网站建设流程是这样的今日国际新闻最新消息
1.数据倾斜实例
数据倾斜在MapReduce编程模型中比较常见,由于key值分布不均,大量的相同key被存储分配到一个分区里,出现只有少量的机器在计算,其他机器等待的情况。主要分为JOIN数据倾斜和GROUP BY数据倾斜。
1.1GROUP BY数据倾斜优化
1.1.1set hive.map.aggr=true
开启map之后使用combiner,在map操作之后做局部聚合。
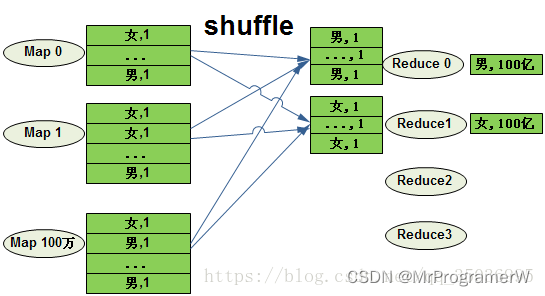
例如:在user表中有100亿条数据,按性别统计条数,select user.gender,count(1) from user group by user.gende
如果没有map端的部分聚合优化,map直接把groupby_key 当作reduce_key发送给reduce做聚合,就会导致计算不均衡的现象。虽然map有100万个,但是reduce只有两个在做聚合,每个reduce处理100亿条记录。
由于map端已经做了局部聚合,虽然还是只有两个reduce做最后的聚合,但是每个reduce只用处理100万行记录,相对优化前的100亿小了1万倍。
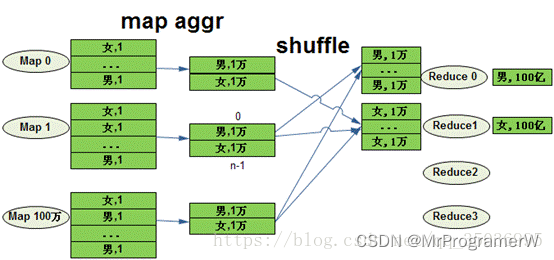
map端聚合打开map聚合开关缺省是打开的,但是不是所有的聚合都需要这个优化。因为group_by_key没有重复的map聚合没有太大意义,并且浪费资源。下面这两个参数控制关掉map聚合的策略。
set hive.groupby.mapaggr.checkinterval = 100000 (默认)尝试执行聚合的条数
set hive.map.aggr.hash.min.reduction=0.5(默认)如果hash表的容量与输入行数之比超过这个数,那么map端的hash聚合将被关闭,默认是0.5,设置为1可以保证hash聚合永不被关闭;
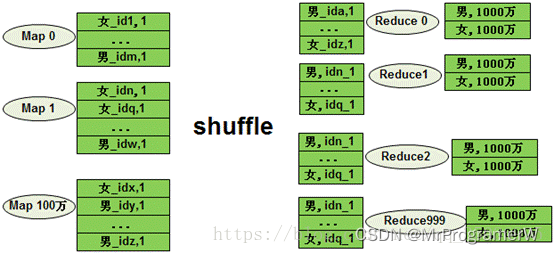
1.1.2set hive.groupby.skewindata=true
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group ByKey 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce中),最后完成最终的聚合操作。

1.2JOIN数据倾斜优化
1.2.1
如果是由于key值为空或为异常记录,且这些记录不能被过滤掉的情况下,可以考虑给key赋一个随机值,将这些值分散到不同的reduce进行处理。
1.2.2
如果是一个大表和一个小表join的话,可以考虑使用mapjoin来避免数据倾斜,mapjoin的具体过程如下。
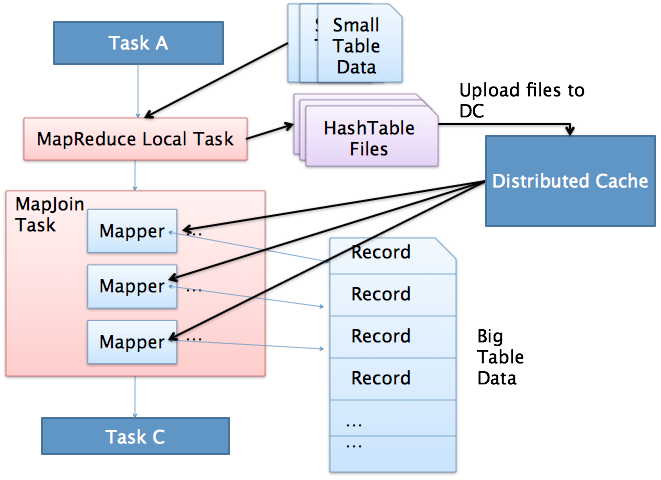
1.2.3 使用/+ MAPJOIN(smalltable)/显示声明MapJoin需要加载到内存中的小表
SELECT /*+mapjoin(b)*/ field1,field2 from a left join b
##MapJoin操作
set hive.auto.convert.join.noconditionaltask = true;#默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin
