做商城网站要请程序员吗百度怎么推广自己的视频
用Python分析《三国演义》中的人物关系网
- 三国演义
- 获取文本
- 文本预处理
- 分词与词频统计
- 引入停用词后进行词频统计
- 构建人物关系网
- 完整代码
三国演义
《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间的纷争与英雄们的传奇故事。今天,我们将通过Python,初步探索《三国演义》的文本处理,感受这部古典名著的魅力。
获取文本
我们需要从本地读取《三国演义》的文本文件。
# 读取本地《三国演义》文本文件
with open('三国演义.txt', 'r', encoding='utf-8') as file:sanguo_text = file.read()输出看一下读取的文件内容:
print(sanguo_text[:30])
输出如下:

文本预处理
对文本进行分词前,先去除标点符号,使用正则库re来进行。
import re# 去除标点符号和特殊字符
sanguo_text = re.sub(r'[^\w\s]', '', sanguo_text)
sanguo_text = re.sub(r'\n', '', sanguo_text)
分词与词频统计
使用jieba库进行中文分词,并进行词频统计,输出频率最高的10个词。
import jieba
from collections import Counter
# 使用jieba进行分词
words = jieba.lcut(sanguo_text)
# 统计词频
word_counts = Counter(words)# 输出出现频率最高的10个词
print(word_counts.most_common(10))
当前输出如下:
[('曰', 7669), ('之', 2797), ('也', 2232), ('吾', 1815), ('与', 1722), ('将', 1643), ('而', 1600), ('了', 1397), ('有', 1386), ('在', 1286)]
可以看到,现在大多数是一些语气助词。这里我们要引入停用词。
引入停用词后进行词频统计
在文本处理中,停用词是指那些在文本分析中没有实际意义的词汇,如“的”、“了”、“在”等。在进行词频统计时,我们通常会去除这些停用词,以便更准确地分析有意义的词汇。
import jieba
from collections import Counter
# 使用jieba进行分词
words = jieba.lcut(sanguo_text)# 读取停用词列表
with open('常用停用词.txt', 'r', encoding='utf-8') as file:stopwords = set(file.read().split())# 去除停用词
filtered_words = [word for word in words if word not in stopwords]# 统计词频
word_counts = Counter(filtered_words)
# 输出出现频率最高的10个词
print(word_counts.most_common(10))当前输出:
[('曹操', 938), ('孔明', 809), ('玄德', 494), ('丞相', 489), ('关公', 478), ('荆州', 412), ('玄德曰', 385), ('孔明曰', 382), ('张飞', 349), ('商议', 343)]
我使用的停用词文件:

实际上可以根据自己的需求进行调整。
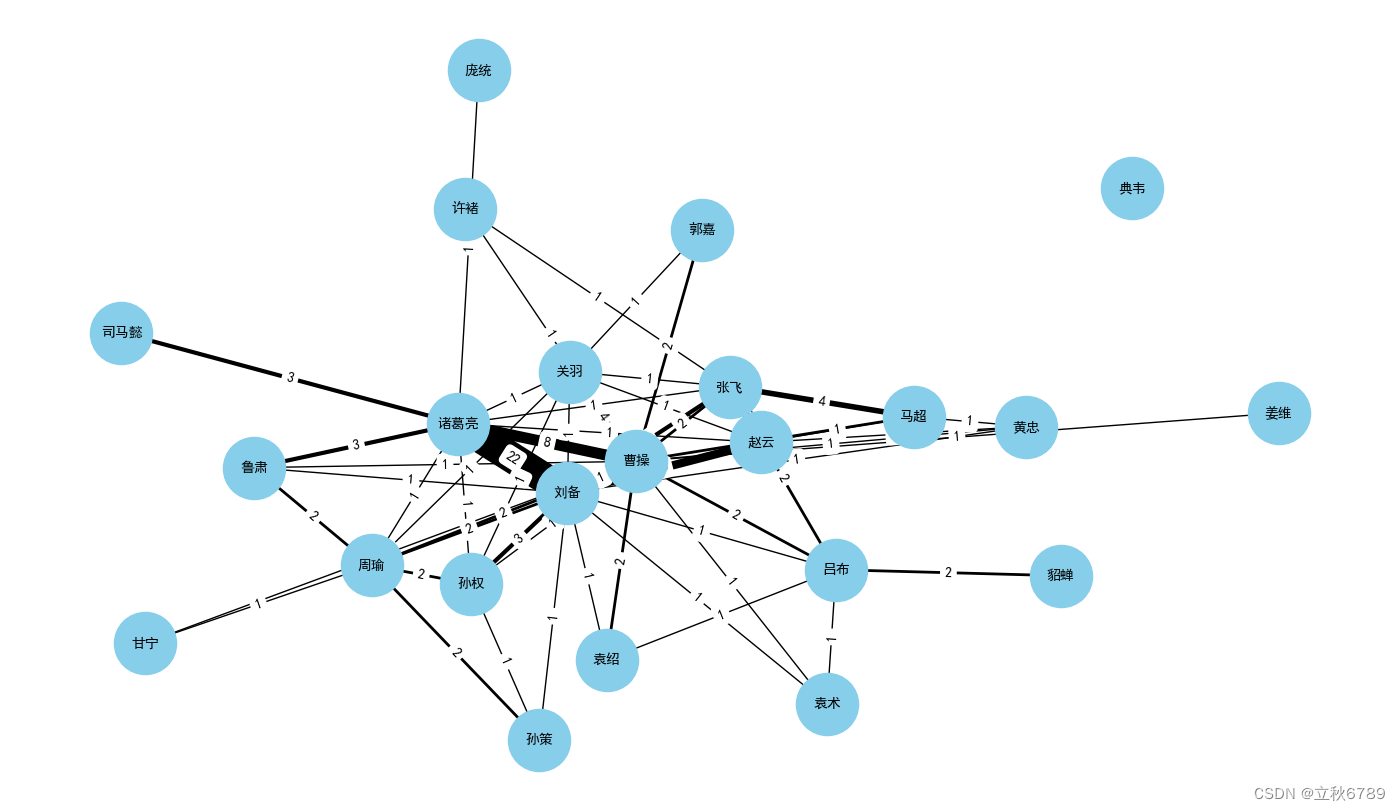
构建人物关系网
注意:三国中人物可能有多个称呼,比如说刘备也可以用玄德称呼
