香港的网站打不开设计培训学院
郑重声明:本解读已获得论文作者的原创解读授权

文章链接:https://arxiv.org/pdf/2408.16768
在线demo: https://huggingface.co/spaces/ZiyuG/SAM2Point
code链接:https://github.com/ZiyuGuo99/SAM2Point
亮点直击
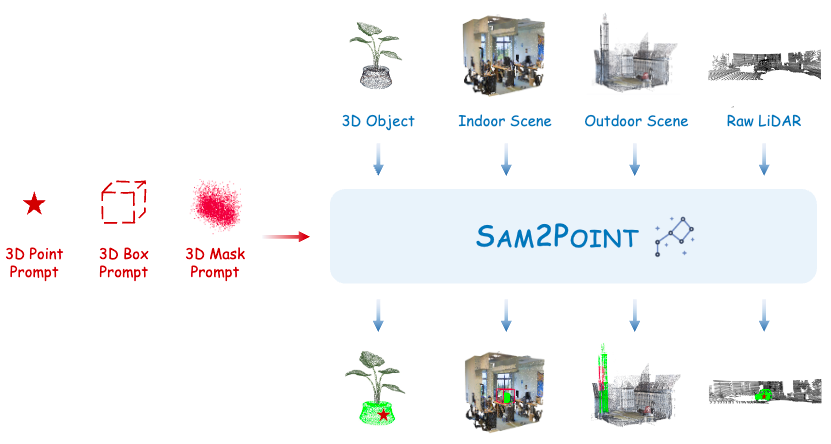
无投影 3D 分割:SAM2POINT 通过将 3D 数据体素化为视频格式,避免了复杂的 2D-3D 投影,实现了高效的零样本 3D 分割,同时保留了丰富的空间信息。
多样的提示支持:该方法支持 3D 点、3D框和mask三种提示类型,实现了灵活的交互式分割,增强了 3D 分割的精确度和适应性。
强大的泛化能力:SAM2POINT 在多种 3D 场景中表现出优越的泛化能力,包括单个物体、室内场景、室外场景和原始 LiDAR 数据,显示了良好的跨领域转移能力。
本文介绍了 SAM2POINT,这是一种初步探索,将 Segment Anything Model 2 (SAM 2) 适配于零样本和可提示的 3D 分割。SAM2POINT 将任何 3D 数据解释为一系列多方向视频,并利用 SAM 2 进行 3D 空间分割,无需进一步训练或 2D-3D 投影。框架支持多种提示类型,包括 3D 点、框和mask,并且可以在各种场景中进行泛化,例如 3D 单个物体、室内场景、室外场景和原始 LiDAR。在多个 3D 数据集上的演示,如 Objaverse、S3DIS、ScanNet、Semantic3D 和 KITTI,突出了 SAM2POINT 的强大泛化能力。据我们所知,展示了 SAM 在 3D 中的最忠实实现,这可能成为未来可提示 3D 分割研究的起点。
效果展示
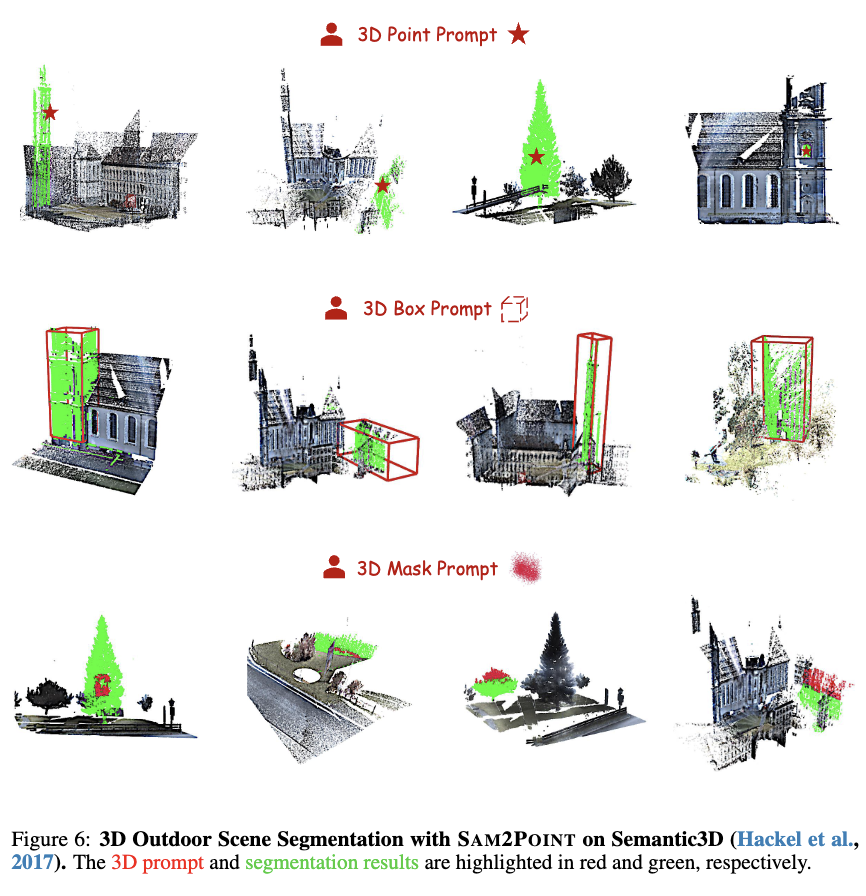
下图 3-7 展示了 SAM2POINT 在使用不同 3D 提示对不同数据集进行 3D 数据分割的演示。




SAM2POINT
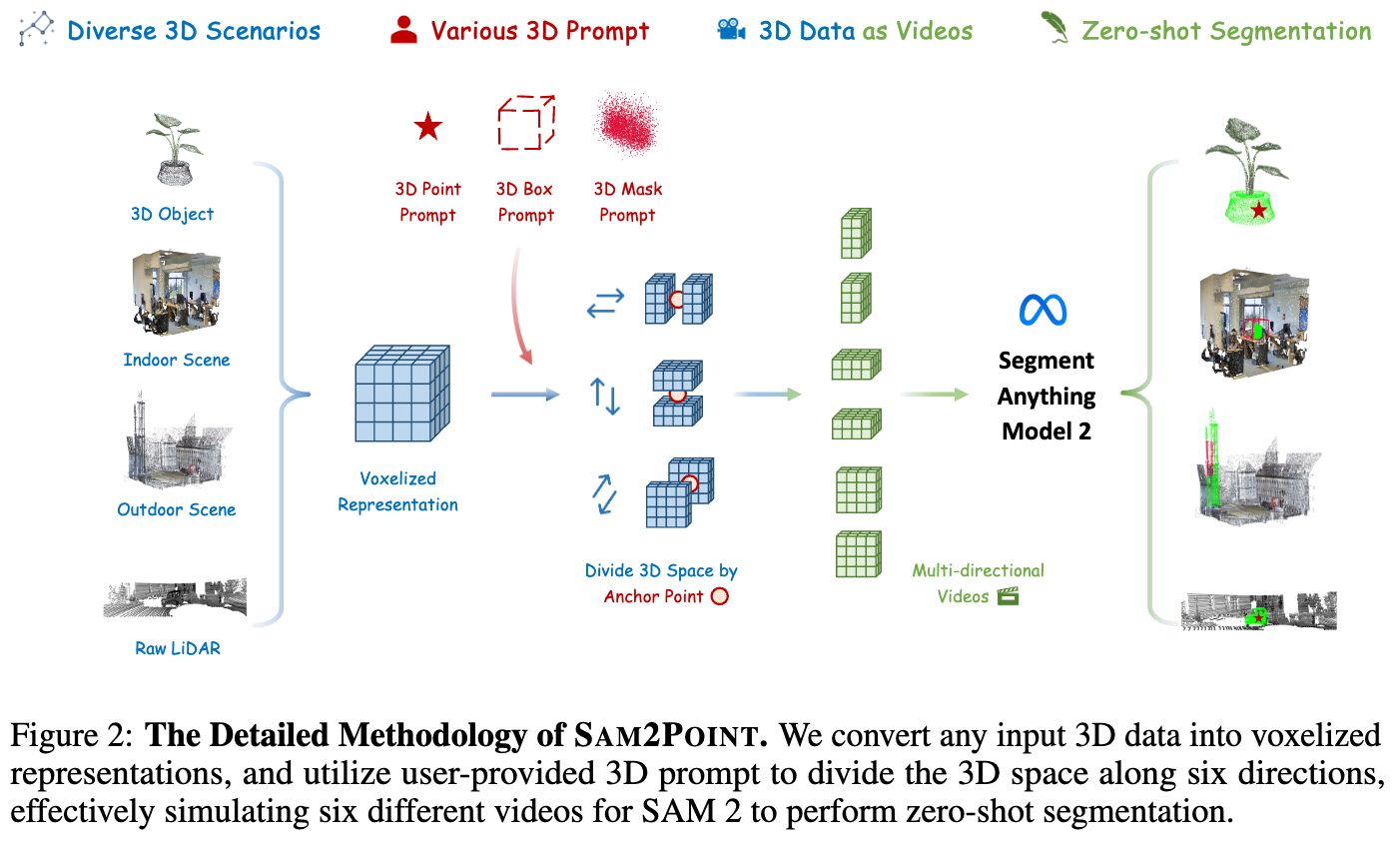
