商城购物网站建设方案平台推广公司
Flink理论—容错之状态
在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
Flink 使用流重放和 检查点的组合来实现容错。检查点标记每个输入流中的特定点以及每个运算符的相应状态。通过恢复运算符的状态并从检查点点重放记录,可以从检查点恢复流数据流,
为了使该机制实现其完全保证,数据流源(例如消息队列或代理)需要能够将流倒回到定义的最近点。Apache Kafka具有这种能力,Flink 的 Kafka 连接器利用了这一点。
如果发生程序故障(由于机器、网络或软件故障),Flink 会停止分布式流数据流。然后系统重新启动算子并将其重置为最新的成功检查点。输入流重置为状态快照点。作为重新启动的并行数据流的一部分进行处理的任何记录都保证不会影响之前的检查点状态。
状态
我们在 Flink 的官方博客中找到这样一段话,可以认为这是对状态的定义:
When working with state, it might also be useful to read about Flink’s state backends. Flink provides different state backends that specify how and where state is stored. State can be located on Java’s heap or off-heap. Depending on your state backend, Flink can also manage the state for the application, meaning Flink deals with the memory management (possibly spilling to disk if necessary) to allow applications to hold very large state. State backends can be configured without changing your application logic.
这段话告诉我们,所谓的状态指的是,在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。
有状态操作的一些示例:
- 当应用程序搜索某些事件模式时,状态将存储迄今为止遇到的事件序列。
- 当每分钟/小时/天聚合事件时,状态保存待处理的聚合。
- 当通过数据点流训练机器学习模型时,状态保存模型参数的当前版本。
- 当需要管理历史数据时,状态允许有效访问过去发生的事件。
Flink 状态分类
我们在之前的课时中提到过 KeyedStream 的概念,并且介绍过 KeyBy 这个算子的使用。在 Flink 中,根据数据集是否按照某一个 Key 进行分区,将状态分为 Keyed State 和 Operator State(Non-Keyed State)两种类型。
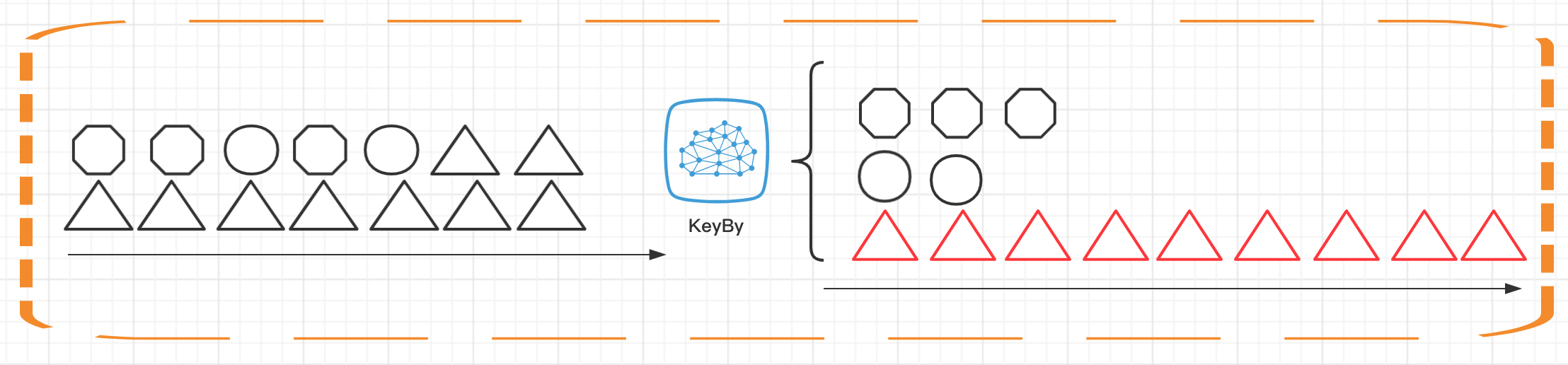
如上图所示,Keyed State 是经过分区后的流上状态,每个 Key 都有自己的状态,图中的八边形、圆形和三角形分别管理各自的状态,并且只有指定的 key 才能访问和更新自己对应的状态。
这里还需要说明这个 Key 是隐含的,也就是不需要我们手动去操作,我们只要定义一个描述符,然后去操作状态即可,也就是说 Key 本身也是托管的
上面那张图还是简化了很多,真实的状态是这样的,我们的一个算子实例还是托管了很多Key 的,其实为了方便理解你可将其理解为一个大的Map ,
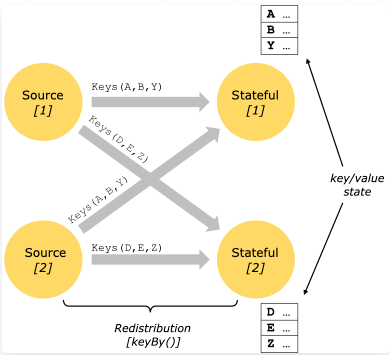
对 Keyed State 的访问只能在 Keyed Stream上进行,即在键控/分区数据交换之后,并且仅限于与当前事件的键关联的值。
