设计本接单大厅文章优化软件
-
解决问题
有时候将文档上传Claude2做分析,有大小限制,所以需要切割pdf文档为几个小点的文档,故才有了本文章。
如何用Python和PyMuPDF制作你想要大小的PDF?
PDF是一种广泛使用的文件格式,可以在任何设备上查看和打印。但是,有时您可能只需要查看PDF文件中的前几页,而不是整个文件。在这种情况下,将PDF文件转换为只包含指定页数的新文件可能是有用的。本文将介绍如何使用Python和PyMuPDF模块来实现此任务。
-
安装PyMuPDF模块
在使用PyMuPDF之前,我们需要先安装它。可以使用以下命令来安装PyMuPDF:
pip install PyMuPDF-
导入PyMuPDF和wxPython模块
接下来,我们需要导入PyMuPDF和wxPython模块:
import fitz
import wx-
创建GUI界面
为了方便用户输入PDF文件和页码数量,我们将创建一个简单的GUI界面。我们将使用wxPython模块来创建GUI界面。以下是代码示例:
class PDFExtractorFrame(wx.Frame):def __init__(self, *args, **kw):super(PDFExtractorFrame, self).__init__(*args, **kw)panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)self.file_picker = wx.FilePickerCtrl(panel, message="选择PDF文件", wildcard="PDF Files (*.pdf)|*.pdf",style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL)vbox.Add(self.file_picker, 0, wx.EXPAND | wx.ALL, 10)self.page_input = wx.TextCtrl(panel, value="1", style=wx.TE_PROCESS_ENTER)vbox.Add(self.page_input, 0, wx.EXPAND | wx.ALL, 10)extract_button = wx.Button(panel, label="提取", size=(70, 30))extract_button.Bind(wx.EVT_BUTTON, self.on_extract)vbox.Add(extract_button, 0, wx.ALIGN_CENTER | wx.ALL, 10)panel.SetSizer(vbox)self.Bind(wx.EVT_TEXT_ENTER, self.on_extract, self.page_input)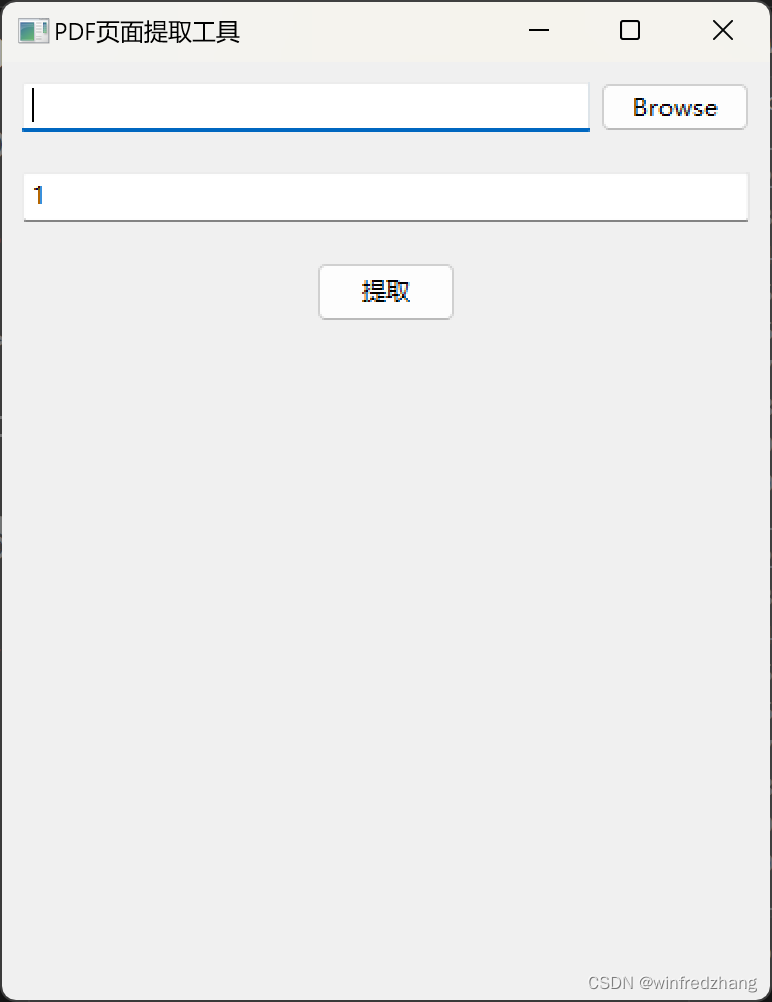
此代码创建一个名为PDFExtractorFrame的wx.Frame类,并在其构造函数中创建GUI界面元素。它创建了一个wx.Panel对象和两个wx.BoxSizer对象来放置GUI元素。在此GUI界面中,用户可以选择PDF文件和输入要保留的页码数量。
-
实现转换功能
接下来,我们需要实现转换功能。我们将使用PyMuPDF模块来打开PDF文件,并使用它来复制指定数量的页面。以下是代码示例:
def extract_pages(self, input_pdf, page_number, output_pdf):# 打开PDF文档pdf_document = fitz.open(input_pdf)total_pages = pdf_document.page_count# 确保页码不超过文档的总页数page_number = min(page_number, total_pages)# 创建新的PDF文档,只包含指定页码之前的内容pdf_writer = fitz.open()for page in range(page_number):pdf_writer.insert_pdf(pdf_document, from_page=page, to_page=page)# 保存新的PDF文档到指定路径pdf_writer.save(output_pdf)pdf_writer.close()pdf_document.close()此代码使用PyMuPDF模块将PDF文件转换为只包含前N页的新PDF文件的函数。该函数将源PDF文件路径,要提取的页数和新PDF文件的输出路径作为参数,并返回无返回值。以下是该函数的详细说明:
- input_pdf: 源PDF文件的路径。
- page_number: 要提取的页数。
- output_pdf: 新PDF文件的输出路径。
