台州网站制作台州网站建设珠海百度推广优化排名

文章目录
- 导入模块
- 相关语法
- 实战
导入模块
from lxml import etree相关语法
XPath(XML Path Language)是一种用于在XML文档中定位和选择元素的语言。XPath的主要应用领域是在XML文档中进行导航和查询,通常用于在XML中选择节点或节点集合。以下是XPath的基本语法和一些常见的表达式:
-
节点选择:
/: 从根节点开始选择//: 选择节点,不考虑它们的位置.: 当前节点..: 父节点
-
节点过滤:
[@attribute='value']: 选择具有特定属性值的节点[position()]: 选择特定位置的节点[last()]: 选择最后一个节点[text()='some text']: 选择具有特定文本内容的节点
-
通配符:
*: 匹配任何元素节点@*: 匹配任何属性节点
-
轴:
ancestor::: 选择所有祖先节点descendant::: 选择所有子孙节点parent::: 选择父节点child::: 选择子节点following-sibling::: 选择后续同级节点preceding-sibling::: 选择前置同级节点
-
运算符:
and: 逻辑与or: 逻辑或not: 逻辑非
-
函数:
text(): 选择当前节点的文本内容name(): 选择当前节点的名称count(): 计算节点集合的节点数concat(): 连接字符串
以下是一些XPath表达式的示例:
/bookstore/book: 选择所有直接子节点为book的节点//book: 选择文档中所有的book节点/bookstore/book[@category='fiction']: 选择具有特定属性值的book节点//title[text()='Introduction to XPath']: 选择具有特定文本内容的title节点/bookstore/book[position()<3]: 选择前两个book节点//author[contains(text(),'Rowling')]: 选择包含特定文本的author节点
XPath语法灵活且强大,可以根据需要进行深入的定位和选择。
实战
- 解析的话,我们是对网站的发送的请求所传回的对象的text 进行解析
- 对于xpath 进行寻找得到,加上
text()就可以输出文本- 对于xpath 查找的得到的,加上
@属性名就可以返回相关的属性值- 为了使用方便,常常用
//来选择结点,用[@ class = " "]来具体根据属性筛选,对于同一个路径下,多个平行的内容,可以在[@ class = " "]之后加上[ number]来具体选择,注意,这个number 为具体第几个,从1开始- 注意
xpath返回的对象为列表
以网站https://ssr1.scrape.center/为例子
我们先爬取该网站的电影名字
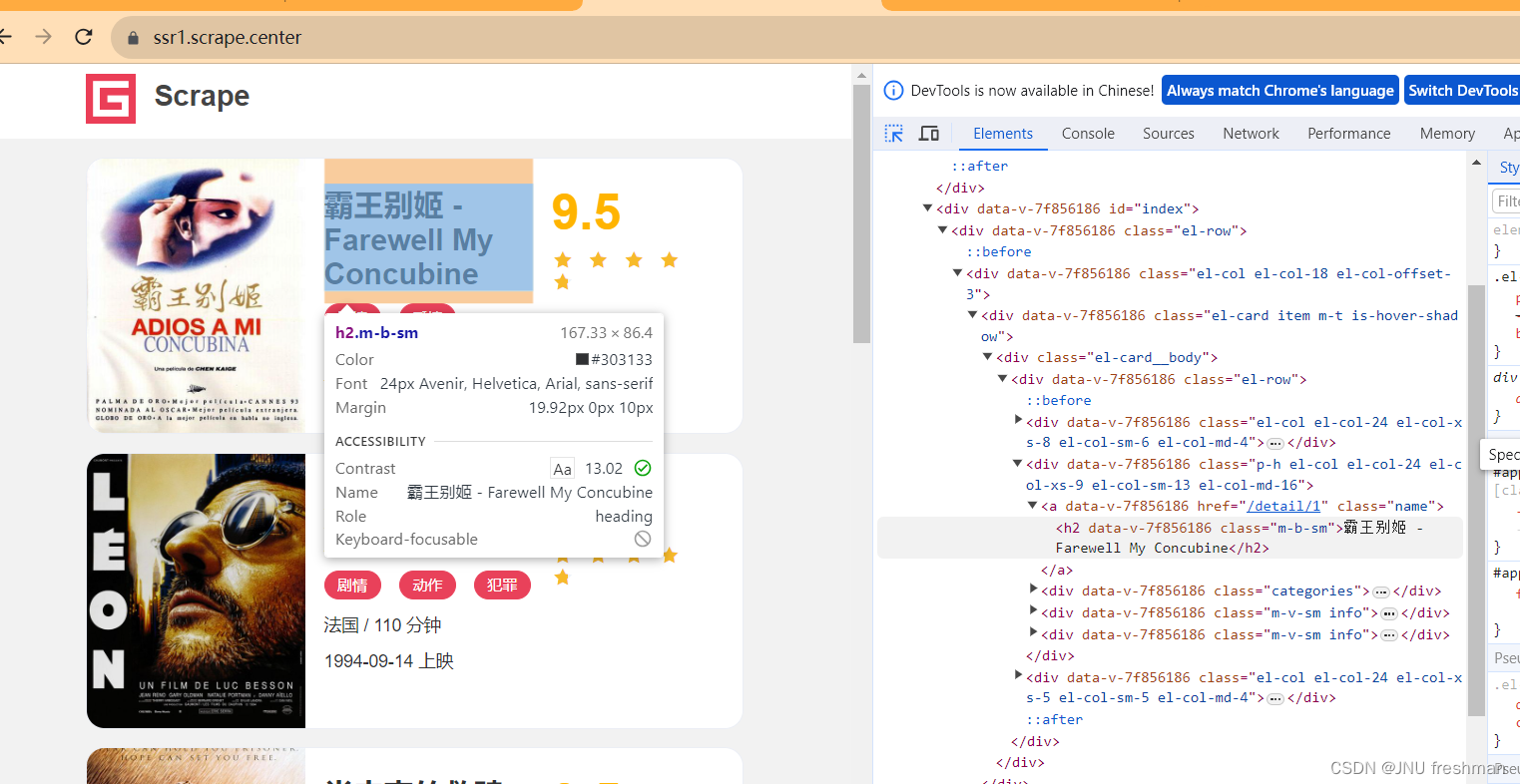
通过看网页的源码,发现在
标签下,class = “m-b-sm”

import requests
from lxml import etreeheaders ={"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}responce = requests.get(r'https://ssr1.scrape.center/',headers = headers)html = etree.HTML(responce.text)allname = html.xpath(r'//h2[@class="m-b-sm"]/text()')
for name in allname:print(name)这样就可以爬取电影名