Keyed State 进一步组织成所谓的键组。Key Groups 是 Flink 可以重新分配 Keyed State 的原子单元;键组的数量与定义的最大并行度完全相同。在执行期间,键控运算符的每个并行实例都使用一个或多个键组的键
与 Keyed State 不同的是,Operator State 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。每个算子子任务上的数据共享自己的状态。
Operator State 的实际应用场景不如 Keyed State 多,一般来说它会被用在 Source 或 Sink 等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证 Flink 应用的 Exactly-Once 语义。
但是有一点需要说明的是,无论是 Keyed State 还是 Operator State,Flink 的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
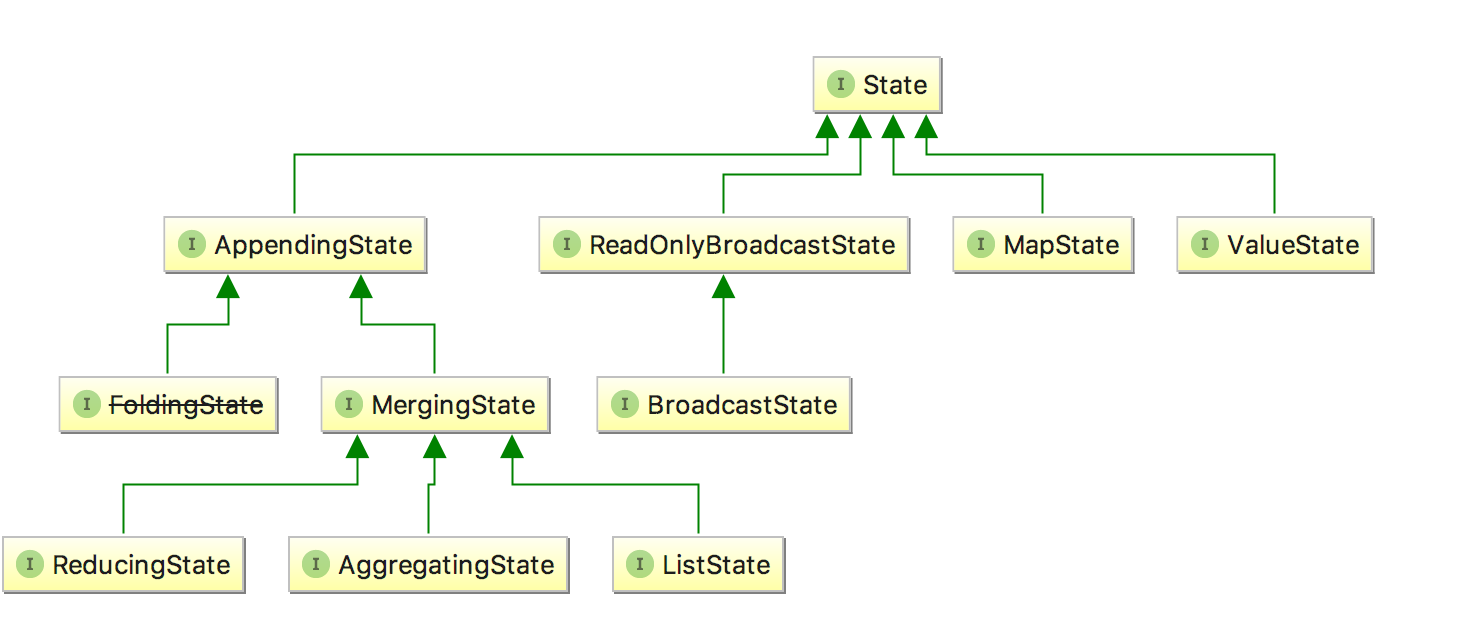
我们可以看一下 State 的类图,对于 Keyed State,Flink 提供了几种现成的数据结构供我们使用,State 主要有四种实现,分别为 ValueState、MapState、AppendingState 和 ReadOnlyBrodcastState ,其中 AppendingState 又可以细分为ReducingState、AggregatingState 和 ListState。
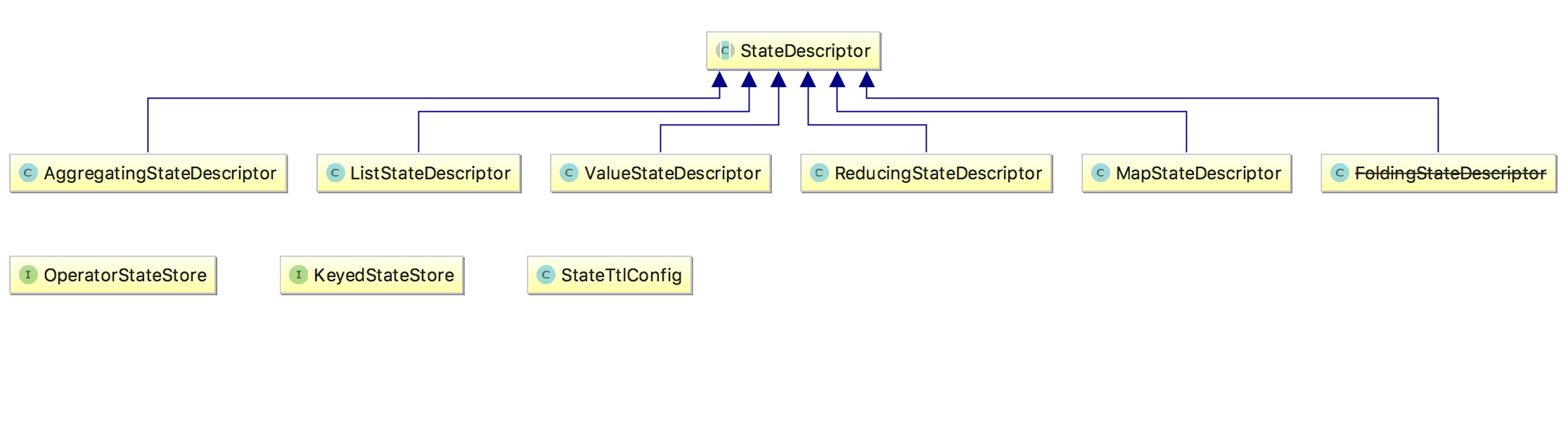
那么我们怎么访问这些状态呢?Flink 提供了 StateDesciptor 方法专门用来访问不同的 state,类图如下:
状态的使用
状态的基本使用
下面演示一下如何使用 StateDesciptor 和 ValueState,代码如下:
