做网站上凡科小网站关键词搜什么
动手学深度学习(视频):68 Transformer【动手学深度学习v2】_哔哩哔哩_bilibili
动手学深度学习(pdf):10.7. Transformer — 动手学深度学习 2.0.0 documentation (d2l.ai)
李沐Transformer论文逐段精读:Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
Vaswani, A. et al. (2017) 'Attention is all you need', 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. doi: https://doi.org/10.48550/arXiv.1706.03762
目录
1. Transformer
1.1. 整体实现步骤
1.2. Transformer理念
1.3. Transformer代码实现
1.4. Transformer弊端和局限
2. Transformer论文原文学习
2.1. Abstract
2.2. Introduction
2.3. Background
2.4. Model Architecture
2.4.1. Encoder and Decoder Stacks
2.4.2. Attention
2.4.3. Position-wise Feed-Forward Networks
2.4.4. Embeddings and Softmax
2.4.5. Positional Encoding
2.5. Why Self-Attention
2.6. Training
2.6.1. Training Data and Batching
2.6.2. Hardware and Schedule
2.6.3. Optimizer
2.6.4. Regularization
2.7. Results
2.7.1. Machine Translation
2.7.2. Model Variations
2.7.3. English Constituency Parsing
2.8. Conclusion
1. Transformer
1.1. 整体实现步骤
(1)模型图
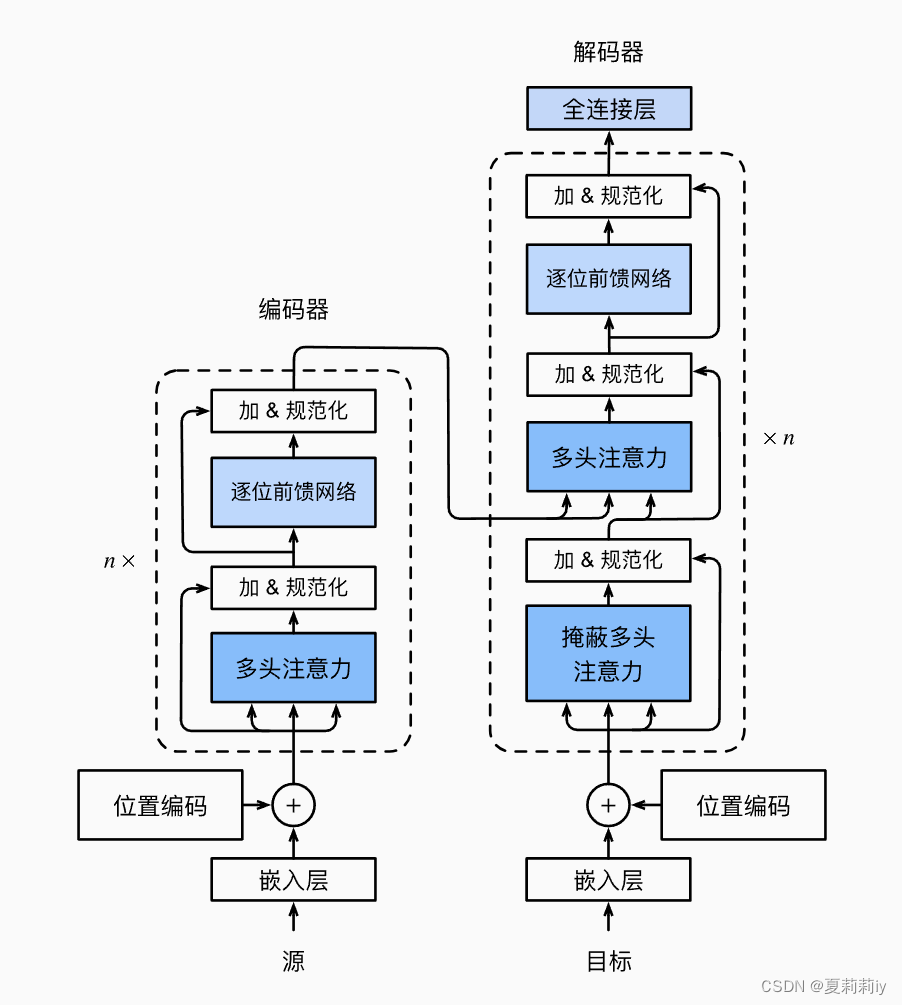
1.2. Transformer理念
(1)摒弃了传统费时的卷积和循环,仅采用注意力机制和全连接构成整个网络
(2)多使用残差连接
(3)Mask的提出
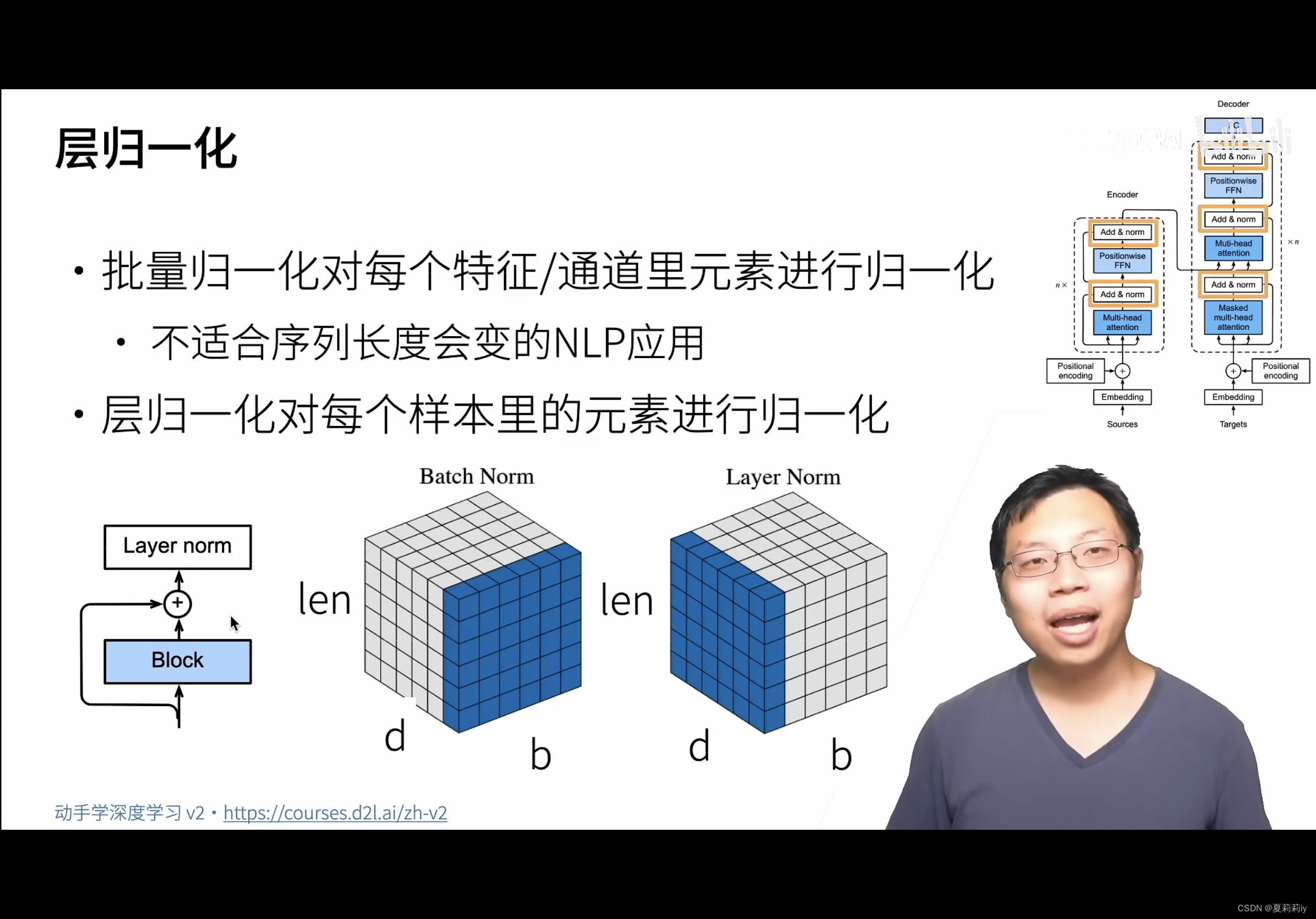
(4)李沐特地讲解了batch norm和layer norm的区别,主要是取的块不一样:
1.3. Transformer代码实现
