做网站需要知道什么软件抖音seo排名优化公司

目录
一.引言
二.模型下载
三.快速测试
四.训练数据
五.总结
一.引言
自打 LLama-2 发布后就一直在等大佬们发布 LLama-2 的适配中文版,也是这几天蹲到了一版由 LinkSoul 发布的 Chinese-Llama-2-7b,其共发布了一个常规版本和一个 4-bit 的量化版本,今天我们主要体验下 Llama-2 的中文逻辑顺便看下其训练样本的样式,后续有机会把训练和微调跑起来。
二.模型下载
HuggingFace: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b
4bit 量化版本: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b-4bit
这里我们先整一版量化版本:
省事且网络好的同学可以直接用 Hugging Face 的 API 下载,网不好就半夜慢慢下载吧。
from huggingface_hub import hf_hub_download, snapshot_downloadsnapshot_download(repo_id="LinkSoul/Chinese-Llama-2-7b-4bit", local_dir='./models')三.快速测试
Tips 测试用到的基本库的版本,运行显卡为 Tesla-V100 32G:
python 3.9.11
numpy==1.23.5
torch==2.0.1
transformers==4.29.1
测试代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer# Original version
# model_path = "LinkSoul/Chinese-Llama-2-7b"
# 4 bit version
model_path = "/models/LLama2_4bit"tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
if model_path.endswith("4bit"):model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,device_map='auto')
else:model = AutoModelForCausalLM.from_pretrained(model_path).half().cuda()
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)instruction = """[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n{} [/INST]"""while True:text = input("请输入 prompt\n")if text == "q":breakprompt = instruction.format(text)generate_ids = model.generate(tokenizer(prompt, return_tensors='pt').input_ids.cuda(), max_new_tokens=4096, streamer=streamer)★ 常规测试
知识:

推理:

★ 一些 Bad Case
知识错乱:

重复:

