从做系统网站的收藏怎么找东莞做网站哪家好
目录标题
- 机器学习的根本问题
- 过拟合overfitting
- 泛化能力差。
- 应对过拟合
- 最优方案
- 次优方案
- 调节模型大小
- 约束模型权重,即权重正则化(常用的有L1、L2正则化)
- L1 正则化
- L2 正则化
- 对异常值的敏感性
- 随机失活(Dropout)
- 随机失活的问题
- 欠拟合
机器学习的根本问题
机器学习的根本问题是优化与泛化问题。
- 优化:是指调节模型以在训练数据上得到最佳性能。
- 泛化:是指训练好的模型在前所未见的数据上的性能好坏。
过拟合overfitting
出现过拟合,得到的模型在训练集上的准确率很高,但是在真实的场景下识别率确很低。
泛化能力差。
过拟合overfitting:指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测的很好,但对未知数据预测得很差的现象。这种情况下模型可能只是记住了训练集数据,而不是学习到了数据特征。
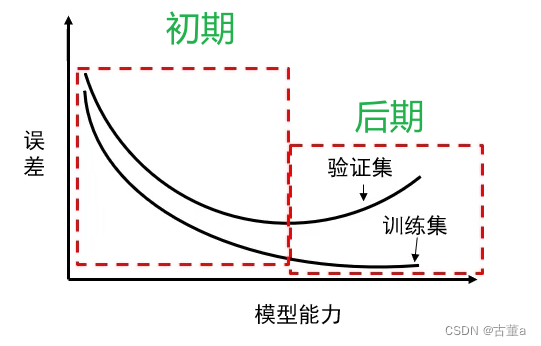
- 训练初期:优化和泛化是相关的;训练集上的误差越小,验证集上的误差也越小,模型的泛化能力逐渐增强。
- 训练后期:模型在验证集上的错误率不再降低转而开始变高。模型出现过拟合,开始学习仅和训练数据有关的模式。
应对过拟合
最优方案
获取更多的训练数据
增加更多的训练样本可以帮助模型更好地学习数据的真实分布,减少过拟合的风险。
次优方案
调节模型允许存储的信息量或者对模型允许存储的信息加以约束,该类方法也被称为正则化。
调节模型大小
约束模型权重,即权重正则化(常用的有L1、L2正则化)
L1 正则化
L1正则化(Lasso正则化):L1正则化使用模型权重的L1范数作为正则化项,即权重的绝对值之和。

L1正则化的效果是推动模型的权重向稀疏的方向学习,即将某些权重变为零,使得模型具有稀疏性。这对于特征选择和模型简化很有用。
L2 正则化
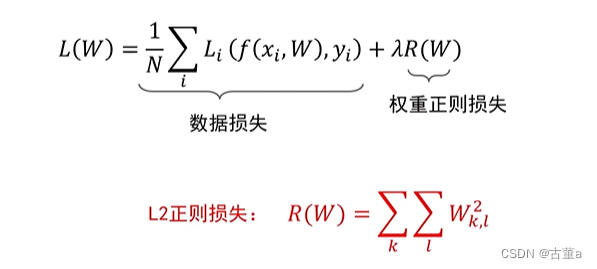
L2正则化(Ridge正则化):L2正则化使用模型权重的L2范数作为正则化项,即权重的平方和的平方根。

L2正则损失对于大数值的权值向量进行严厉惩罚,鼓励更加分散的权重向量,使模型倾向于使用所有输入特征做决策,此时的模型泛化性能好!
对异常值的敏感性
- L1正则化对异常值比较敏感,因为它的正则化项是绝对值之和,异常值的存在会对权重产生较大的影响。
- L2正则化对异常值相对较不敏感,因为它的正则化项是平方和的平方根,异常值对权重的影响相对较小。
随机失活(Dropout)
让隐层的神经元以一定的概率不被激活。
实现方式:
训练过程中,对某一层使用Dropout,就是随机将该层的一些输出舍弃(输出值设置为0),这些被舍弃的神经元就好像被网络删除了一样。
随机失活比率(Dropout ratio):
是被设为0的特征所占的比例,通常在0.2~0.5范围内。

