心理测评做测试的网站最新新闻摘抄
记录一次排查UnexpectedAdmissionError问题的过程
1. 问题
环境
3master节点+N个GPU节点
kubelet版本:v1.19.4
kubernetes版本:v1.19.4
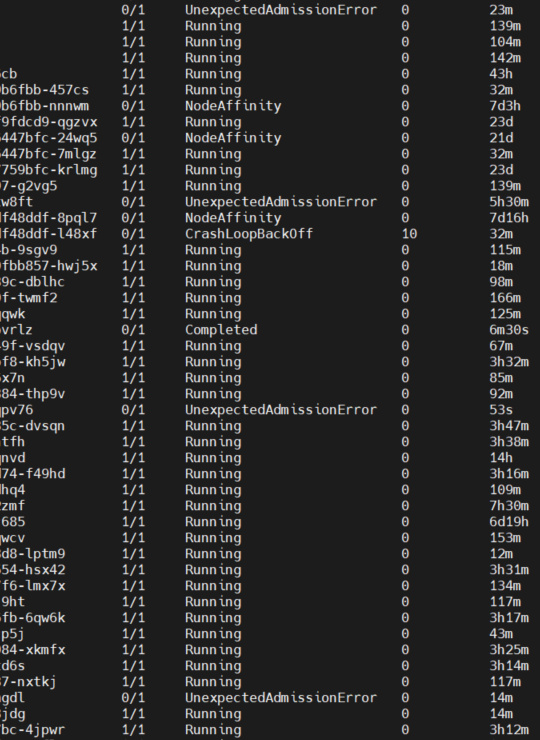
生产环境K8S集群,莫名其妙的出现大量UnexpectedAdmissionError状态的Pod,导致部分任务执行异常,出现这种情况时,节点的资源是足以支持运行一个GPU Pod的。
报的错误:
Allocate failed due to requested number of devices unavailable for nvidia.com/gpu. Requested: 1, Available: 0, which is unexpected
因为Pod的调度都是指定了spec.nodeName属性的,所以跳过了Pending状态强制进行调度,在资源不足的情况下,就出现了UnexpectedAdmissionError异常。
2.排查过程
确定节点资源是否正常
kubectl describe node <node-name>
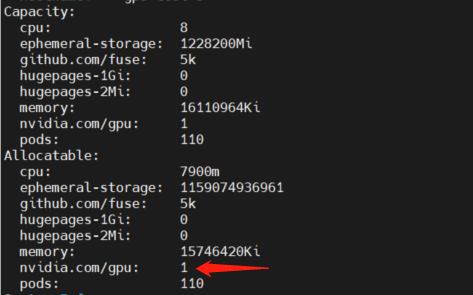
通过describe命令可以看到节点的GPU卡是正常的,然后可以去节点上通过nvidia-dcgm,确定GPU设备是否健康
nvidia-dcgm:nvidia官网
在确定节点和GPU设备都是没问题的情况下,那么开始排查出现问题的原因
通过查看日志和源码,可以定位到日志是在manager.go#devicesToAllocate方法的698行出现
// resource=nvidia.com/gpu// Gets Devices in use.devicesInUse := m.allocatedDevices[resource]// Gets Available devices.available := m.healthyDevices[resource].Difference(devicesInUse)if available.Len() < needed {return nil, fmt.Errorf("requested number of devices unavailable for %s. Requested: %d, Available: %d", resource, needed, available.Len())}
也就是,从健康的GPU集合中去除了已使用的GPU后,可用GPU数量少于所需要的数量,但是通过上面的排查,在创建的Pod.cm.resource.limit:nvidia.com/gpu=1的情况下,理论上应该是成功的,这里出现了报错,那么肯定是GPU卡被占用了。
查看kubelet日志,定位具体问题,日志位于/var/log/messages文件,由于kubelet默认日志级别为--v=2,这里需要将其更改为--v=4
查看是否有/etc/kubernetes/kubelet.env文件,如果有,直接更改KUBE_LOG_LEVEL配置
KUBE_LOGTOSTDERR="--logtostderr=true"
KUBE_LOG_LEVEL="--v=4"
如果没有,则修改/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf文件