# 三国演义主要人物及其别名列表(扩展版)
characters = {"刘备": ["刘备", "玄德", "皇叔"],"关羽": ["关羽", "云长"],"张飞": ["张飞", "翼德"],"曹操": ["曹操", "孟德", "丞相", "曹孟德"],"孙权": ["孙权", "仲谋"],"诸葛亮": ["诸葛亮", "孔明", "卧龙"],"周瑜": ["周瑜", "公瑾"],"吕布": ["吕布", "奉先"],"貂蝉": ["貂蝉"],"赵云": ["赵云", "子龙"],"黄忠": ["黄忠", "汉升"],"马超": ["马超", "孟起"],"许褚": ["许褚", "仲康"],"典韦": ["典韦"],"司马懿": ["司马懿", "仲达"],"郭嘉": ["郭嘉", "奉孝"],"袁绍": ["袁绍", "本初"],"袁术": ["袁术", "公路"],"孙策": ["孙策", "伯符"],"甘宁": ["甘宁", "兴霸"],"鲁肃": ["鲁肃", "子敬"],"庞统": ["庞统", "凤雏"],"姜维": ["姜维", "伯约"]
}# 创建一个人物关系计数字典
relation_counts = defaultdict(int)# 遍历文本,统计人物间的关系
for i in range(len(filtered_words) - 1):for name1, aliases1 in characters.items():if filtered_words[i] in aliases1:for name2, aliases2 in characters.items():if filtered_words[i + 1] in aliases2 and name1 != name2:relation_counts[(name1, name2)] += 1# 创建网络图
G = nx.Graph()# 添加节点
for character in characters.keys():G.add_node(character)# 添加边及权重
for (name1, name2), count in relation_counts.items():G.add_edge(name1, name2, weight=count)# 绘制关系图
plt.figure(figsize=(14, 10))
pos = nx.spring_layout(G, k=1)
edges = G.edges(data=True)
weights = [edge[2]['weight'] for edge in edges]# 绘制节点和边
nx.draw(G, pos, with_labels=True, node_size=2000, node_color='skyblue', font_size=10, font_weight='bold', width=weights)# 在图中显示边的权重
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)plt.title('《三国演义》人物关系网(扩展版)')
plt.show()
完整代码
import re
import jieba
from collections import Counter, defaultdict
import networkx as nx
import matplotlib.pyplot as plt
from pylab import mpl# 设置中文字体,确保图表中能显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei']# 读取本地《三国演义》文本文件
with open('三国演义.txt', 'r', encoding='utf-8') as file:sanguo_text = file.read()# 去除标点符号和换行符
