学校网站的功能seo赚钱培训课程
最近要批量解压归档文件和压缩包,所以就想能不能并行执行这些工作。因为tar自身不支持并行解压,但是像make却可以支持生成一些文件,所以我才有了这种想法。
方法有两种,第一种不用安装任何软件或工具,直接bash或其他 Shell 中就可以使用;第二种需要安装 GNU parallel 这个工具来进行。二者在使用上都很简单,但是后者更人性化(应该可以用这个词来形容)一些。最后还介绍了一种比较奇特的方法,是无意中看到的,虽然没啥用但是有点意思。
直接在命令最后使用&
这个方法需要在命令最后使用&,也就是将这个命令放入后台执行。如下是并行解压提取当前文件夹下所有的归档文件的方法:
for tarfile in *.tar; do tar xvf $tarfile &
done;
可以看到这个方法可以说是非常简单了,但是最大的问题就是它会给每个归档文件创建一个进程,并不会自动根据设备的线程数而创建合适数量的进程(tar由于需要大量 I/O,所以也无法维持高 CPU 使用率),如下:
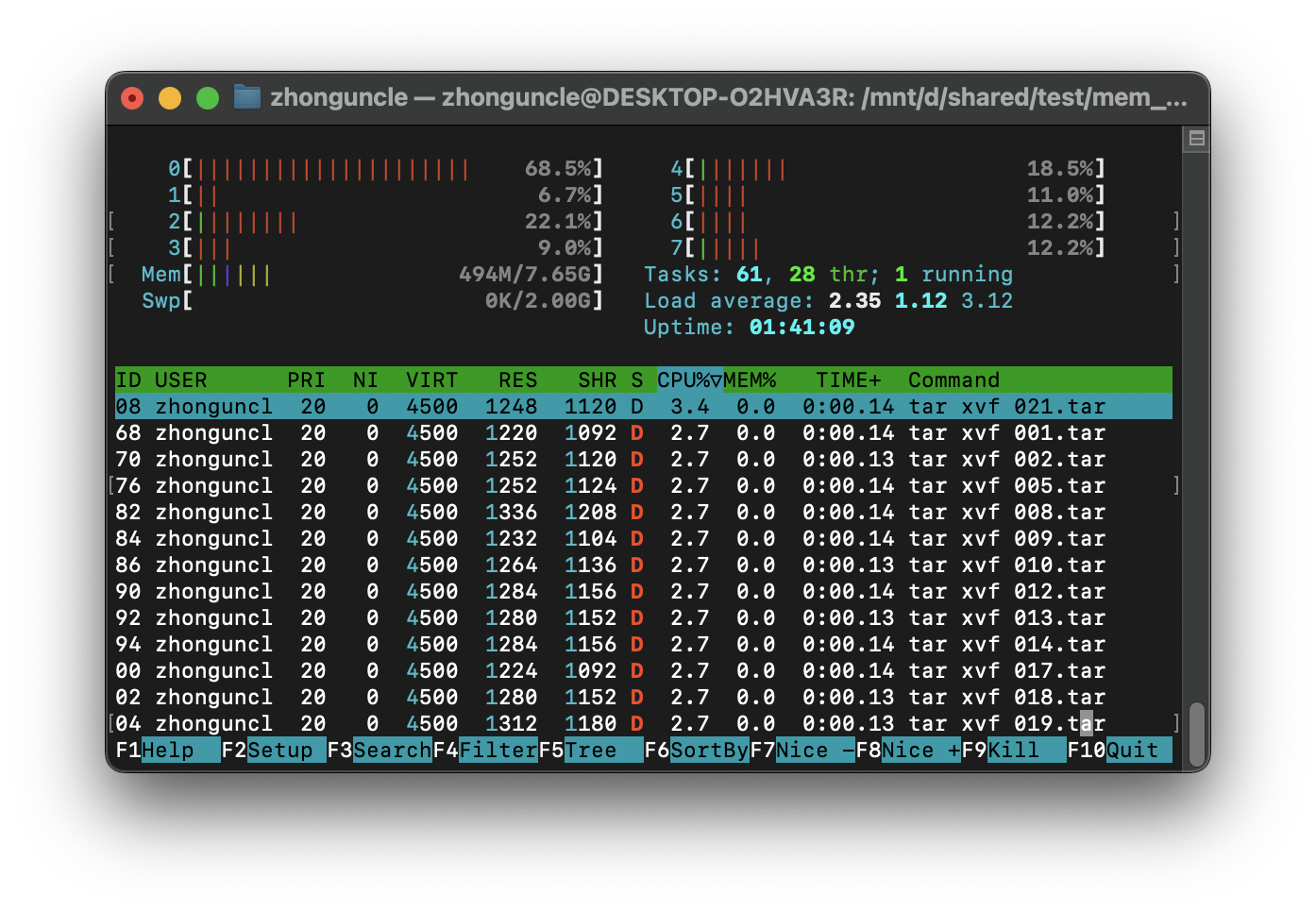