添加Environment
Environment="KUBE_LOGTOSTDERR=--logtostderr=true"
Environment="KUBE_LOG_LEVEL=--v=4"
修改ExecStart命令,在参数位追加$KUBE_LOGTOSTDERR $KUBE_LOG_LEVEL
ExecStart=/usr/bin/kubelet $KUBE_LOGTOSTDERR $KUBE_LOG_LEVEL $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
修改后需要重启kubelet
systemctl daemon-reload && systemctl restart kubelet
通过grep命令查看关键日志
grep "package-instance-42895-test-4461" messages
从日志中发现,kubelet监听到了两次创建同一个Pod的事件,也就是为一个Job创建了两个Pod
但是Job的配置都是为1
spec:completions: 1backoffLimit: 0parallelism: 1
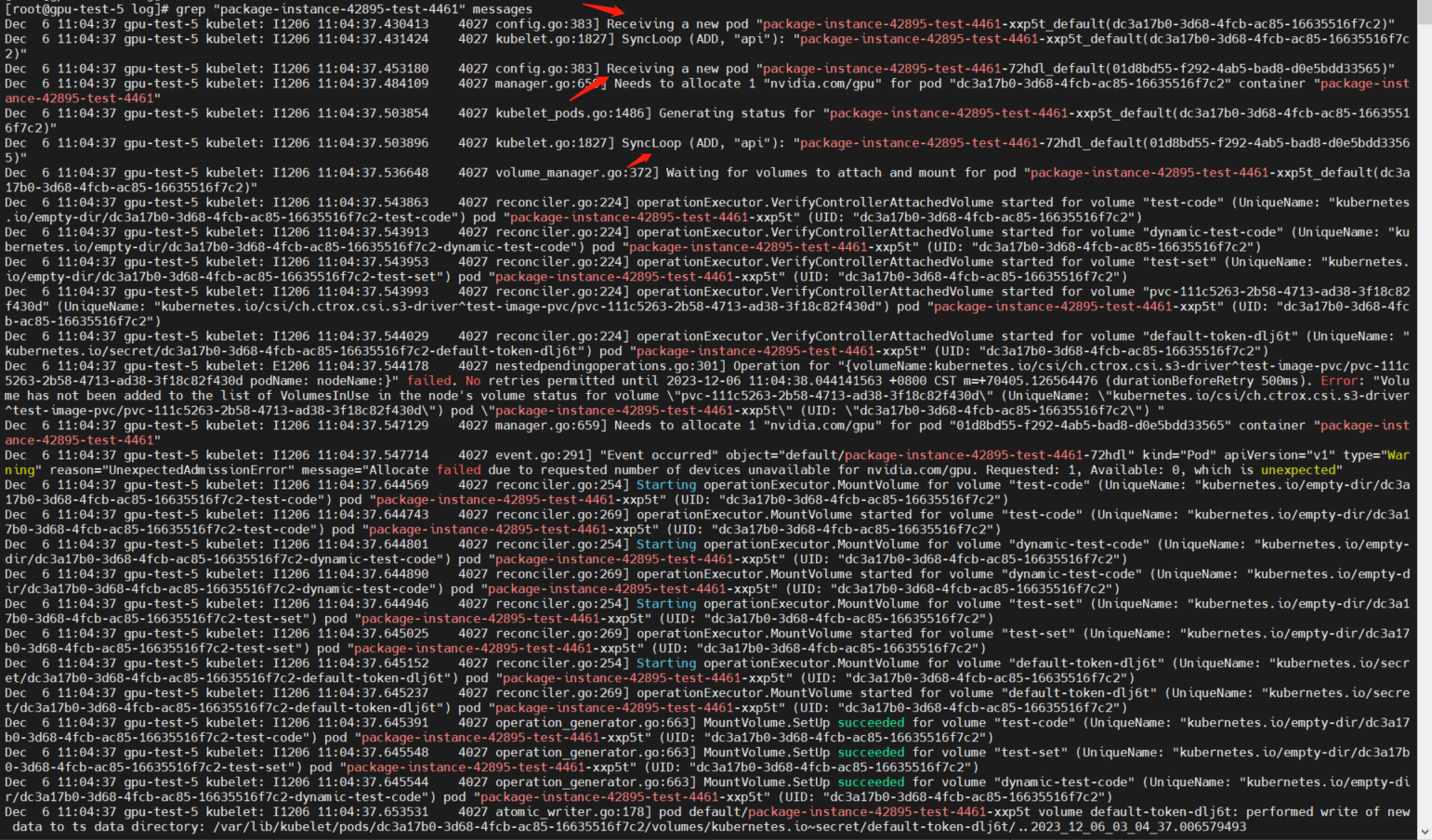
在这样的配置下,应该只有一次创建Pod的事件才对。
再分别查看两次Pod的资源分配日志
通过less messages命令查看详细的日志过程

从日志中可以看出,第一个Pod分配GPU资源是成功的
而在第二个Pod分配GPU资源时,就提示分配失败

至此问题就定位到了,是因为kubelet本应只创建一个Pod,但是确监听到了多次创建Pod的事件。
从这个情况来看,应当所有的任务都失败才对,但只有小部分任务失败了,继续查看日志

在下面的日志可以看到,kubelet随后就监听到了DELETE事件,删除了一个Pod,虽然在这个日志中删除的是创建失败的Pod
但是多观察几个Pod就会发现,删除完全的随机的,并不是根据状态来的,所以就会出现部分任务失败,但是大部分任务都成功的情况。
从上面的排查过程来看,kubelete、node、gpu device都是没有问题的,那么,继续往上排查scheduler
同样的,scheduler的日志级别默认也是--v=2,这里也需要改成--v=4,修改kube-scheduler.yaml文件
vim /etc/kubernetes/manifests/kube-scheduler.yaml
在command中追加一行--v=4
spec:containers:- command:- kube-scheduler- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf- --bind-address=0.0.0.0- --kubeconfig=/etc/kubernetes/scheduler.conf- --leader-elect=false- --leader-elect-lease-duration=15s- --leader-elect-renew-deadline=10s- --port=0- --v=4
更改文件后保存,等待scheduler自动重建。注意重建后日志会清空,所以需要等待下次调度再次重新进行问题排查
然后通过kubectl logs命令,查看三个scheduler的调度日志
