vue.js网站如果做自适应百度搜索推广流程
文章目录
- 一、完整代码
- 二、过程实现
- 2.1 导包
- 2.2 数据准备
- 2.3 字符分词
- 2.4 构建数据集
- 2.5 定义模型
- 2.6 模型训练
- 2.7 模型推理
- 三、整体总结
采用RNN和unicode分词进行文本生成

一、完整代码
这里我们使用tensorflow实现,代码如下:
# 完整代码在这里
import tensorflow as tf
import keras_nlp
import numpy as nptokenizer = keras_nlp.tokenizers.UnicodeCodepointTokenizer(vocabulary_size=400)# tokens - ids
ids = tokenizer(['Why are you so funny?', 'how can i get you'])# ids - tokens
tokenizer.detokenize(ids)def split_input_target(sequence):input_text = sequence[:-1]target_text = sequence[1:]return input_text, target_text# 准备数据
text = open('./shakespeare.txt', 'rb').read().decode(encoding='utf-8')
dataset = tf.data.Dataset.from_tensor_slices(tokenizer(text))
dataset = dataset.batch(64, drop_remainder=True)
dataset = dataset.map(split_input_target).batch(64)input, ouput = dataset.take(1).get_single_element()# 定义模型d_model = 512
rnn_units = 1025class CustomModel(tf.keras.Model):def __init__(self, vocabulary_size, d_model, rnn_units):super().__init__(self)self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model)self.gru = tf.keras.layers.GRU(rnn_units, return_sequences=True, return_state=True)self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, inputs, states=None, return_state=False, training=False):x = inputsx = self.embedding(x)if states is None:states = self.gru.get_initial_state(x)x, states = self.gru(x, initial_state=states, training=training)x = self.dense(x, training=training)if return_state:return x, stateselse:return xmodel = CustomModel(tokenizer.vocabulary_size(), d_model, rnn_units)# 查看模型结构
model(input)
model.summary()# 模型配置
model.compile(loss = tf.losses.SparseCategoricalCrossentropy(),optimizer='adam',metrics=['accuracy']
)# 模型训练
model.fit(dataset, epochs=3)# 模型推理
class InferenceModel(tf.keras.Model):def __init__(self, model, tokenizer):super().__init__(self)self.model = modelself.tokenizer = tokenizerdef generate(self, inputs, length, return_states=False):inputs = inputs = tf.constant(inputs)[tf.newaxis]states = Noneinput_ids = self.tokenizer(inputs).to_tensor()outputs = []for i in range(length):predicted_logits, states = model(inputs=input_ids, states=states, return_state=True)input_ids = tf.argmax(predicted_logits, axis=-1)outputs.append(input_ids[0][-1].numpy())outputs = self.tokenizer.detokenize(lst).numpy().decode('utf-8')if return_states:return outputs, stateselse:return outputsinfere = InferenceModel(model, tokenizer)# 开始推理
start_chars = 'hello'
outputs = infere.generate(start_chars, 1000)
print(start_chars + outputs)
二、过程实现
2.1 导包
先导包tensorflow, keras_nlp, numpy
import tensorflow as tf
import keras_nlp
import numpy as np
2.2 数据准备
数据来自莎士比亚的作品 storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt;我们将其下载下来存储为shakespeare.txt
2.3 字符分词
这里我们使用unicode分词:将所有字符都作为一个词来进行分词
tokenizer = keras_nlp.tokenizers.UnicodeCodepointTokenizer(vocabulary_size=400)# tokens - ids
ids = tokenizer(['Why are you so funny?', 'how can i get you'])# ids - tokens
tokenizer.detokenize(ids)
2.4 构建数据集
利用tokenizer和text数据构建数据集
