高仿奢侈手表网站挖掘关键词的工具
目录
1.池化技术
2.数据库连接池的定义
3.为什么要使用连接池
4. 数据库连接池的运行机制
5. 连接池与线程池的关系
6. CResultSet的设计
6.1构造函数
7. CDBConn的设计
6.1.构造函数
6.2.init——初始化连接
8.数据库连接池的设计要点
9.接口设计
9.1 构造函数
9.2 请求获取连接
9.3 释放连接
9.4 析构连接
9.5 mysql重连机制
10. 连接池数量设置
经验公式
实际分析
1.池化技术
池化技术能够 减少资源对象的创建次数,提高程序的响应性能,特别是在 高并发下这种提高更加明显。 使用池化技术缓存的资源对象有如下共同特点:
1. 对象创建时间长;
2. 对象创建需要大量资源;
3. 对象创建后可被重复使用
像常见的 线程池、内存池、连接池、对象池 都具有以上的共同特点。
2.数据库连接池的定义
数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成 一个连接池,由程序 动态地对池中的连接进行 申请,使用,释放。
3.为什么要使用连接池
1.资源的复用
由于 数据库 连接得到复用,避免了 频繁的创建、释放连接引起的性能开销,在减少系统消耗的基础 上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数 量)。
2.更快的响应速度
数据库连接池在初始化过程中,已经创建了若干数据库连接置于池中备用。对于业务请求处理而言,直接利用现有可用连接,避免了从数据库连接初始化和释 放过程的开销,从而缩减了响应时间,提高了响应速度
3. 统一的连接管理,避免数据库连接泄露
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而 避免了常规数据库连接操作中可能出现的资源泄露
4. 数据库连接池的运行机制
1. 从连接池获取或创建可用连接;
2. 使用完毕之后,把连接返回给连接池;
3. 在系统关闭前,断开所有连接并释放连接占用的系统资源;

5. 连接池与线程池的关系
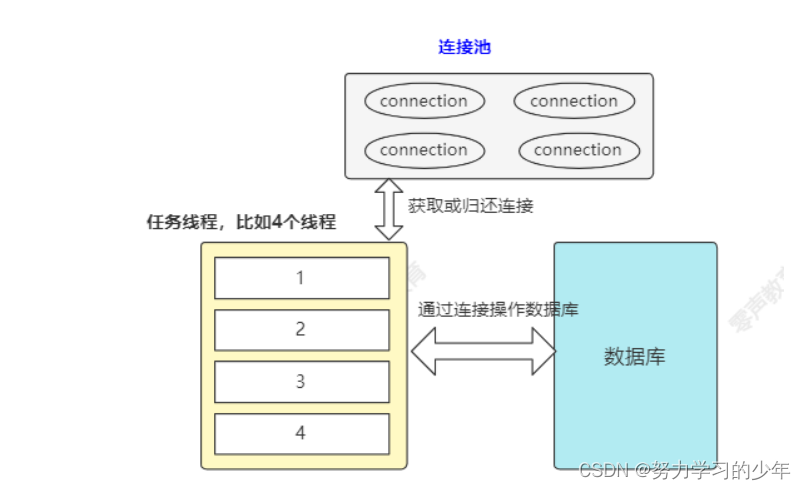
当线程池中 某个线程 执行任务的时候 需要访问数据库的时候,需要从连接池中获取到空闲的连接,任务处理完毕后,线程 再将连接归还给连接池。
线程池与连接池的区别:
线程池:主动操作,主动获取任务并执行任务
连接池:被动操作,池的对象被任务获取,执行完任务后归还
6. CResultSet的设计
// 返回结果 select的时候用
class CResultSet {
public:CResultSet(MYSQL_RES* res);virtual ~CResultSet();bool Next();//获取下一行数据int GetInt(const char* key); //获取int类型的value值char* GetString(const char* key);//获取字符串类型的value值
private:int _GetIndex(const char* key);MYSQL_RES* m_res;MYSQL_ROW m_row;map<string, int> m_key_map;
};6.1构造函数
//将所有行数据存储到 m_row中,将字段名存储到 m_key_map,并记录其id
CResultSet::CResultSet(MYSQL_RES *res)
{m_res = res;// map table field key to index in the result arrayint num_fields = mysql_num_fields(m_res);MYSQL_FIELD *fields = mysql_fetch_fields(m_res);for (int i = 0; i < num_fields; i++){// 将表头数据存储到m_key_map中m_key_map.insert(make_pair(fields[i].name, i));}
}根据字段名获取 下标
int CResultSet::_GetIndex(const char *key)
{map<string, int>::iterator it = m_key_map.find(key);if (it == m_key_map.end()){return -1;}else{return it->second;}
}//根据key 获取 int 类型 value值
int CResultSet::GetInt(const char *key)
{int idx = _GetIndex(key);if (idx == -1){return 0;}else{return atoi(m_row[idx]); // 有索引}
}//根据 key值获取 字符串类型 value值
char *CResultSet::GetString(const char *key)