set hive.mapjoin.smalltable.filesize=100000;#大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行
set hive.ignore.mapjoin.hint = false;#默认值:true;是否忽略mapjoin hint 即mapjoin标记
set hive.auto.convert.join.noconditionaltask.size=100000;#将多个mapjoin转化为一个mapjoin时,其表的最大值
1.3大表关联大表数据倾斜
1.增加Reducer数量
2.把大表转换成小表做MapJoin
2.资源分配
2.1生产资源案例
例如生产上的某应用计算资源有3100CU,一共三个队列,两个机房,业务高峰期数据量大的业务线同时刷数会出现严重的资源不足的情况。
2.2调度策略
调度通常是一个难题,并没有一个所谓“最好”的策略,因此Yarn提供了多种调度策略;
2.2.1FIFO调度器
先到先分配资源,前一个应用执行完毕之后下一个应用开始执行。缺点是小作业很容易被阻塞,等大作业执行完毕才能执行。
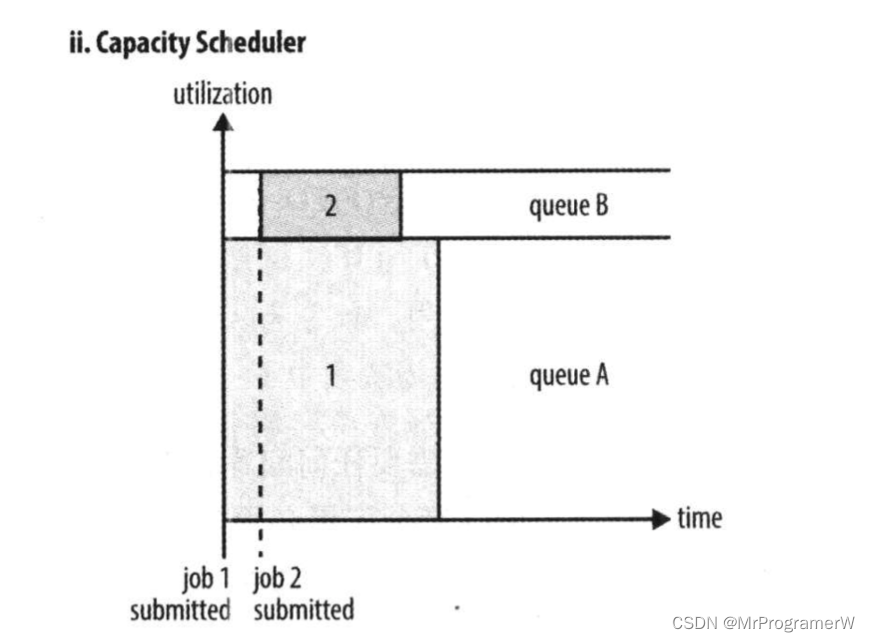
2.2.2容量调度器
容量调度器以队列为单位划分资源,每个队列都有资源使用的下限和上限。每个用户可以设定资源使用上限。管理员可以约束单个队列、用户或者作业的资源使用、支持作业优先级,但不支持抢占。如果队列中有多个作业,并且队列资源不够用了,这是如果集群仍然有空闲资源,那么容量调度器可能会将空余的资源分配给队列中的作业,哪怕是超出队列的容量,这部分队列成为“弹性队列”。
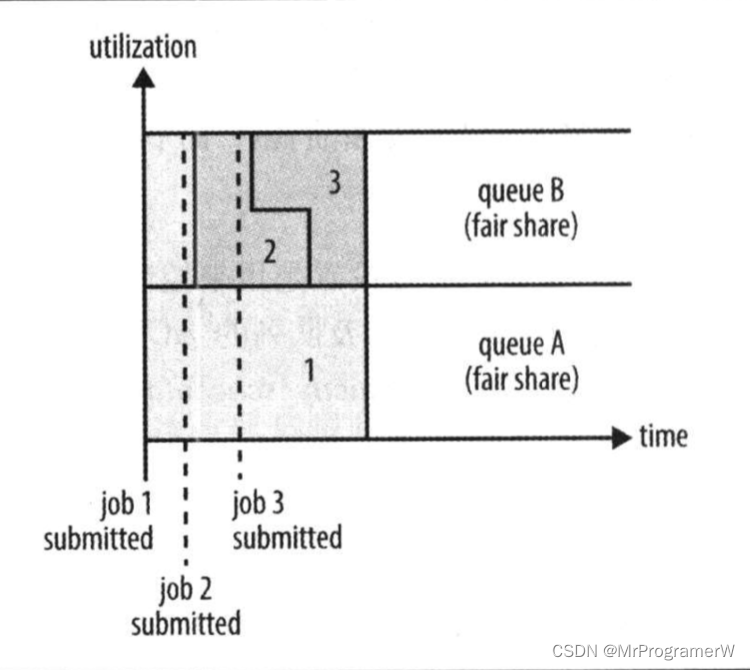
2.2.3公平调度器
想象两个队列A和B。A启动一个作业,在B没有需求时A会分配到全部可用资源;当A的作业仍在运行时B启动一个作业,一段时间后,按照我们先前看到的方式,每个作业都用到了一半的集群资源。这时,如果B启动第二个做作业且其他作业仍在运行,那么第二个作业将和B的其他作业(这里是第一个)共享资源,因此B的每个作业将占四分之一的集群资源,而A仍继续占用一半的集群资源。最终的结果就是资源在用户之间实现了公平共享。
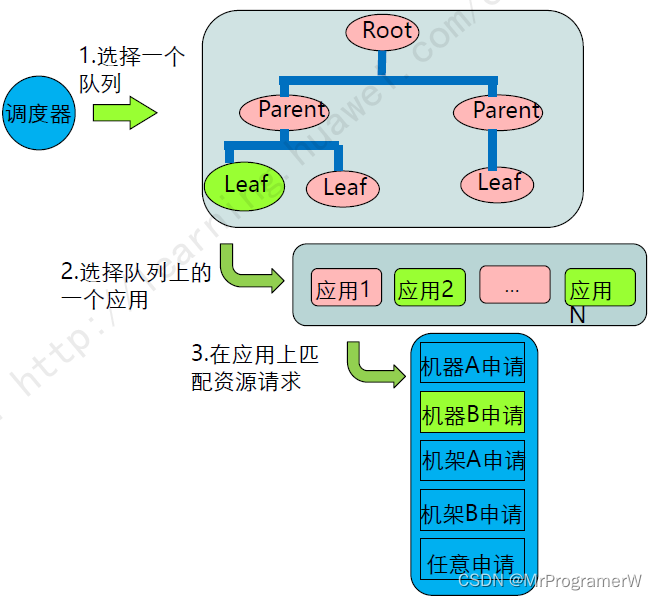
2.3机器申请
机器申请调度器会优先匹配本地资源的申请请求,其次是同机架的,最后是任意机器的。
2.4通过参数调节资源的使用
Hadoop最底层数据存储是HDFS,HDFS按文件存储,最小的存储单元是块。MapReduce输入的单位是分片,每个分片对应一个Mapper,每个Mapper或Reducer申请一个计算资源。资源申请的多少,可以通过修改输入数据的分片大小来控制。由于总体资源有限,需要控制各个阶段的申请资源数。离线表四-ETL参数优化
代码块
Python
##Map输入合并小文件
set mapred.max.split.size=256000000; ##每个Map最大输入大小 ,超过次大小进行文件拆分
set mapred.min.split.size.per.node=256000000; ##一个节点上split的至少的大小 ,每个节点上的文件小于此大小进行文件合并
