网站开发企业培训有哪些推广平台和渠道
文章目录
- 1项目介绍
- 2参考文章
- 3代码的实现过程及对代码的详细解析
- 独热编码
- 定义生成器
- 定义判别器
- 打印我们的引导信息
- 模型训练
- 迭代过程中生成的图片
- 损失函数的变化
- 4总结
- 5 模型相关的文件
1项目介绍
在GAN的基础上进行有条件的引导生成图片cgan
2参考文章
GAN实战之Pytorch 使用CGAN生成指定MNIST手写数字
GANs系列:CGAN(条件GAN)原理简介以及项目代码实现
3代码的实现过程及对代码的详细解析
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import os
for dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
from torch.utils import data
import os
import glob
from PIL import Image
独热编码
# 输入x代表默认的torchvision返回的类比值,class_count类别值为10
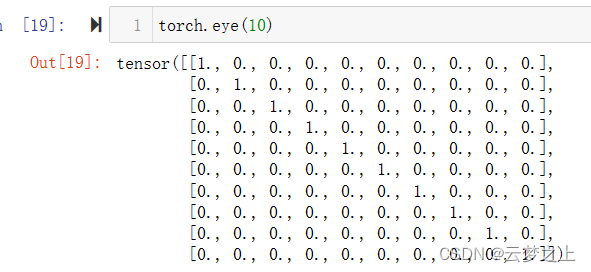
def one_hot(x, class_count=10):return torch.eye(class_count)[x, :] # 切片选取,第一维选取第x个,第二维全要
torch.eye(10)函数的作用是生成一个10*10的对角矩阵
该函数的作用是得到第x个位置为1的独热编码,如果传入为列表,则得到一个矩阵
transform =transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.5, 0.5)])#minist数据集中的图片数据的维度是[batch_size, 1, 28, 28],其中batch_size是每个批次的图像数量。这个数据集中的每个图像都是28x28像素的灰度图像,因此它们只有一个通道
dataset = torchvision.datasets.MNIST('data',train=True,transform=transform,target_transform=one_hot,download=True)
#这里target_transform参数的作用是对标签进行转换。在这个例子中,它的作用是将标签转换为one-hot编码。
dataloader = data.DataLoader(dataset, batch_size=64, shuffle=True)定义生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()#因此,这个函数的输入张量维度为[batch_size, 10]和[batch_size, 100],输出张量维度为[batch_size, 1, 1, 1]。self.linear1 = nn.Linear(10, 128 * 7 * 7)self.bn1 = nn.BatchNorm1d(128 * 7 * 7)self.linear2 = nn.Linear(100, 128 * 7 * 7)self.bn2 = nn.BatchNorm1d(128 * 7 * 7)#这个函数的作用是将一个输入张量进行反卷积操作,得到一个输出张量。#nn.ConvTranspose2d函数的作用是将一个256通道的输入张量转换为一个128通道的输出张量,使用3x3的卷积核进行卷积操作,并在卷积操作后进行1像素的paddingself.deconv1 = nn.ConvTranspose2d(256, 128,kernel_size=(3, 3),padding=1)self.bn3 = nn.BatchNorm2d(128)self.deconv2 = nn.ConvTranspose2d(128, 64,kernel_size=(4, 4),stride=2,padding=1)self.bn4 = nn.BatchNorm2d(64)self.deconv3 = nn.ConvTranspose2d(64, 1,kernel_size=(4, 4),stride=2,padding=1)def forward(self, x1, x2):x1 = F.relu(self.linear1(x1))x1 = self.bn1(x1)x1 = x1.view(-1, 128, 7, 7)x2 = F.relu(self.linear2(x2))x2 = self.bn2(x2)x2 = x2.view(-1, 128, 7, 7)#将两个处理后的结果拼接在一起,得到形状为[64, 256, 7, 7]的张量x = torch.cat([x1, x2], axis=1)x = F.relu(self.deconv1(x))#形状变为为[64, 128, 7, 7]的张量x = self.bn3(x)x = F.relu(self.deconv2(x))#形状变为为[64, 64, 14, 14]的张量x = self.bn4(x)# 形状变为为[64, 1, 28, 28]的张量x = torch.tanh(self.deconv3(x))return x
生成器对数据的处理过程:
这个函数对于输入张量[64, 1, 28, 28]的维度变化过程如下:
输入张量维度为[64, 1, 28, 28]
经过线性变换和ReLU激活函数处理后,得到两个形状为[64, 128 * 7 * 7]的张量
将两个张量分别通过BatchNorm1d进行归一化处理
将两个处理后的结果reshape成形状为[64, 128, 7, 7]的张量
将两个处理后的结果拼接在一起,得到形状为[64, 256, 7, 7]的张量
经过反卷积操作得到输出张量,维度为[64, 1, 28, 28]
定义判别器
# input:1,28,28的图片以及长度为10的condition
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.linear = nn.Linear(10, 1*28*28)self.conv1 = nn.Conv2d(2, 64, kernel_size=3, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2)self.bn = nn.BatchNorm2d(128)self.fc = nn.Linear(128*6*6, 1) # 输出一个概率值def forward(self, x1, x2):#leak_relu激活函数:它在输入小于0时返回一个小的斜率,而在输入大于等于0时返回输入本身x1 =F.leaky_relu(self.linear(x1))x1 = x1.view(-1, 1, 28, 28)#torch.cat([x1, x2], axis=1)函数将张量x1和张量x2沿着第二个维度(即列)拼接起来x = torch.cat([x1, x2], axis=1)#处理过后变为(64,2,28,28)x = F.dropout2d(F.leaky_relu(self.conv1(x)))#维度变为(64,64,13,13)x = F.dropout2d(F.leaky_relu(self.conv2(x)))#维度变为(64,128,6,6)x = self.bn(x)x = x.view(-1, 128*6*6)#最后键位了64*1(同时把值映射到0~1之间)x = torch.sigmoid(self.fc(x))return x# 初始化模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)# 损失计算函数