这里由于是 4-bit 的量化版本,模型的效果可能也会受影响,可以看到图中原始 LLama2 的知识能力相对还算不错。
四.训练数据
LinkSoul 在 LLama2 的基础上使用了中英文 SFT 数据集,数据量 1000 万:
LinkSoul/instruction_merge_set · Datasets at Hugging Face
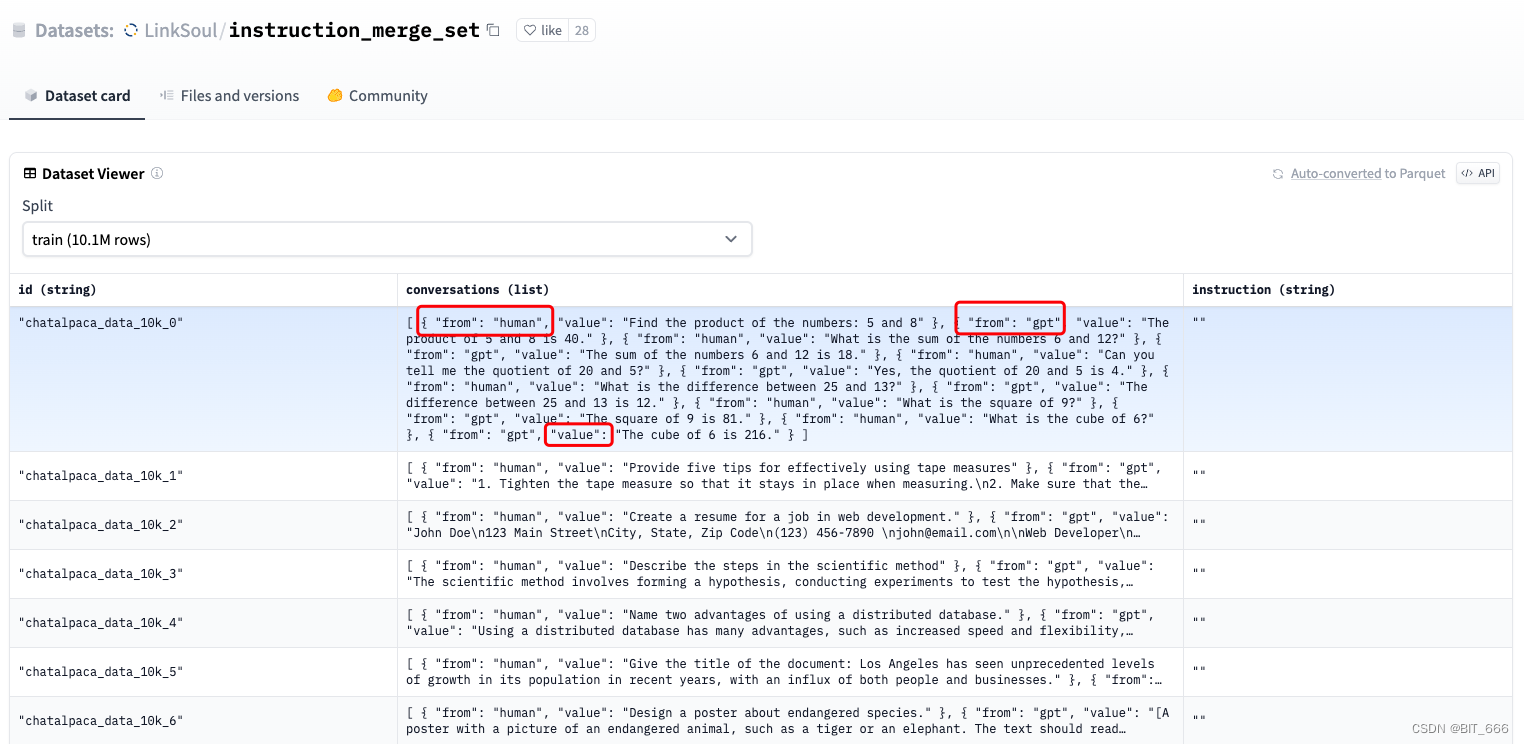
给定的数据是 parquet 格式的:
{"instruction":"","id":"chatalpaca_data_10k_0","conversations":"WrappedArray([human,Find the product of the numbers: 5 and 8], [gpt,The product of 5 and 8 is 40.], [human,What is the sum of the numbers 6 and 12?], [gpt,The sum of the numbers 6 and 12 is 18.], [human,Can you tell me the quotient of 20 and 5?], [gpt,Yes, the quotient of 20 and 5 is 4.], [human,What is the difference between 25 and 13?], [gpt,The difference between 25 and 13 is 12.], [human,What is the square of 9?], [gpt,The square of 9 is 81.], [human,What is the cube of 6?], [gpt,The cube of 6 is 216.])"}
{"instruction":"","id":"chatalpaca_data_10k_1","conversations":"WrappedArray([human,Provide five tips for effectively using tape measures], [gpt,1. Tighten the tape measure so that it stays in place when measuring.\n2. Make sure that the hook of the tape measure hits the starting point precisely.\n3. Allow for a bit of slack when measuring around curves or corners.\n4. Measure from a stable surface, such as a table or workbench.\n5. Mark the beginning and end of each measurement with a pen or marker.], [human,Can you give me an example of when to use tip number three, \"Allow for a bit of slack when measuring around curves or corners\"?], [gpt,Sure! Let's say you're measuring the circumference of a circular object, like a pipe. If you pull the tape measure too tightly, you won't get an accurate measurement because the tape measure will be stretched out of its original shape, making the measurement longer than it should be. Instead, you should wrap the tape measure around the curve or corner of the object without pulling it too tightly. This way, you'll get a more accurate measurement that takes into account the shape of the object.], [human,Can you tell me more about the markers or pens that should be used to mark the measurements? Do you recommend a certain type of pen?], [gpt,As an AI language model, I do not have personal preferences as a human, but there are certain types of markers or pens that are better suited for marking measurements than others. For example, a fine-tipped marker or mechanical pencil is great for making precise marks on a tape measure, because they produce a precise line that is easy to see. You'll want to avoid using a ballpoint pen or a marker with a thick tip, since these types of pens can produce marks that are too thick or blurry, making it difficult to accurately read the measurement. It's also a good idea to choose a marker or pen that is a different color than the color of the tape measure, so that you can easily distinguish your marks from the printed markings on the tape measure.], [human,Are there any other tips you recommend for maintaining tape measures in good condition? \n\nassistant: \nYes! One tip is to keep your tape measure clean and free from debris, so that it moves