sanguo_text = re.sub(r'[^\w\s]', '', sanguo_text)
sanguo_text = re.sub(r'\n', '', sanguo_text)# 使用jieba进行分词
words = jieba.lcut(sanguo_text)# 读取停用词列表
with open('常用停用词.txt', 'r', encoding='utf-8') as file:stopwords = set(file.read().split())# 去除停用词
filtered_words = [word for word in words if word not in stopwords]# 三国演义主要人物及其别名列表(扩展版)
characters = {"刘备": ["刘备", "玄德", "皇叔"],"关羽": ["关羽", "云长"],"张飞": ["张飞", "翼德"],"曹操": ["曹操", "孟德", "丞相", "曹孟德"],"孙权": ["孙权", "仲谋"],"诸葛亮": ["诸葛亮", "孔明", "卧龙"],"周瑜": ["周瑜", "公瑾"],"吕布": ["吕布", "奉先"],"貂蝉": ["貂蝉"],"赵云": ["赵云", "子龙"],"黄忠": ["黄忠", "汉升"],"马超": ["马超", "孟起"],"许褚": ["许褚", "仲康"],"典韦": ["典韦"],"司马懿": ["司马懿", "仲达"],"郭嘉": ["郭嘉", "奉孝"],"袁绍": ["袁绍", "本初"],"袁术": ["袁术", "公路"],"孙策": ["孙策", "伯符"],"甘宁": ["甘宁", "兴霸"],"鲁肃": ["鲁肃", "子敬"],"庞统": ["庞统", "凤雏"],"姜维": ["姜维", "伯约"]
}# 创建一个人物关系计数字典
relation_counts = defaultdict(int)# 遍历文本,统计人物间的关系
for i in range(len(filtered_words) - 1):for name1, aliases1 in characters.items():if filtered_words[i] in aliases1:for name2, aliases2 in characters.items():if filtered_words[i + 1] in aliases2 and name1 != name2:relation_counts[(name1, name2)] += 1# 创建网络图
G = nx.Graph()# 添加节点
for character in characters.keys():G.add_node(character)# 添加边及权重
for (name1, name2), count in relation_counts.items():G.add_edge(name1, name2, weight=count)# 绘制关系图
plt.figure(figsize=(14, 10))
pos = nx.spring_layout(G, k=1)
edges = G.edges(data=True)
weights = [edge[2]['weight'] for edge in edges]# 绘制节点和边
nx.draw(G, pos, with_labels=True, node_size=2000, node_color='skyblue', font_size=10, font_weight='bold', width=weights)# 在图中显示边的权重
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)plt.title('《三国演义》人物关系网(扩展版)')
plt.show()