{int idx = _GetIndex(key);if (idx == -1){return NULL;}else{return m_row[idx]; // 列}
}//获取下一行数据
bool CResultSet::Next()
{m_row = mysql_fetch_row(m_res);if (m_row){return true;}else{return false;}
}
7. CDBConn的设计
CDBConn是一个 自主封装的 MySQL连接,从连接池中获取到的连接时一个CDBConn对象类型。
class CDBConn {
public:CDBConn(CDBPool* pDBPool);virtual ~CDBConn();int Init();// 创建表bool ExecuteCreate(const char* sql_query);// 删除表bool ExecuteDrop(const char* sql_query);// 查询CResultSet* ExecuteQuery(const char* sql_query);bool ExecuteUpdate(const char* sql_query, bool care_affected_rows = true);uint32_t GetInsertId();// 开启事务bool StartTransaction();// 提交事务bool Commit();// 回滚事务bool Rollback();// 获取连接池名const char* GetPoolName();MYSQL* GetMysql() { return m_mysql; }
private:CDBPool* m_pDBPool; // to get MySQL server informationMYSQL* m_mysql; // 对应一个连接
};6.1.构造函数
CDBConn::CDBConn(CDBPool *pPool)
{m_pDBPool = pPool;m_mysql = NULL;
}
6.2.init——初始化连接
int CDBConn::Init()
{m_mysql = mysql_init(NULL); // mysql_标准的mysql c client对应的apiif (!m_mysql){log_error("mysql_init failed\n");return 1;}my_bool reconnect = true;mysql_options(m_mysql, MYSQL_OPT_RECONNECT, &reconnect); // 配合mysql_ping实现自动重连mysql_options(m_mysql, MYSQL_SET_CHARSET_NAME, "utf8mb4"); // utf8mb4和utf8区别// ip 端口 用户名 密码 数据库名if (!mysql_real_connect(m_mysql, m_pDBPool->GetDBServerIP(), m_pDBPool->GetUsername(), m_pDBPool->GetPasswrod(),m_pDBPool->GetDBName(), m_pDBPool->GetDBServerPort(), NULL, 0)){log_error("mysql_real_connect failed: %s\n", mysql_error(m_mysql));return 2;}return 0;
}8.数据库连接池的设计要点
连接池的设计思路:
1.连接到数据库,涉及到 数据库ip、端口、用户名、密码、数据库名字等;
- 配置最小的连接数和 最大连接数
2.定义一个队列管理 连接
3.获取连接对象的 接口
4.归还连接对象的接口
5. 定义连接池的名称
class CDBPool { // 只是负责管理连接CDBConn,真正干活的是CDBConn
public:CDBPool() {}CDBPool(const char* pool_name, const char* db_server_ip, uint16_t db_server_port,const char* username, const char* password, const char* db_name, int max_conn_cnt);virtual ~CDBPool();int Init(); // 连接数据库,创建连接CDBConn* GetDBConn(const int timeout_ms = 0); // 获取连接资源void RelDBConn(CDBConn* pConn); // 归还连接资源const char* GetPoolName() { return m_pool_name.c_str(); }const char* GetDBServerIP() { return m_db_server_ip.c_str(); }uint16_t GetDBServerPort() { return m_db_server_port; }const char* GetUsername() { return m_username.c_str(); }const char* GetPasswrod() { return m_password.c_str(); }const char* GetDBName() { return m_db_name.c_str(); }