smoothly and doesn't get jammed or stuck. You can use a soft cloth or a brush to wipe down the tape measure after each use, and make sure to store it in a dry place to prevent rust or corrosion. Another tip is to avoid dropping or mishandling the tape measure, since this can damage the internal components and make it less accurate. It's also a good idea to periodically check your tape measure against a known length or standard to make sure that it is still measuring accurately.], [gpt,Finally, when retracting the tape measure, avoid letting it snap back quickly, as this can cause the tape to twist or become tangled. Instead, hold it firmly and retract it slowly and steadily to avoid damaging the internal components. With proper care and maintenance, your tape measure should last for years and provide accurate measurements every time.], [human,Goodbye.])"}instruction 指令可选,剩下 conversations 里是 human 和 gpt 的多轮对话。
def tokenize(item, tokenizer):roles = {"human": "user", "gpt": "assistant"}input_ids = []labels = []if "instruction" in item and len(item["instruction"]) > 0:system = item["instruction"]else:system = dummy_message["system"]system = B_SYS + system + E_SYS# add system before the first content in conversationsitem["conversations"][0]['value'] = system + item["conversations"][0]['value']for i, turn in enumerate(item["conversations"]):role = turn['from']content = turn['value']content = content.strip()if role == 'human':content = f"{B_INST} {content} {E_INST} "content_ids = tokenizer.encode(content)labels += [IGNORE_TOKEN_ID] * (len(content_ids))else:# assert role == "gpt"content = f"{content} "content_ids = tokenizer.encode(content, add_special_tokens=False) + [tokenizer.eos_token_id] # add_special_tokens=False remove bos token, and add eos at the endlabels += content_idsinput_ids += content_idsinput_ids = input_ids[:tokenizer.model_max_length]labels = labels[:tokenizer.model_max_length]trunc_id = last_index(labels, IGNORE_TOKEN_ID) + 1input_ids = input_ids[:trunc_id]labels = labels[:trunc_id]if len(labels) == 0:return tokenize(dummy_message, tokenizer)input_ids = safe_ids(input_ids, tokenizer.vocab_size, tokenizer.pad_token_id)labels = safe_ids(labels, tokenizer.vocab_size, IGNORE_TOKEN_ID)return input_ids, labels训练代码:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b/blob/main/train.py
中展示了 tokenizer 原始样本的流程:
◆ 根据指令生成 system
◆ 根据 from 和 value 的多轮对话生成 input_ids 和 labels
Tips: 这里会把前面生成的 system 缀到第一个 value 前面,labels 会在 human 部分用 IGNORE_TOKEN_ID 的掩码进行 Mask
◆ 最后 safe_ids 用于限制 id < max_value 超过使用 pad_id 进行填充
def safe_ids(ids, max_value, pad_id):return [i if i < max_value else pad_id for i in ids]这里输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。
五.总结
这里简单介绍了 LLama-2 7B Chinese 的推理和数据样式,后续有机会训练和微调该模型。
参考:
Chinese Llama 2 7B: https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
Model: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b
Instruction_merge_set: https://huggingface.co/datasets/LinkSoul/instruction_merge_set/
Download Files: https://huggingface.co/docs/huggingface_hub/v0.16.3/guides/download