public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 5L), Tuple2.of(1L, 2L)).keyBy(0).flatMap(new CountWindowAverage()).printToErr();env.execute("submit job");}public static class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {private transient ValueState<Tuple2<Long, Long>> sum;public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {Tuple2<Long, Long> currentSum;// 访问ValueStateif(sum.value()==null){currentSum = Tuple2.of(0L, 0L);}else {currentSum = sum.value();}// 更新currentSum.f0 += 1;// 第二个元素加1currentSum.f1 += input.f1;// 更新statesum.update(currentSum);// 如果count的值大于等于2,求知道并清空stateif (currentSum.f0 >= 2) {out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));sum.clear();}}public void open(Configuration config) {ValueStateDescriptor<Tuple2<Long, Long>> descriptor =new ValueStateDescriptor<>("average", // state的名字TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {})); // 设置默认值StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();descriptor.enableTimeToLive(ttlConfig);sum = getRuntimeContext().getState(descriptor);}
}
在上述例子中,我们通过继承 RichFlatMapFunction 来访问 State,通过 getRuntimeContext().getState(descriptor) 来获取状态的句柄。而真正的访问和更新状态则在 Map 函数中实现。
我们这里的输出条件为,每当第一个元素的和达到二,就把第二个元素的和与第一个元素的和相除,最后输出。我们直接运行,在控制台可以看到结果:
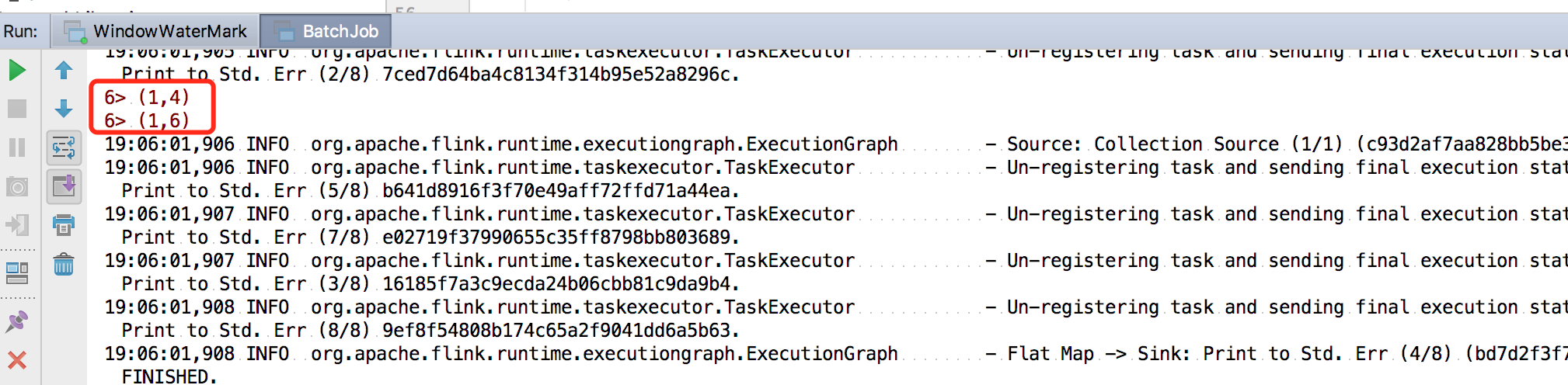
状态管理配置
同样,我们对于任何状态数据还可以设置它们的过期时间。如果一个状态设置了 TTL,并且已经过期,那么我们之前保存的值就会被清理。
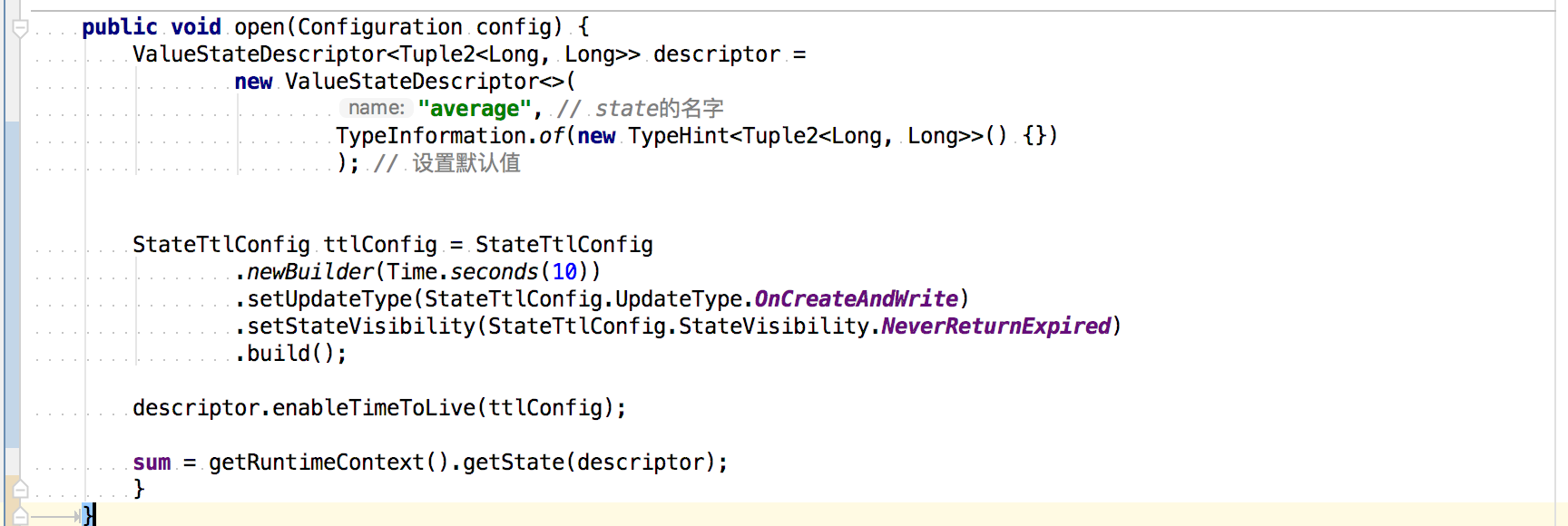
想要使用 TTL,我们需要首先构建一个 StateTtlConfig 配置对象;然后,可以通过传递配置在任何状态描述符中启用 TTL 功能。
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();
descriptor.enableTimeToLive(ttlConfig);
StateTtlConfig 这个类中有一些配置需要我们注意:
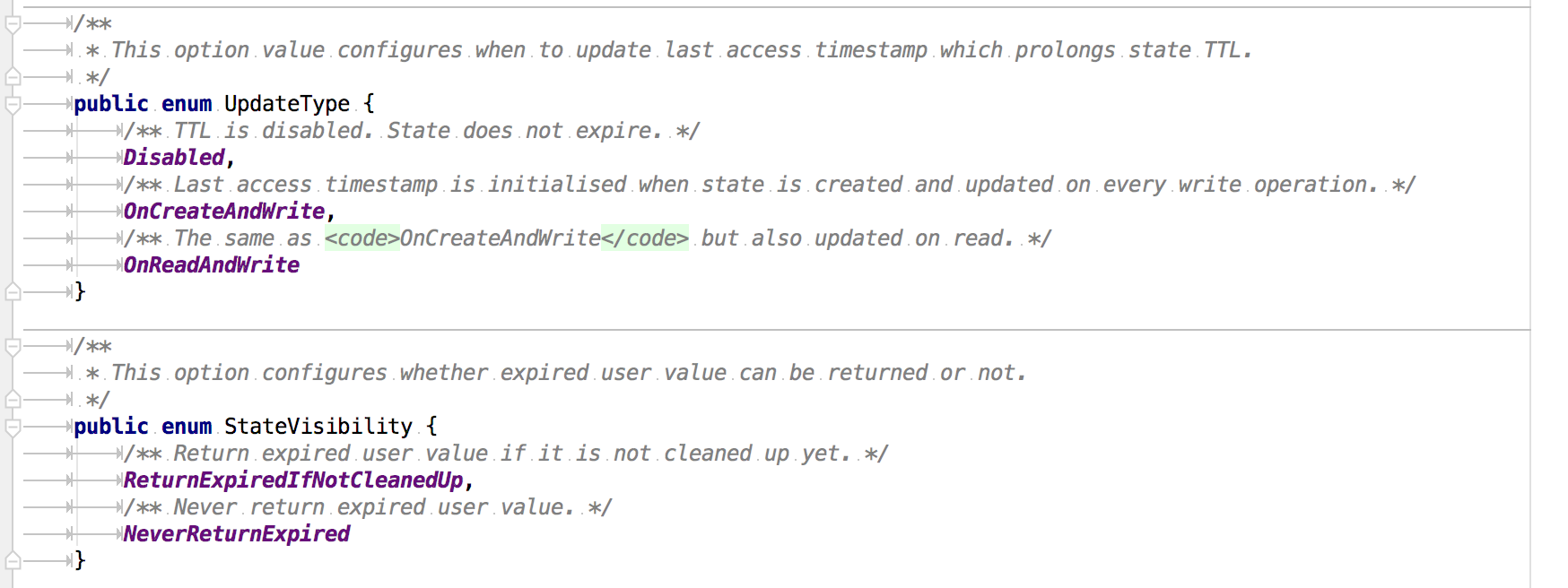
UpdateType 表明了过期时间什么时候更新,而对于那些过期的状态,是否还能被访问则取决于 StateVisibility 的配置。
总结
主要Flink 中的状态分类和使用,并且用实际案例演示了用法;关于状态后端我们可以参考下一节