SAM2POINT 的详细方法如下图 2 所示。下面介绍了 SAM2POINT 如何高效地将 3D 数据格式化以兼容 SAM 2,从而避免复杂的投影过程。接下来,以及详细说明了支持的三种 3D 提示类型及其相关的分割技术。最后,展示了 SAM2POINT 有效解决的四种具有挑战性的 3D 场景。
3D 数据作为视频
给定任何对象级别或场景级别的点云,用 表示,其中每个点为 。本文的目标是将 转换为一种数据格式,这种格式一方面能使 SAM 2 以零样本的方式直接处理,另一方面能够很好地保留细粒度的空间几何结构。为此,我们采用了 3D 体素化技术。与 RGB 图像映射、多视角渲染和 NeRF等先前工作相比,体素化在 3D 空间中高效执行,因此避免了信息降解和繁琐的后处理。
通过这种方式,获得了 3D 输入的体素化表示,记作 ,其中每个体素为 。为了简化, 值根据距离体素中心最近的点设置。这种格式与形状为 的视频非常相似。主要区别在于,视频数据包含在 帧之间的单向时间依赖性,而 3D 体素在三个空间维度上是各向同性的。考虑到这一点,我们将体素表示转换为一系列多方向的视频,从而启发 SAM 2 以与视频相同的方式进行 3D 分割。
可提示分割
为了实现灵活的交互性,SAM2POINT 支持三种类型的 3D 提示,这些提示可以单独使用,也可以联合使用。在下文中具体说明提示和分割的细节:
-
3D 点提示,记作 。首先将 视为 3D 空间中的一个锚点,以定义三个正交的 2D 截面。然后,从这些截面开始,将 3D 体素分为沿六个空间方向的六个子部分,即前、后、左、右、上和下。接着,我们将它们视为六个不同的视频,其中截面作为第一帧, 被投影为 2D 点提示。应用 SAM 2 进行并发分割后,将六个视频的结果整合为最终的 3D mask 预测。
-
3D 框提示,记作 ,包括 3D 中心坐标和尺寸。我们采用 的几何中心作为锚点,并按照上述方法将 3D 体素表示为六个不同的视频。对于某一方向的视频,我们将 投影到相应的 2D 截面,作为分割的框点。我们还支持具有旋转角度的 3D 框,例如 ,对于这种情况,采用投影后的 的边界矩形作为 2D 提示。
-