(1)代码网址:GitHub - tensorflow/tensor2tensor: Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
(2)李沐
①Encoder
class EncoderBlock(nn.Module):"""Transformer编码器块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y))②Decoder
class DecoderBlock(nn.Module):"""解码器中第i个块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = iself.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1 = AddNorm(norm_shape, dropout)self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout)def forward(self, X, state):enc_outputs, enc_valid_lens = state[0], state[1]# 训练阶段,输出序列的所有词元都在同一时间处理,# 因此state[2][self.i]初始化为None。# 预测阶段,输出序列是通过词元一个接着一个解码的,# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示if state[2][self.i] is None:key_values = Xelse:key_values = torch.cat((state[2][self.i], X), axis=1)state[2][self.i] = key_valuesif self.training:batch_size, num_steps, _ = X.shape# dec_valid_lens的开头:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else:dec_valid_lens = None# 自注意力X2 = self.attention1(X, key_values, key_values, dec_valid_lens)Y = self.addnorm1(X, X2)# 编码器-解码器注意力。# enc_outputs的开头:(batch_size,num_steps,num_hiddens)Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state1.4. Transformer弊端和局限
(1)位置信息表示弱
(2)长距离文本学习能力弱
2. Transformer论文原文学习
2.1. Abstract
(1)Bcakground: the sequence transduction model prevails with complicated convolution or recurrence.
(2)Purpose: they put forward a simple attention model without convolution or recurrence, which not only decreases the training time, but also increases the accuracy of translation
transduction n.转导
2.2. Introduction
①Previous model: RNN, LSTM, gated RNN
②RNN limits in parallel computing in that it is highly rely on previous data
③Factorization tricks and conditional computation have made great achievement nowadays. However, reseachers are still unable to break free from the constraints of sequential computation.
④Attention mechanism can ignore the position of words
eschew vt.避免;(有意地)避开;回避
2.3. Background
①Extended Neural GPU, ByteNet and ConvS2S try reducing the sequential mechanism. However, they still explode in distance computation.
②Self-attention, also named intra-attention has been used in "reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations"
2.4. Model Architecture
①The Transformer model shows below:
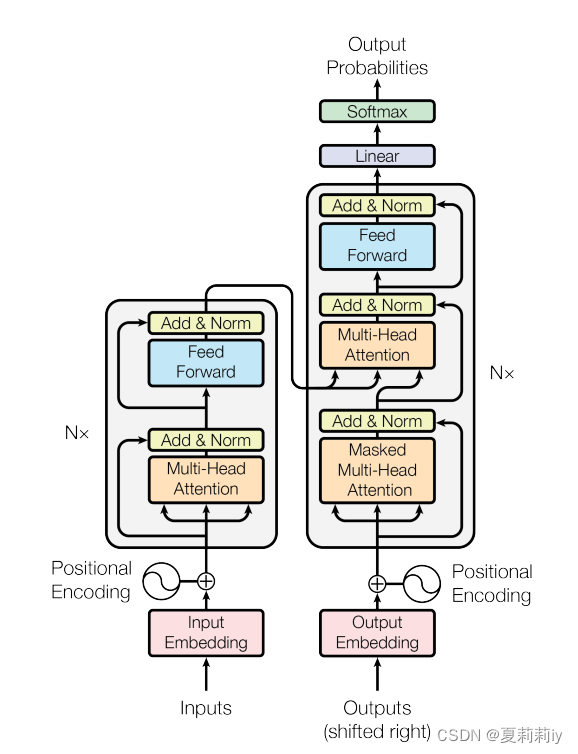
Inputs are denoted by , then encode them to
. Lastly decode
to
(⭐input sequence and output sequence may not be of equal length).