def split_input_target(sequence):input_text = sequence[:-1]target_text = sequence[1:]return input_text, target_texttext = open('./shakespeare.txt', 'rb').read().decode(encoding='utf-8')
dataset = tf.data.Dataset.from_tensor_slices(tokenizer(text))
dataset = dataset.batch(64, drop_remainder=True)
dataset = dataset.map(split_input_target).batch(64)input, ouput = dataset.take(1).get_single_element()
2.5 定义模型
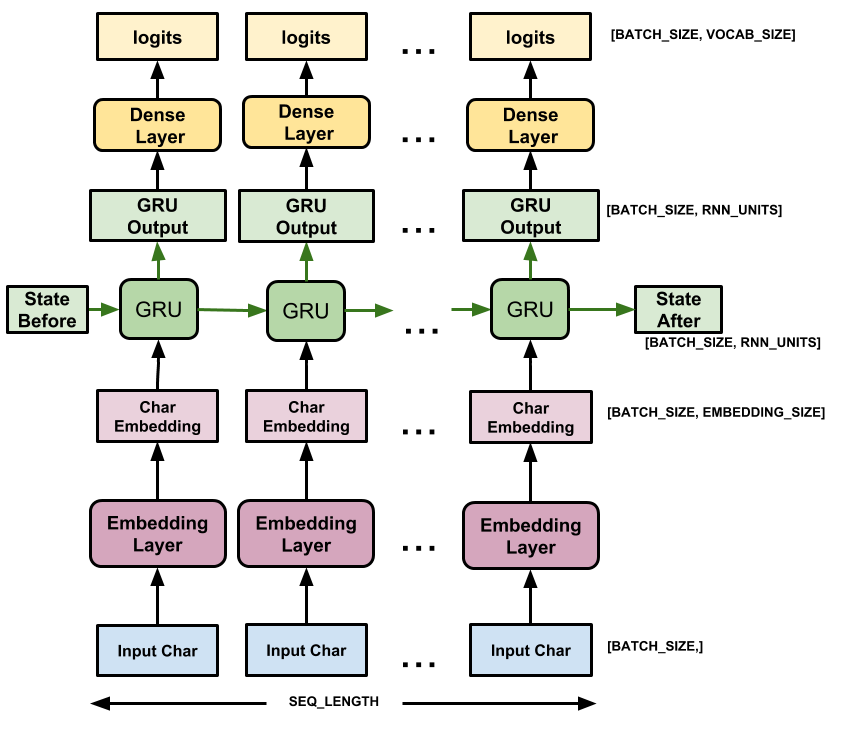
d_model = 512
rnn_units = 1025class CustomModel(tf.keras.Model):def __init__(self, vocabulary_size, d_model, rnn_units):super().__init__(self)self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model)self.gru = tf.keras.layers.GRU(rnn_units, return_sequences=True, return_state=True)self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, inputs, states=None, return_state=False, training=False):x = inputsx = self.embedding(x)if states is None:states = self.gru.get_initial_state(x)x, states = self.gru(x, initial_state=states, training=training)x = self.dense(x, training=training)if return_state:return x, stateselse:return xmodel = CustomModel(tokenizer.vocabulary_size(), d_model, rnn_units)# 查看模型结构
model(input)
model.summary()
2.6 模型训练
model.compile(loss = tf.losses.SparseCategoricalCrossentropy(),optimizer='adam',metrics=['accuracy']
)model.fit(dataset, epochs=3)
2.7 模型推理
定义一个InferenceModel进行模型推理配置;
class InferenceModel(tf.keras.Model):def __init__(self, model, tokenizer):super().__init__(self)self.model = modelself.tokenizer = tokenizerdef generate(self, inputs, length, return_states=False):inputs = inputs = tf.constant(inputs)[tf.newaxis]states = Noneinput_ids = self.tokenizer(inputs).to_tensor()outputs = []for i in range(length):predicted_logits, states = model(inputs=input_ids, states=states, return_state=True)input_ids = tf.argmax(predicted_logits, axis=-1)outputs.append(input_ids[0][-1].numpy())outputs = self.tokenizer.detokenize(lst).numpy().decode('utf-8')if return_states:return outputs, stateselse:return outputsinfere = InferenceModel(model, tokenizer)start_chars = 'hello'
outputs = infere.generate(start_chars, 1000)
print(start_chars + outputs)
生成结果如下所示,感觉很差:
hellonofur us:
medous, teserwomador.
walled o y.
as
t aderemowate tinievearetyedust. manonels,
w?
workeneastily.
watrenerdores aner'shra
palathermalod, te a y, s adousced an
ptit: mamerethus:
bas as t: uaruriryedinesm's lesoureris lares palit al ancoup, maly thitts?
b veatrt
watyeleditenchitr sts, on fotearen, medan ur
tiblainou-lele priniseryo, ofonet manad plenerulyo
thilyr't th
palezedorine.
ti dous slas, sed, ang atad t,
wanti shew.
e
upede wadraredorenksenche:
wedemen stamesly ateara tiafin t t pes:
t: tus mo at
io my.
ane hbrelely berenerusedus' m tr;
p outellilid ng
ait tevadwantstry.
arafincara, es fody
'es pra aluserelyonine
pales corseryea aburures
angab:
sunelyothe: s al, chtaburoly o oonis s tioute tt,
pro.
tedeslenali: s 't ing h
sh, age de, anet: hathes: s es'tht,
as:
wedly at s serinechamai:
mored t.
t monatht t athoumonches le.
chededondirineared
ter
p y
letinalys
ani
aconen,
t rs:
t;et, tes-
luste aly,
thonort aly one telus, s mpsantenam ranthinarrame! a
pul; bon
s fofuly
三、整体总结
RNN结合unicode分词能进行文本生成但是效果一言难尽!