如果是小数量的解压提取可能没什么问题,但是如果特别大数量的归档文件解压提取,那么可能会造成调度损耗过大。如果需要根据实际线程数量生成,那么就复杂多了。
使用GNU parallel
这个工具很好用,不光可以设置最大并行任务数量,还可以通过--bar选项显示当前总进度如何。使用方法如下(还是解压提取一堆归档文件):
parallel tar xvf ::: *.tar
这种方法但是像time,将需要并行化的命令放到parallel后面即可,而不同命令之间不同的地方(参数部分)使用:::标注出来。
而且相比上一种方法,默认情况下最多只会创建 CPU 的线程数的进程,而不是一次性全部生成。如下:
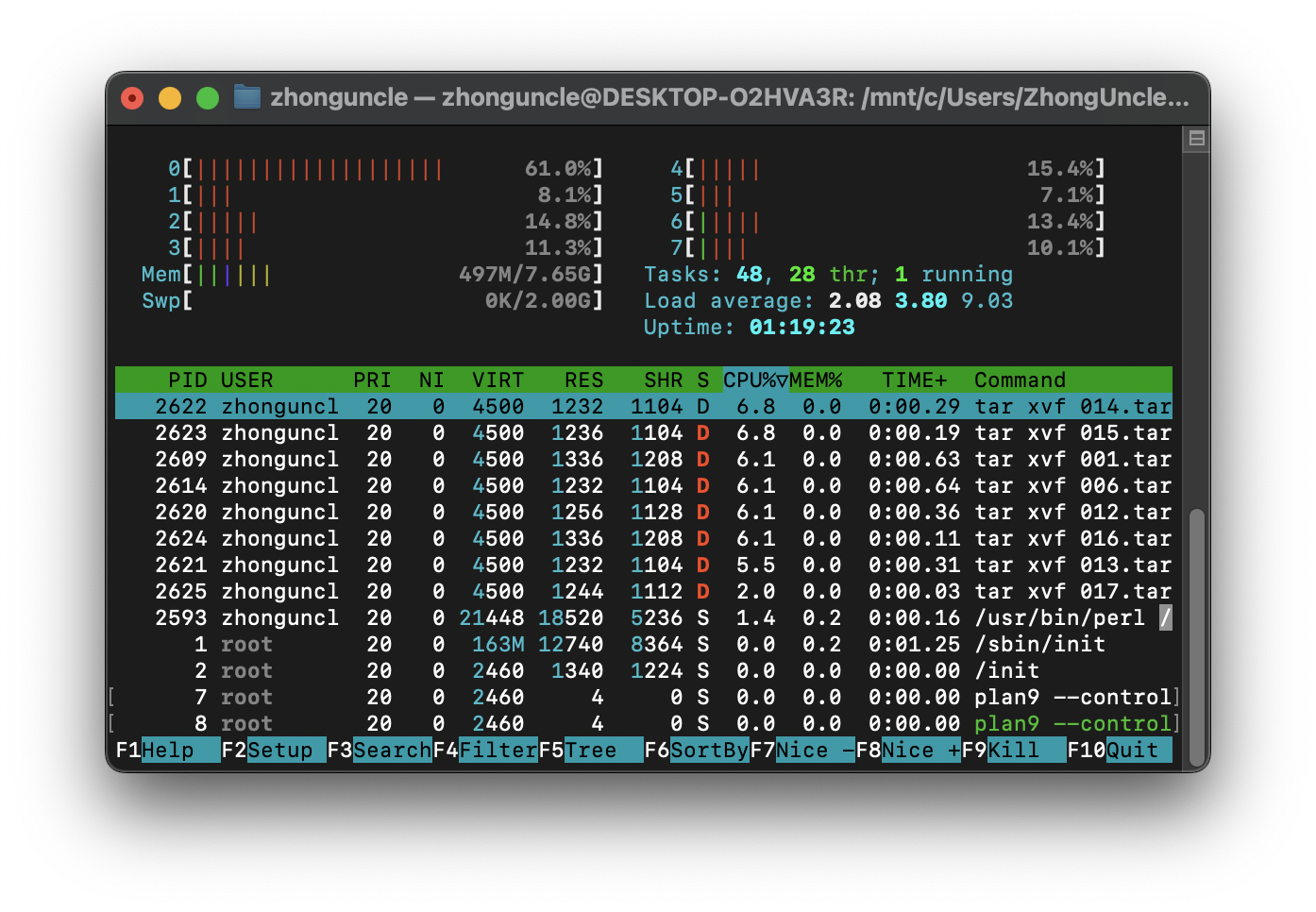
可以看到一开始只生成了线程数量的进程,也就是8个进程。如果想手动设定最大并行进程数量,那么使用-j 数量即可(和make的-j选项一样,有没有空格都行)。
管道传递参数
上面是直接可以获取参数的情况,并不存在不同程序之间通过管道(pipe)传递信息的情况。那么面对这种情况该怎么办呢?