该函数使用fitz.open()函数打开输入PDF文件并获取其总页数。如果指定的页码数量超过文档的总页数,则将其设置为文档的总页数。
在创建新的PDF文档之前,该函数创建一个空的PDF文档对象。然后,它使用insert_pdf()函数从源PDF文件中复制每个页面,并将其插入到新的PDF文档对象中。该函数只复制指定数量的页面。
最后,该函数使用save()函数将新PDF文档保存到指定的输出路径,并使用close()函数关闭所有打开的PDF文档对象以释放资源。
-
运行应用程序
 |  |
-
完整代码
import fitz # PyMuPDF
import wxclass PDFExtractorApp(wx.App):def OnInit(self):self.frame = PDFExtractorFrame(None, title="PDF页面提取工具")self.SetTopWindow(self.frame)self.frame.Show()return Trueclass PDFExtractorFrame(wx.Frame):def __init__(self, *args, **kw):super(PDFExtractorFrame, self).__init__(*args, **kw)panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)self.file_picker = wx.FilePickerCtrl(panel, message="选择PDF文件", wildcard="PDF Files (*.pdf)|*.pdf",style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL)vbox.Add(self.file_picker, 0, wx.EXPAND | wx.ALL, 10)self.page_input = wx.TextCtrl(panel, value="1", style=wx.TE_PROCESS_ENTER)vbox.Add(self.page_input, 0, wx.EXPAND | wx.ALL, 10)extract_button = wx.Button(panel, label="提取", size=(70, 30))extract_button.Bind(wx.EVT_BUTTON, self.on_extract)vbox.Add(extract_button, 0, wx.ALIGN_CENTER | wx.ALL, 10)panel.SetSizer(vbox)self.Bind(wx.EVT_TEXT_ENTER, self.on_extract, self.page_input)def on_extract(self, event):input_pdf = self.file_picker.GetPath()output_pdf = "output.pdf"try:page_number = int(self.page_input.GetValue())self.extract_pages(input_pdf, page_number, output_pdf)wx.MessageBox("PDF页面提取完成!", "成功", wx.OK | wx.ICON_INFORMATION)except ValueError:wx.MessageBox("无效的页码输入!", "错误", wx.OK | wx.ICON_ERROR)def extract_pages(self, input_pdf, page_number, output_pdf):# 打开PDF文档pdf_document = fitz.open(input_pdf)total_pages = pdf_document.page_count# 确保页码不超过文档的总页数page_number = min(page_number, total_pages)# 创建新的PDF文档,只包含指定页码之前的内容pdf_writer = fitz.open()for page in range(page_number):pdf_writer.insert_pdf(pdf_document, from_page=page, to_page=page)# 保存新的PDF文档到指定路径pdf_writer.save(output_pdf)pdf_writer.close()pdf_document.close()if __name__ == '__main__':app = PDFExtractorApp()app.MainLoop()
C:\pythoncode\new\copypdfsaveas.py