private:string m_pool_name; // 连接池名称string m_db_server_ip; // 数据库ipuint16_t m_db_server_port; // 数据库端口string m_username; // 用户名string m_password; // 用户密码string m_db_name; // db名称int m_db_cur_conn_cnt; // 当前启用的连接数量int m_db_max_conn_cnt; // 最大连接数量list<CDBConn*> m_free_list; // 空闲的连接list<CDBConn*> m_used_list; // 记录已经被请求的连接std::mutex m_mutex;std::condition_variable m_cond_var;bool m_abort_request = false;// CThreadNotify m_free_notify; // 信号量
};
9.接口设计
9.1 构造函数
CDBPool::CDBPool(const char *pool_name, const char *db_server_ip, uint16_t db_server_port,const char *username, const char *password, const char *db_name, int max_conn_cnt)
{m_pool_name = pool_name;m_db_server_ip = db_server_ip;m_db_server_port = db_server_port;m_username = username;m_password = password;m_db_name = db_name;m_db_max_conn_cnt = max_conn_cnt; // m_db_cur_conn_cnt = MIN_DB_CONN_CNT; // 最小连接数量
}9.2 Init 初始化
创建固定的最小的连接数,并将连接存放到 空闲队列中。
int CDBPool::Init()
{// 创建固定最小的连接数量for (int i = 0; i < m_db_cur_conn_cnt; i++){CDBConn *pDBConn = new CDBConn(this);int ret = pDBConn->Init();if (ret){delete pDBConn;return ret;}m_free_list.push_back(pDBConn);}// log_info("db pool: %s, size: %d\n", m_pool_name.c_str(), (int)m_free_list.size());return 0;
}9.2 请求获取连接
请连接流程

CDBConn *CDBPool::GetDBConn(const int timeout_ms)
{std::unique_lock<std::mutex> lock(m_mutex);//m_abort_request 判断连接池是否被终止if(m_abort_request) {log_warn("have aboort\n");return NULL;}if (m_free_list.empty()) // 当没有连接可以用时{// 第一步先检测 当前连接数量是否达到最大的连接数量 if (m_db_cur_conn_cnt >= m_db_max_conn_cnt){// 如果已经到达了,看看是否需要超时等待if(timeout_ms <= 0) // 死等,直到有连接可以用 或者 连接池要退出{log_info("wait ms:%d\n", timeout_ms);m_cond_var.wait(lock, [this] {// log_info("wait:%d, size:%d\n", wait_cout++, m_free_list.size());// 当前连接数量小于最大连接数量 或者请求释放连接池时退出return (!m_free_list.empty()) | m_abort_request;});} else {// return如果返回 false,继续wait(或者超时), 如果返回true退出wait// 1.m_free_list不为空// 2.