使用{}在下一个程序的参数部分,作为即将传递的参数字符串的占位符,而且parallel也要使用在下一个程序前面。需要注意的是:传递的参数是分散开传递的。比如说一个多行字符串"1234\n1234\n1234"会被传递成三个单行字符串"1234","1234","1234"。
假设一个文本文件中,每一行都是一个地址,我们想并行下载所有链接的文件,那么可以使用:
cat abc.txt | parallel wget {}
但是面对比如说使用grep批量查询abc.txt中含有abc的行有哪些,如果还使用上面这样的传递,由于是分散开传递的,那么这个单独的字符串会被当作文件名:
cat abc.txt | parallel grep abc {}
结果如下:
$ cat abc.txt | parallel grep abc {}
grep: bfjksa: No such file or directory
grep: afhjha,fsj: No such file or directory
grep: abcshjagf: No such file or directory
grep: a;hfahabc: No such file or directory
grep: ahsfhmabc: No such file or directory
在这种就不要使用并行化,因为读取硬盘上的文件实际上是串行的,对单个或多个文件使用并行读取或写入几乎不会有任何性能提升,有时甚至还会降低(跳来跳去比顺序读取当然慢了)。
比如说官方有个例子是查找当前目录下所有文件中含有某一字符串的行,这里我查找main这个字符串:
$ time find . -type f | parallel grep -H -n main {}
./mem_disk_speedtest_in_C/.git/config:10:[branch "main"]
...real 0m26.651s
user 0m3.351s
sys 0m1.030s
而不使用 GNU Parallel 的命令为(并不是直接删除parallel部分就行了,需要做出一些调整):
$ time grep -H -n main $(find . -type f)
./mem_disk_speedtest_in_C/.git/config:10:[branch "main"]
...real 0m22.247s
user 0m3.204s
sys 0m0.809s
可以看到慢了 18%。这是比较坏的情况,一般情况下,用不用 GNU Parallel 速度都没什么变化。
更多选项请见官方文档:GNU Parallel Tutorial
二者的速度区别
实际测试上,直接在命令最后使用&要比使用GNU parallel慢一些(应该就是因为调度损耗了一部份性能),如下:
| 方法 | 运行时间(秒) |
|---|---|
| 串行 | 237.9 |
& | 152.1 |
| GNU parallel | 121.3 |
但是由于这里使用的 CPU 缓存较少,所以解压速度也没有 8 倍的提升,但是提升一倍也是不错的了。
扩展
正如开头所说,make是可以并行生成一些文件,而且可以通过-j选项设置最大并行任务数量。我们也可以利用这点来解压提取文件,但这并不是一个正经的办法,仅限于开拓眼界,因为有点“脱裤子放屁”的感觉(因为生成Makefile中的target部分需要使用CMake或者Bash来自动生成),正经使用的时候还是不要使用这种方法。
这个方法是我在 Running commands in parallel with a limit of simultaneous number of commands - superuser 中看到的,进行了一些尝试,可以说除了奇特毫无优点(通用性比不过&,易用性比不过 GNU Parallel),所以不推荐使用。
参考资料
Parallelize a Bash FOR Loop - Unix StackExchange
Can I use pipe output as a shell script argument? - superuser stackexchange