随机失活为什么能够防止过拟合呢?
解释一:随机失活使得每次更新梯度时参与计算的网络参数减少了,降低了模型容量,所以能够防止过拟合。
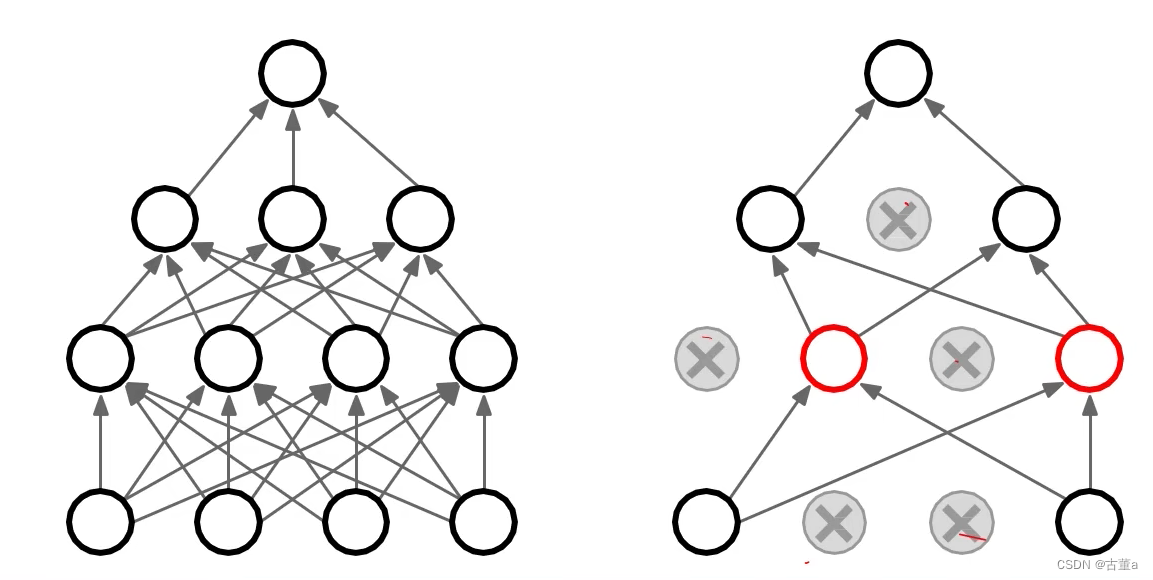
解释二:随机失活鼓励权重分散,从这个角度来看随机失活也能起到正则化的作用,进而防止过拟合。
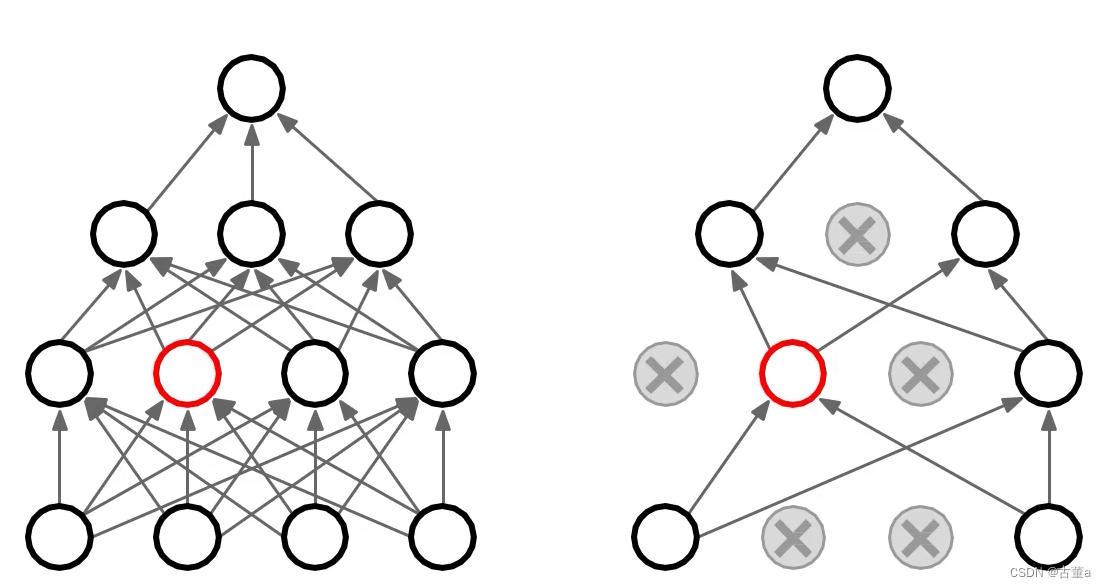
- 通过随机失活,在训练过程中,将一部分神经元的输出置为零,相当于随机断开了这些神经元与其他神经元之间的连接。这样做的结果是,每个神经元都不再依赖于其他特定的神经元,而是需要通过其他神经元来进行信息传递。因此,网络中的神经元被鼓励去学习更加独立和分散的特征表示,而不是过度依赖于某些特定的神经元。
- 这种随机失活的效果是,网络的不同部分在训练过程中会以更加均衡的方式进行学习,权重会分散到更多的神经元上。这有助于避免某些特定的神经元或权重集中承担大部分的计算负载,从而提高网络的鲁棒性和泛化能力。
解释三:Dropout可以看作模型集成。

- Dropout可以被解释为在训练过程中对多个不同的子模型进行训练,每个子模型都是通过保留一部分神经元并且随机设置其他神经元的输出为零来实现的。在测试阶段,为了获得更稳定的预测结果,通常会对这些子模型的预测结果进行平均或投票。
随机失活的问题
训练过程中使用随机失活,测试过程中不随机失活。要保证两者结果相似,需要进行修改。

在测试过程中,不进行随机失活,而是将Dropout的参数p乘以输出。
上图例子中p=1 / 2
- 训练E[a] = 测试E[a] * p = 测试E[a] * 1 / 2
- 训练E[a] / p = 训练E[a] / (1 / 2) = 测试E[a]
代码示例:
则训练E[a] = 测试E[a] * p = 测试E[a] * 1 / 2

训练E[a] / p = 训练E[a] / (1 / 2) = 测试E[a]

欠拟合
模型描述能力太弱,以至于不能很好地学习到数据中的归路。产生欠拟合的原因通常是模型过于简单。