set mapred.min.split.size.per.rack=256000000; ##一个交换机下split的至少的大小 ,每个交换机上小于此大小进行文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; ##一个data node节点上多个小文件会进行合并,合并文件数由mapred.max.split.size限制的大小决定
##输出合并
set hive.merge.mapfiles = true; ##在Map-only的任务结束时合并小文件 ,如果hadoop版本支持CombineFileInputFormat,则启动Map-only job for merge,否则启动 MapReduce merge job,map端combine file是比较高效的做法
set hive.merge.mapredfiles = true; ##在Map-Reduce的任务结束时合并小文件
set hive.merge.size.per.task = 128000000; ##控制每个任务合并小文件后的文件大小(默认256000000)
set hive.merge.smallfiles.avgsize=64000000; ##告诉hadoop什么样的文件属于小文件(默认16000000),这个值只有当hive.merge.mapfiles或hive.merge.mapredfiles设定为true时,才有效
##控制Reduce个数
set mapred.reduce.tasks = 1000;
set hive.exec.reducers.bytes.per.reducer=64000000;#用于设置在执行SQL的过程中每个reducer处理的最大字节数量。可以在配置文件中设置,也可以由我们在命令行中直接设置。如果处理的数据量大于,就会多生成一个reudcer。例如,number = 1024K,处理的数据是1M,就会生成10个reducer。
3.其他常见问题
3.1OOM
##Maper:
set mapred.map.child.java.opts=-Xmx2048m;#(默认参数,表示jvm堆内存)
set mapreduce.map.memory.mb=2304;#(默认参数,表示整个jvm进程占用的内存:堆内存+堆外内存=2048+256)
##Reducer:
set mapred.reduce.child.java.opts=-Xmx2048m;#(默认参数,表示jvm堆内存)
set mapreduce.reduce.memory.mb=2304;#(默认参数,表示整个jvm进程占用的内存:堆内存+堆外内存=2048+256)
##MRAppMaster:
set yarn.app.mapreduce.am.command-opts=-Xmx1024m;#(默认参数,表示jvm堆内存)
set yarn.app.mapreduce.am.resource.mb=1536;#(默认参数,表示整个jvm进程占用的内存:堆内存+堆外内存=1024+512)
3.2写文件超过10万个
平台限制写文件数不能超过10万个,distribute by顾名思义,是起分散数据作用的。distribute by col,则是按照col列为key分散到不同的reduce里去,默认采取的是hash算法。
distribute by deliver_date, source_system,source_system_table,cast(rand()*100 as int)