购买帝国cms做网站代理网站排名优化培训哪家好
PPO算法
近线策略优化算法(Proximal Policy Optimization Algorithms) 即属于AC框架下的算法,在采样策略梯度算法训练方法的同时,重复利用历史采样的数据进行网络参数更新,提升了策略梯度方法的学习效率。 PPO重要的突破就是在于对新旧新旧策略器参数进行了约束,希望新的策略网络和旧策略网络的越接近越好。 近线策略优化的意思就是:新策略网络要利用到旧策略网络采样的数据进行学习,不希望这两个策略相差特别大,否则就会学偏。PPO依然是openai在2017年提出来的,论文地址
PPO-clip的损失函数,其中损失包含三个部分:
- clip部分:加权采样后的优势值越好(可理解层价值网络的评分),同时采样通过clip防止新旧策略网络相差过大
- VF部分: 价值网络预测的价值和环境真是的回报值越接近越好
- S 部分:策略网络输出策略的熵值,越大越好,这个explore的思想,希望策略网络输出的动作分布概率不要太集中,提高了每个动作都有机会在环境中发生的可能。
实战部分
导入必要的包
%matplotlib inline
import matplotlib.pyplot as pltfrom IPython import displayimport numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
from tqdm.notebook import tqdm
准备环境
准备好openai开发的LunarLander-v2的游戏环境。
seed = 543
def fix(env, seed):env.action_space.seed(seed)torch.manual_seed(seed)np.random.seed(seed)random.seed(seed)
import gym
import random
env = gym.make('LunarLander-v2' ,render_mode='rgb_array')
fix(env, seed) # fix the environment Do not revise this !!!
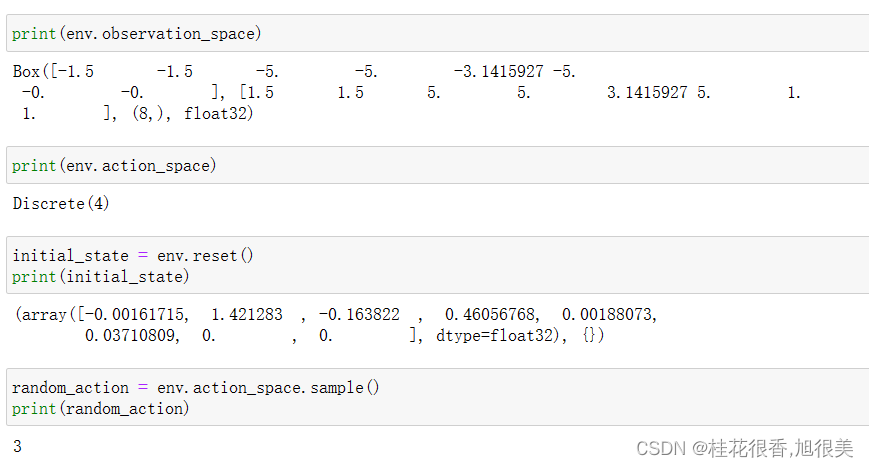
下面是采用代码去输出 环境的 观测值,一个8维向量,动作是一个标量,4选一。
- 该环境共有 8 个观测值,分别是: 水平坐标 x; 垂直坐标 y; 水平速度; 垂直速度; 角度; 角速度; 腿1触地; 腿2触地;
- 可以采取四种离散的行动,分别是: 0 代表不采取任何行动 1.代表主引擎向左喷射 2 .代表主引擎向下喷射 3 .代表主引擎向右喷射
- 环境中的 reward 大致是这样计算: 小艇坠毁得到 -100 分; 小艇在黄旗帜之间成功着地则得 100~140 分; 喷射主引擎(向下喷火)每次 -0.3 分; 小艇最终完全静止则再得 100 分
随机动作玩5把
env.reset()img = plt.imshow(env.render())done = False
rewords = []
for i in range(5):env.reset()[0]img = plt.imshow(env.render())total_reward = 0done = Falsewhile not done:action = env.action_space.sample()observation, reward, done, _ , _= env.step(action)total_reward += rewardimg.set_data(env.render())display.display(plt.gcf())display.clear_output(wait=True)rewords.append(total_reward)
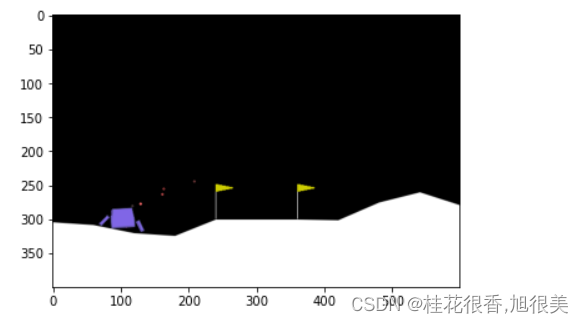
只有一把分数是正的,只有一次平安落地,小艇最终完全静止

搭建PPO agent
class Memory:def __init__(self):self.actions = []self.states = []self.logprobs = []self.rewards = []self.is_terminals = []def clear_memory(self):del self.actions[:]del self.states[:]del self.logprobs[:]del self.rewards[:]del self.is_terminals[:]class ActorCriticDiscrete(nn.Module):def __init__(self, state_dim, action_dim, n_latent_var):super(ActorCriticDiscrete, self).__init__()# actorself.action_layer = nn.Sequential(nn.Linear(state_dim, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, action_dim),nn.Softmax(dim=-1))# criticself.value_layer = nn.Sequential(nn.Linear(state_dim, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, 1))def act(self, state, memory):state = torch.from_numpy(state).float()action_probs = self.action_layer(state)dist = Categorical(action_probs)action = dist.sample()memory.states.append(state)memory.actions.append(action)memory.logprobs.append(dist.log_prob(action))return action.item()def evaluate(self, state, action):action_probs = self.action_layer(state)dist = Categorical(action_probs)action_logprobs = dist.log_prob(action)dist_entropy = dist.entropy()state_value = self.value_layer(state)return action_logprobs, torch.squeeze(state_value), dist_entropyclass PPOAgent:def __init__(self, state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip):self.lr = lrself.betas = betasself.gamma = gammaself.eps_clip = eps_clipself.K_epochs = K_epochsself.timestep = 0self.memory = Memory()self.policy = ActorCriticDiscrete(state_dim, action_dim, n_latent_var)self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr, betas=betas)self.policy_old = ActorCriticDiscrete(state_dim, action_dim, n_latent_var)self.policy_old.load_state_dict(self.policy.state_dict())self.MseLoss = nn.MSELoss()def update(self): # Monte Carlo estimate of state rewards:rewards = []discounted_reward = 0for reward, is_terminal in zip(reversed(self.memory.rewards), reversed(self.memory.is_terminals)):if is_terminal:discounted_reward = 0discounted_reward = reward + (self.gamma * discounted_reward)rewards.insert(0, discounted_reward)# Normalizing the rewards:rewards = torch.tensor(rewards, dtype=torch.float32)rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)# convert list to tensorold_states = torch.stack(self.memory.states).detach()old_actions = torch.stack(self.memory.actions).detach()old_logprobs = torch.stack(self.memory.logprobs).detach()# Optimize policy for K epochs:for _ in range(self.K_epochs):# Evaluating old actions and values : 新策略 重用 旧样本进行训练 logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)# Finding the ratio (pi_theta / pi_theta__old): ratios = torch.exp(logprobs - old_logprobs.detach())# Finding Surrogate Loss:计算优势值advantages = rewards - state_values.detach()surr1 = ratios * advantages ### 重要性采样的思想,确保新的策略函数和旧策略函数的分布差异不大surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages ### 采样clip的方式过滤掉一些新旧策略相差较大的样本loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy# take gradient stepself.optimizer.zero_grad()loss.mean().backward()self.optimizer.step()# Copy new weights into old policy:self.policy_old.load_state_dict(self.policy.state_dict())def step(self, reward, done):self.timestep += 1 # Saving reward and is_terminal:self.memory.rewards.append(reward)self.memory.is_terminals.append(done)# update if its timeif self.timestep % update_timestep == 0:self.update()self.memory.clear_memory()self.timstamp = 0def act(self, state):return self.policy_old.act(state, self.memory)
训练PPO agent
state_dim = 8 ### 游戏的状态是个8维向量
action_dim = 4 ### 游戏的输出有4个取值
n_latent_var = 256 # 神经元个数
update_timestep = 1200 # 每多少补跟新策略
lr = 0.002 # learning rate
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO 论文中表明0.2效果不错
random_seed = 1 agent = PPOAgent(state_dim ,action_dim,n_latent_var,lr,betas,gamma,K_epochs,eps_clip)
# agent.network.train() # Switch network into training mode
EPISODE_PER_BATCH = 5 # update the agent every 5 episode
NUM_BATCH = 200 # totally update the agent for 400 timeavg_total_rewards, avg_final_rewards = [], []# prg_bar = tqdm(range(NUM_BATCH))
for i in range(NUM_BATCH):log_probs, rewards = [], []total_rewards, final_rewards = [], []values = []masks = []entropy = 0# collect trajectoryfor episode in range(EPISODE_PER_BATCH):### 重开一把游戏state = env.reset()[0]total_reward, total_step = 0, 0seq_rewards = []for i in range(1000): ###游戏未结束action = agent.act(state) ### 按照策略网络输出的概率随机采样一个动作next_state, reward, done, _, _ = env.step(action) ### 与环境state进行交互,输出reward 和 环境next_statestate = next_statetotal_reward += rewardtotal_step += 1 rewards.append(reward) ### 记录每一个动作的rewardagent.step(reward, done) if done: ###游戏结束final_rewards.append(reward)total_rewards.append(total_reward)breakprint(f"rewards looks like ", np.shape(rewards)) if len(final_rewards)> 0 and len(total_rewards) > 0:avg_total_reward = sum(total_rewards) / len(total_rewards)avg_final_reward = sum(final_rewards) / len(final_rewards)avg_total_rewards.append(avg_total_reward)avg_final_rewards.append(avg_final_reward)
PPO agent在玩5把游戏
fix(env, seed)
agent.policy.eval() # set the network into evaluation mode
test_total_reward = []
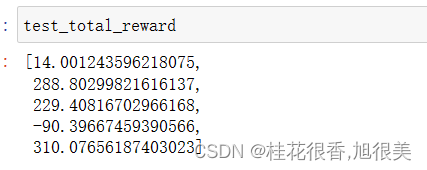
for i in range(5):actions = []state = env.reset()[0]img = plt.imshow(env.render())total_reward = 0done = Falsewhile not done :action= agent.act(state)actions.append(action)state, reward, done, _, _ = env.step(action)total_reward += rewardimg.set_data(env.render())display.display(plt.gcf())display.clear_output(wait=True)test_total_reward.append(total_reward)
从下图可以看到,玩得比随机的时候要好很多,有三把都平安着地,小艇最终完全静止。

其中有3把得分超过200,证明ppo在300轮已经学到了如何玩这个游戏,比之前的随机agent要强了不少。
github 源码
参考
ChatGPT的强化学习部分介绍
基于人类反馈的强化学习(RLHF) 理论
Anaconda安装GYM &关于Box2D安装的相关问题
conda-forge / packages / box2d-py
jupyter Notebook 内核似乎挂掉了,它很快将自动重启