
2、有时也用其复数形式Cookies,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
3、dy核心的cookies是sessionID值, 可嵌套到接口的headers里的Cookie里进行请求。
一、获取单个视频信息
1、获取视频 url
2、发送请求
接下来就是简单的发送请求,唯一需要注意的一点就是 headers 中除了要配置 User-Agent外,还要配置 cookie 信息,否则拿不到想要的数据,cookie 位置在下图
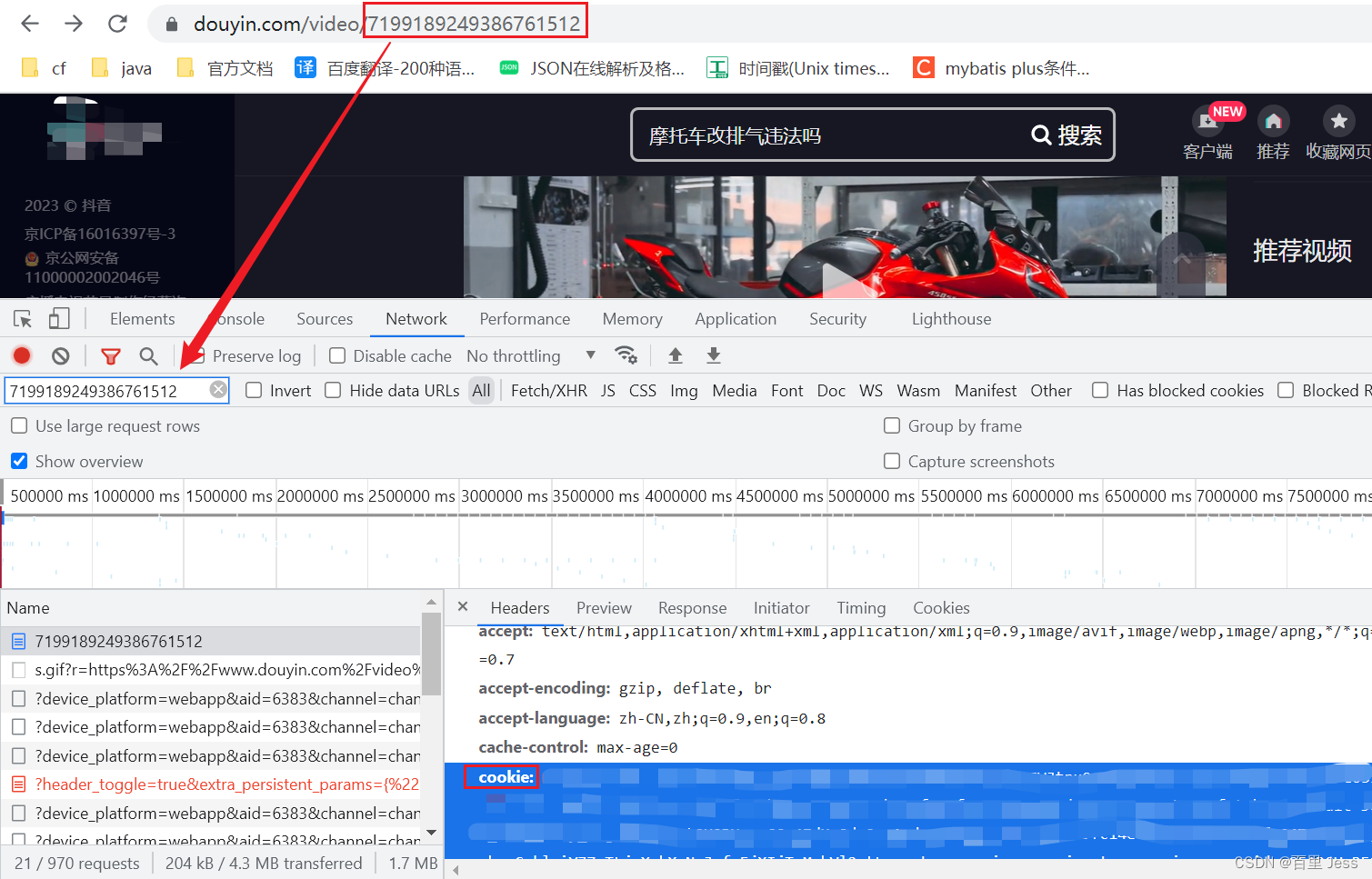
配置好 headers 之后,发送 get 请求,拿到页面源码数据
data = requests.get(url=url, headers=headers)
data.encoding = 'utf-8'
data = data.text
3、数据解析
在页面源码数据中有很长一串数据是经过 url 编码的,而我们需要的数据都在这串数据中,因此我们需要拿到这串数据。通过正则表达式定位并取出这串数据,然后调用 requests 模块下的工具包 utils 里的 unquote 方法解码这串数据(得到的是 string 类型的数据),代码如下:
data_en = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script></head><body >',data)[0]
data_all = requests.utils.unquote(data_en)
后面就是经典的资源定位了,先在数据中找到该视频的评论数,点赞数

编写正则表达式将其取出
# 点赞数
diggCount = re.findall('"diggCount":(.*?),"shareCount"', data_all)[0]
# 评价数
commentCount = re.findall('"commentCount":(.*?),', data_all)[0]
标题与点赞数评论数类似,只是位置不同
# 标题
title = re.findall('"desc":"(.*?)","authorUserId"', data_all)[0].replace(' ', '')
二、批量获取数据
1、批量导入地址
excel文件保存需获取的视频地址

导入excel表格,读取数据
# 导入excel表格
df = pandas.read_excel('文件名.xlsx', header=0) # 导入URL信息
urls = df.iloc[:, 1]
2、批量导出excel文件
需导出数据存入字典中,根据字典创建DataFrame文件后进行导出
# 导出excel表格
dataframe = pd.DataFrame({'地址': urls, '标题': titleList, '发布时间': createTimeList, '点赞数': diggCountList, '评价数': commentCountList})
with pd.ExcelWriter(str(date.today()) + 'dy.xlsx') as writer:dataframe.to_excel(writer, sheet_name='Sheet1', index=False)
3、批量存入mysql数据库
mysql数据库新建表
CREATE TABLE dy_info (`dy_info_id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '信息ID',`url` VARCHAR(255) NOT NULL DEFAULT "" COMMENT '地址',`title` VARCHAR(100) NOT NULL DEFAULT "" COMMENT '标题',`create_time` VARCHAR(20) NOT NULL DEFAULT "" COMMENT '发布时间',`digg_count` INT NOT NULL DEFAULT 0 COMMENT '点赞数',`comment_count` INT NOT NULL DEFAULT 0 COMMENT '评价数',`create_tm` TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',`update_tm` TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间',PRIMARY KEY (`dy_info_id`)
)ENGINE=INNODB COMMENT='信息表';
通过python向mysql插入大量数据时,可以有两种方法:
1、for + cursor.execute(sql),最后集中提交(commit())
2、cursor.executemany(sql,list)
两种方法效率上和功能上有一定差异。26万条数据,使用第一种方法需要约1.5小时,使用第二种方法只需要10几秒。
在这里我们使用第二种方法:
# 批量写入数据库
# 打开数据库连接
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='', #填入你的密码db='dy',charset='utf8')sql = 'INSERT INTO `dy_info`(url, title, create_time, digg_count, comment_count) VALUES(%s, %s, %s, %s, %s)'# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
cursor.executemany(sql, sqlInfo)
conn.commit() # 提交
cursor.close()
conn.close()
三、完整代码
完整代码实现