超时退出// 3. m_abort_request被置为true,要释放整个连接池m_cond_var.wait_for(lock, std::chrono::milliseconds(timeout_ms), [this] {// log_info("wait_for:%d, size:%d\n", wait_cout++, m_free_list.size());return (!m_free_list.empty()) | m_abort_request;});// 带超时功能时还要判断是否为空if(m_free_list.empty()) // 如果连接池还是没有空闲则退出{return NULL;}}if(m_abort_request) {log_warn("have aboort\n");return NULL;}}else // 还没有到最大连接则创建连接{CDBConn *pDBConn = new CDBConn(this); //新建连接int ret = pDBConn->Init();if (ret){log_error("Init DBConnecton failed\n\n");delete pDBConn;return NULL;}else{m_free_list.push_back(pDBConn);m_db_cur_conn_cnt++;// log_info("new db connection: %s, conn_cnt: %d\n", m_pool_name.c_str(), m_db_cur_conn_cnt);}}}CDBConn *pConn = m_free_list.front(); // 获取连接m_free_list.pop_front(); // STL 吐出连接,从空闲队列删除m_used_list.push_back(pConn);//将连接存放到被使用的 链表中return pConn;
}9.3 释放连接
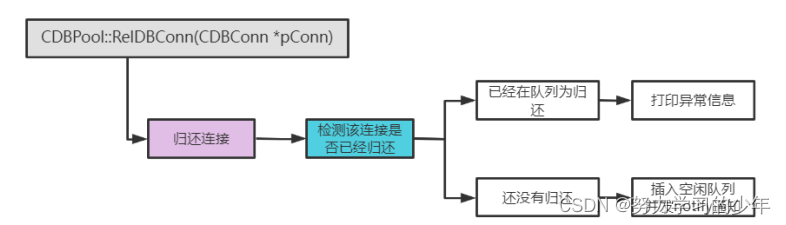
void CDBPool::RelDBConn(CDBConn *pConn)
{std::lock_guard<std::mutex> lock(m_mutex);list<CDBConn *>::iterator it = m_free_list.begin();for (; it != m_free_list.end(); it++) // 避免重复归还{if (*it == pConn) {break;}}if (it == m_free_list.end()){m_used_list.remove(pConn);m_free_list.push_back(pConn);m_cond_var.notify_one(); // 通知取队列} else {log_error("RelDBConn failed\n");}
}9.4 析构连接
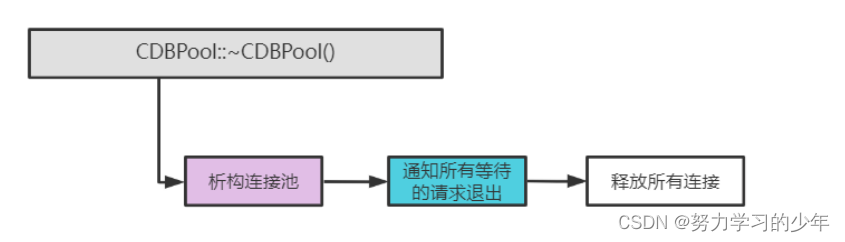
CDBPool::~CDBPool()
{std::lock_guard<std::mutex> lock(m_mutex);m_abort_request = true;m_cond_var.notify_all(); // 通知所有在等待的线程for (list<CDBConn *>::iterator it = m_free_list.begin(); it != m_free_list.end(); it++){CDBConn *pConn = *it;delete pConn;}m_free_list.clear();
}
9.5 mysql重连机制
1.设置重连机制属性
//1. 设置启用(当发现连接断开时的)自动重连, 配合mysql_ping实现自动重连
my_bool reconnect = true;
mysql_options(m_mysql, MYSQL_OPT_RECONNECT, &reconnect); 2. 检测连接是否正常
int STDCALL mysql_ping(MYSQL *mysql);描述:
检查与服务端的连接是否正常。连接断开时,如果自动重新连接功能未被禁用,则尝试重新连接服务 器。该函数可被客户端用来检测闲置许久以后,与服务端的连接是否关闭,如有需要,则重新连接。
返回值:
连接正常,返回0;如有错误发生,则返回非0值。返回非0值并不意味着服务器本身关闭掉,也有可能 是网络原因导致网络不通。
10. 连接池数量设置
经验公式
连接数 = ((核心数 * 2) + 有效磁盘数)
按照这个公式,即是说你的服务器 CPU 是 4核 i7 的,那连接池连接数大小应该为 ((4*2)+1)=9
这里只是一个经验公式,还要和线程池数量以及业务结合在一起吗,根据经验公式的连接数的上下去测试连接池性能瓶颈。
实际分析
如果任务整体上是一个IO密集型的任务。在处理一个请求的过程中(处理一个任务),总共耗时 100+5=105ms,而其中只有 5ms是用于计算操作的(消耗cpu),另外的100ms等待io响应,CPU利用 率为5/(100+5)。
使用线程池是为了尽量提高CPU的利用率,减少对CPU资源的浪费,假设以100%的CPU利用率来说,要 达到100%的CPU利用率,对于一个CPU就要设置其利用率的倒数个数的线程数,也即 1/(5/(100+5))=21,4个CPU的话就乘以4。那么算下来的话,就是……84,这个时候线程池要设置84个线 程数,然后连接池的最大连接数量也是设置为84个连接