kubectl logs -n kube-system kube-scheduler-master-1| grep package-instance-42895-test-4461
kubectl logs -n kube-system kube-scheduler-master-2| grep package-instance-42895-test-4461
kubectl logs -n kube-system kube-scheduler-master-3| grep package-instance-42895-test-4461
[root@master-1 ~]# kubectl logs -n kube-system kube-scheduler-master-1| grep package-instance-42895-test-4461
I1206 03:23:08.641125 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-xxp5t
I1206 03:23:08.641463 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-72hdl
I1206 03:23:08.866294 1 eventhandlers.go:283] delete event for scheduled pod default/package-instance-42895-test-4461-72hdl[root@master-1 ~]# kubectl logs -n kube-system kube-scheduler-master-2| grep package-instance-42895-test-4461
I1206 03:23:08.641125 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-xxp5t
I1206 03:23:08.641463 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-72hdl
I1206 03:23:08.866294 1 eventhandlers.go:283] delete event for scheduled pod default/package-instance-42895-test-4461-72hdl[root@master-1 ~]# kubectl logs -n kube-system kube-scheduler-master-3| grep package-instance-42895-test-4461
从上面的日志可以看到,Pod确实被调度了两次,但是,schduler只是负责调度Pod,并不会控制Pod创建的数量。
而且,理论上,应该只有一个leader级别的schduler处于工作状态,其他两个schduler,应当是处于睡眠状态,不进行工作才对,也就说,其他的schduler不应该监听到调度事件。
虽然问题不在此,但是从这里可以发现schduler的部署是有问题的,查看schduler配置