②The model is auto-regressive
③The left of this figure is encode layer, and the right halves are decoder.
2.4.1. Encoder and Decoder Stacks
(1)Encoder
①N=6
②"Add" means adding x and sublayer(x), then using layer norm
(2)Decoder
①N=6
②Masked layer ensures can only see the previous input of its position
2.4.2. Attention
(1)Scaled Dot-Product Attention
①The model shows below:
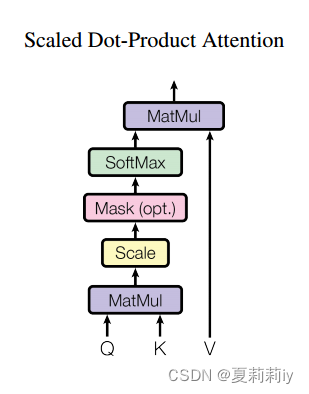
where Q denotes queries and K denotes keys of dimension , V denotes values of dimension
②The function of Scaled Dot-Product Attention:
③They set as the dividend. They reckon when
increaces, additive attention outpeforms dot product attention.
④The more the dimension is, the less gradient the softmax is. Hence they scale the dot product.
(2) Multi-Head Attention
①The model shows below:
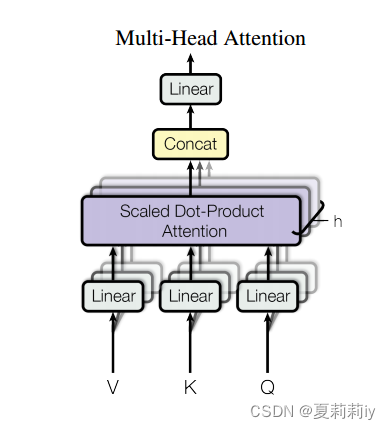
②The function of this block is:
where all the are parameter matrices. Additionally, h=8, and they set
(3)Applications of Attention in our Model
①Each position in the decoder participates in all positions in the input sequence
②Each position in the encoder can handle all positions in the previous layer of the encoder
③Mask all values on the right that have not yet appeared and represent them with (so when they participate in softmax layer, they always get 0)
2.4.3. Position-wise Feed-Forward Networks
① Function of fully connected feed-forward network:
where the input and output dimension , and the inner-layer dimension
2.4.4. Embeddings and Softmax
①The two embedding layers and the pre-softmax linear transformation are using the same weight matrix
②Table of different complexity for different layers:

where d denotes dimension, k denotes the size of convolutional kernal, n denotes length of sequence, and r is the size of the neighborhood in restricted self-attention
2.4.5. Positional Encoding
①Positional encodings:
where pos means position and i means dimension.
②They also tried learned positional embeddings, which got a similar result.
③Sinusoidal version allows longer sequence
2.5. Why Self-Attention
①Low computational complexity, parallelized computation and short path length are the advantages of self-attention
②分析了一堆时间空间复杂度吗?我不是很看得懂
2.6. Training
2.6.1. Training Data and Batching
They used WMT 2014 English-German dataset and WMT 2014 English-French dataset with 4.5 million sentence pairs and 36M sentences respectively.