3D mask提示,记作 ,其中 1 或 0 表示mask区域和非mask区域。使用mask提示的质心作为anchor,并类似地将 3D 空间划分为六个视频。3D mask提示与每个截面的交集被用作 2D mask提示进行分割。这种提示方式也可以作为后期精炼步骤,以提高先前预测的 3D mask的准确性。
任意 3D 场景
凭借简洁的框架设计,SAM2POINT 在各种领域中表现出优越的零样本泛化能力,从对象到场景、从室内到室外场景。在下文中详细阐述了四种不同的 3D 场景:
-
3D 单个物体,如 Objaverse,具有多种类别,具有不同实例的独特特征,包括颜色、形状和几何结构。对象的相邻组件可能会重叠、遮挡或融合,这要求模型准确识别细微差别以进行部分分割。
-
室内场景,如 S3DIS和 ScanNet,通常具有多个在封闭空间内(如房间)排列的对象。复杂的空间布局、外观相似性和对象间的不同方向给模型从背景中分割这些对象带来挑战。
-
室外场景,如 Semantic3D,与室内场景不同,主要由于对象的大小对比明显(建筑物、车辆和人)和点云的尺度更大(从一个房间到整个街道)。这些变化使得在全球尺度或细粒度水平上分割对象变得复杂。
-
原始 LiDAR,如 KITTI在自动驾驶中,与典型点云不同,其分布稀疏且缺乏 RGB 信息。稀疏性要求模型推断缺失的语义以理解场景,且缺乏颜色迫使模型仅依靠几何线索区分对象。在 SAM2POINT 中,我们直接通过 LiDAR 强度设置 3D 体素的 RGB 值。
结论
本文提出了 SAM2POINT,它利用 Segment Anything 2 (SAM 2) 实现 3D 分割,采用零样本和可提示框架。通过将 3D 数据表示为多方向视频,SAM2POINT 支持多种类型的用户提供的提示(3D 点、框和mask),并在多种 3D 场景(3D 单个物体、室内场景、室外场景和原始稀疏 LiDAR)中展示了强大的泛化能力。作为初步探索,SAM2POINT 提供了关于将 SAM 2 适配于有效和高效的 3D 理解的独特见解。希望本文的方法能够作为可提示 3D 分割的基础基准,鼓励进一步研究以充分发挥 SAM 2 在 3D 领域的潜力。
参考文献
[1]SAM2Point: Segment Any 3D as Videos in Zero-shot and Promptable Manners