spec:containers:- command:- kube-scheduler- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf- --bind-address=0.0.0.0- --kubeconfig=/etc/kubernetes/scheduler.conf- --leader-elect=false- --leader-elect-lease-duration=15s- --leader-elect-renew-deadline=10s- --port=0- --v=4
在检查了三个节点的schduler配置后,发现有一个节点的schduler配置中,--leader-elect被设置成了fasle
Kubernetes的调度器可以使用leader选举来确保只有一个实例处于活跃状态,负责决策和分配Pod。一旦调度器的活跃实例失效,其他备用实例可以进行leader选举,确保集群的Pod能够被适当地调度到可用的节点上。
同样,如果多个调度器实例都设置为--leader-elect=false,它们将尝试同时管理Pod的调度决策,可能会导致混乱、资源冲突以及不一致的状态。
在这可以确定是--leader-elect=false导致的出现了多个leader级的schduler,将此配置更改为--leader-elect=true。
等待schudler重建,修复了schudler多leader的问题,但是,Pod重复调度的问题依旧没有解决,查看Pod调度调度流程
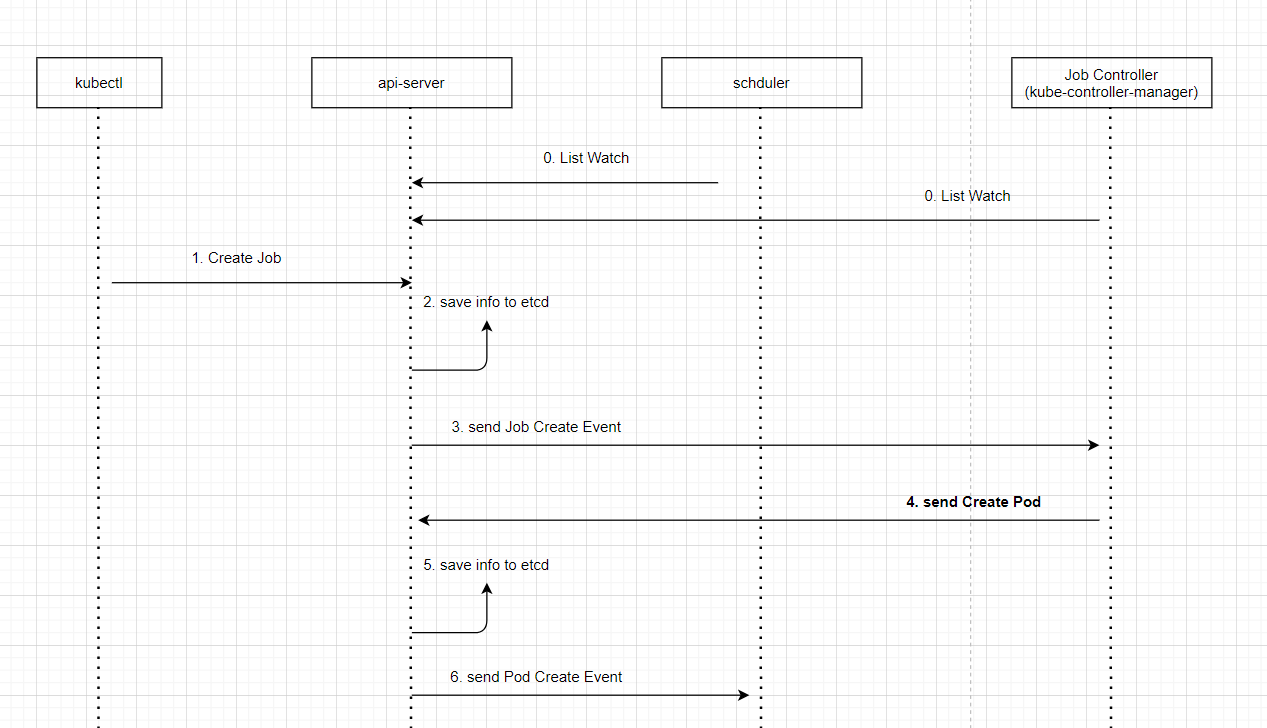
从流程图上可以看出,创建Pod的请求,是由Job Controller发出的,在kubernetes中有很多的控制器,例如
Job Controller、Deployment Controller,这些控制器由控制平面进行管理kube-controller-manger。
结合上面schduler的可以得出结论。是在Job Controller中,发出了两次创建Pod的请求,而kube-controller-manger集群跟schduler集群一样,理论上应该只有一个leader级别的处于工作中的状态,其他两个都应该处于休眠状态。但是这里发起了两次创建请求,显然是有一个以上的leader级的kube-controller-manger,通过查看配置文件,问题跟schduler是一样的
YAML文件路径/etc/kubernetes/manifests/kube-controller-manager.yaml
有一个节点的YAML文件中--leader-elect=false,这个配置也被设置为了false,导致的出现了多个ledaer级的控制平面,从而导致Pod被多次创建。
验证方式也是同样的,通过kubectl logs命令,查看三个kube-controller-manager的监听日志,发现有两个控制平面监听到了Create Job事件,从而导致的这次问题。
kubectl logs -n kube-system kube-controller-manager-master-1 |grep package-instance-42895-test-4461
3. 解决方案
通过修改/etc/kubernetes/manifests/kube-scheduler.yaml和/etc/kubernetes/manifests/kube-controller-manager.yaml两个YAML文件中的--leader-elect配置,将其修改为true,即可解决问题。
--leader-elect=false