loss_function = torch.nn.BCELoss()# 定义优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-5)
g_optim = torch.optim.Adam(gen.parameters(), lr=1e-4)# 定义可视化函数
def generate_and_save_images(model, epoch, label_input, noise_input):#生成器生成取片,label_input为输入的引导信息,noise_input为随机的噪声点predictions = np.squeeze(model(label_input, noise_input).cpu().numpy())#numpy.squeeze()函数的作用是去掉矩阵里维度为1的维度。fig = plt.figure(figsize=(4, 4))for i in range(predictions.shape[0]):plt.subplot(4, 4, i + 1)plt.imshow((predictions[i] + 1) / 2, cmap='gray')plt.axis("off")from IPython.display import FileLinkplt.savefig('data/img/image_at_epoch_{:04d}.png'.format(epoch))plt.show()import os
os.makedirs("data/img")
打印我们的引导信息
noise_seed = torch.randn(16, 100, device=device)label_seed = torch.randint(0, 10, size=(16,))
label_seed_onehot = one_hot(label_seed).to(device)print(label_seed)
tensor([1, 3, 5, 4, 9, 3, 0, 0, 1, 3, 4, 5, 9, 2, 3, 7])
模型训练
D_loss = []
G_loss = []
# 训练循环
for epoch in range(150):d_epoch_loss = 0g_epoch_loss = 0count = len(dataloader.dataset)# 对全部的数据集做一次迭代#dataloader中的图像是四维的。在for循环中,每次迭代会返回一个batch_size大小的数据#其中每个数据都是一个四维张量,形状为[batch_size, channels, height, width]for step, (img, label) in enumerate(dataloader):img = img.to(device)label = label.to(device)size = img.shape[0]random_noise = torch.randn(size, 100, device=device)d_optim.zero_grad()real_output = dis(label, img)d_real_loss = loss_function(real_output,torch.ones_like(real_output, device=device))#torch.ones_like(real_output, device=device)函数的作用是生成一个与real_output形状相同的张量,其中所有元素都为1。 d_real_loss.backward() #求解梯度# 得到判别器在生成图像上的损失gen_img = gen(label,random_noise)fake_output = dis(label, gen_img.detach()) # 判别器输入生成的图片,f_o是对生成图片的预测结果d_fake_loss = loss_function(fake_output,torch.zeros_like(fake_output, device=device))d_fake_loss.backward()d_loss = d_real_loss + d_fake_lossd_optim.step() # 优化# 得到生成器的损失g_optim.zero_grad()fake_output = dis(label, gen_img)g_loss = loss_function(fake_output,torch.ones_like(fake_output, device=device))g_loss.backward()g_optim.step()with torch.no_grad():d_epoch_loss += d_loss.item()g_epoch_loss += g_loss.item()with torch.no_grad():d_epoch_loss /= countg_epoch_loss /= countD_loss.append(d_epoch_loss)G_loss.append(g_epoch_loss)if epoch % 10 == 0:print('Epoch:', epoch)generate_and_save_images(gen, epoch, label_seed_onehot, noise_seed)print("epoch:{}/150".format(epoch))plt.plot(D_loss, label='D_loss')
plt.plot(G_loss, label='G_loss')
plt.legend()
plt.show()迭代过程中生成的图片
迭代1次

迭代10次

迭代20次

迭代30次

迭代40次

迭代150次

损失函数的变化

4总结
cGAN相比于GAN而言,将label的信息通过一系列的卷积操作和图像的信息融合在一起,然后放进模型进行训练,让我们的模型能和label相匹配的图像,从而在我们给出制定的数字label时能够生成对应的数字图片,实现了引导的过程。
5 模型相关的文件
模型的相关文件:提取码(ujki)
本模型是放在kaggle中运行的,kaggle的部署流程请参考:在kaggle中用GPU训练模型