2.6.2. Hardware and Schedule
By each step in 1 second, they trained 300,000 steps (about 3.5 days)
2.6.3. Optimizer
①Adam optimizer: β1 = 0.9, β2 = 0.98 and ϵ = 10−9
②Learning rate:
where warmup_steps = 4000 at the beginning
2.6.4. Regularization
①Dropout rate: 0.1
②Label smoothing value , which causes perplexity but increases accuracy and BLEU score
2.7. Results
2.7.1. Machine Translation
Comparison of accuracy with other models:
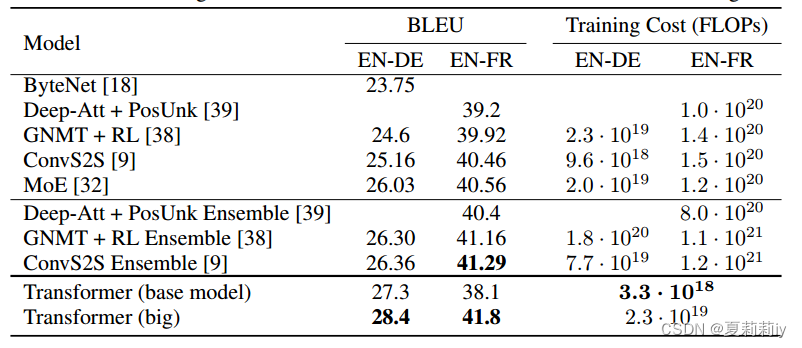
2.7.2. Model Variations
①Variations of Transformer
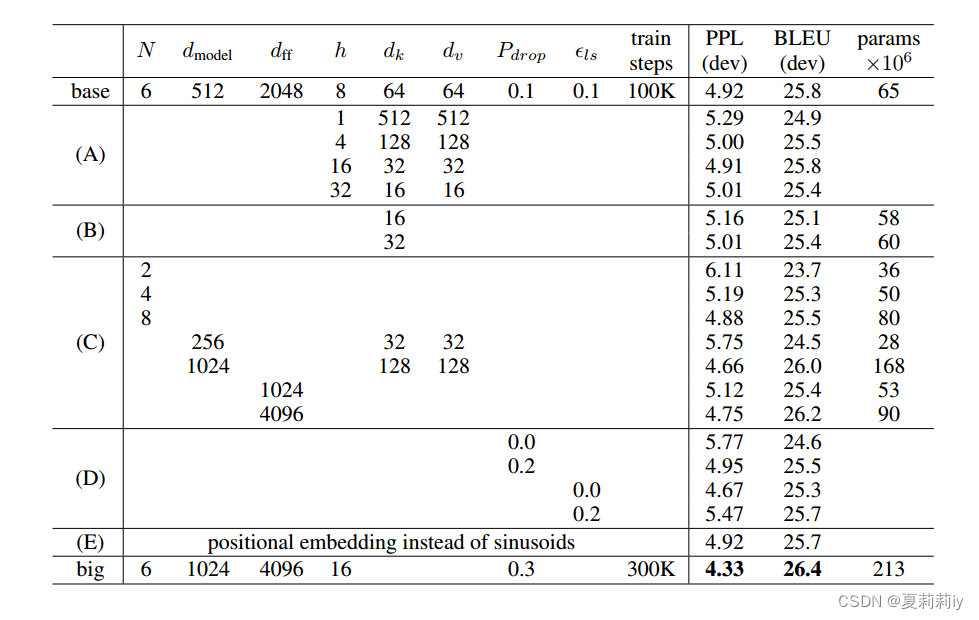
where (A) changes the number of attention heads, attention key, and dimension of value, (B) adjusts the size of attention key, (C) and (D) control model size and dropout rate, (E) replaces sinusoidal positional encoding by learned positional embeddings. These ablation studies have successfully demonstrated the superiority of Transformer.
2.7.3. English Constituency Parsing
①Comparison table of generalization performance:
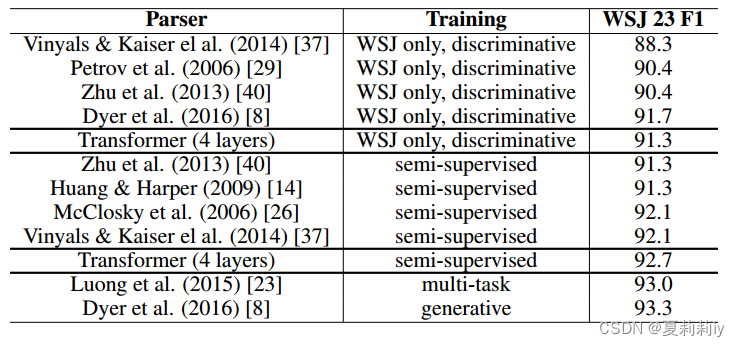
2.8. Conclusion
①This is the first model which only based on attention mechanism
②Outperforms any other previous model