模板网站建设价位专业的郑州网站推广

之前的文章有关于更多操作方式详细解答,本篇基于前面的知识点进行操作,如果不了解可以先看之前的文章
Python爬虫(1)一次性搞定Selenium(新版)8种find_element元素定位方式
Python爬虫(2)-Selenium控制浏览器
Python爬虫(3)-Selenium结合pywin32模拟键盘操作
Python爬虫(4)-Selenium模拟鼠标操作
Python爬虫(5)-selenium用显式等待、隐式等待、强制等待,解决反复爬取网页时无法定位元素问题
Python爬虫(6)-selenium用requests、wget、urllib3这3种方法搞定图片和PDF文件下载
Python爬虫(7)selenium3种弹窗定位后点击操作,解决点击登录被隐藏iframe无法点击的登陆问题
Python爬虫(8)selenium爬虫后数据,存入sqlit3实现增删改查
Python爬虫(10)selenium爬虫后数据,存入csv、txt并将存入数据提取存入另一个文件
- 存入csv
- python自带方法
- 完整代码
- pandas方式查询文件
- 存入txt
- python自带方法
- pandas方式查询文件
本篇继续引用之前爬取房地产的信息作为存入的数据来源
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get("https://hui.fang.anjuke.com/loupan/all/a1_m94-95_o8_w1_z3/")
def sc():housename = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[1]/span').texthouseaddress = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[2]/span').texthousearea = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[3]').text#连接数据库,如果数据库中没有相应的数据库名称会自动创建一个print(housename,houseaddress,housearea)if __name__ == "__main__":sc()

在写入之前需要学习python的不同模式打开文件的方式,这个非常有用
| 模式 | 描述 |
|---|---|
| r | 只读方法打开文件,默认模式,无法对文件进行修改和添加 |
| rb | 二进制打开一个文件以只读模式 |
| r+ | 打开一个文件用于读写 |
| rb+ | 以二进制格式打开一个文件用户读写 |
| w | 以二进制格式打开文件用于写入,如果存在就打开文件,不然就从头开始编辑,原有内容删除,如果文件不存在就自动创建新文件 |
| w+ | 打开一个文件用于读写,如果文件存在就打开文件,从头开始编辑,原有内容删除,如果文件不存在就创建新文件 |
| wb+ | 以二进制格式打开,如果文件存在就打开,原有内容删除,文件不存在则创建 |
| a | 追加模式,新内容追加到原有内容之后,文件不存在则创建新文件 |
| ab | 以二进制模式追加,如果文件存在 |
| a+ | 打开一个文件用于读写,如果文件存在,在原有内容追加内容进去,不存在就创建新内容用于读写 |
| ab+ | 以二进制格式打开一个文件用于追加,如果文件存在则将文件放于结尾追加内容,不存在创建新文件用于读写 |
更多具体的操作方式看下面这篇文章
Python3 输入和输出
存入csv
python自带方法
由于我需要爬虫后写入所以需要选择以a+模式打开文件并进行写入操作
#用a+模式创建csv文件并写入f = open('house.csv', 'a+', encoding='utf-8')#基于文件对象构建csv写入csv_a = csv.writer(f)#将数据写入csv_a.writerow([housename,houseaddress,housearea])#关闭文件f.close()
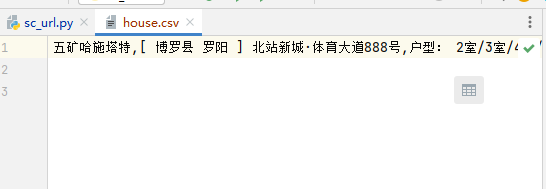
完整代码
import csv
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get("https://hui.fang.anjuke.com/loupan/all/a1_m94-95_o8_w1_z3/")
def sc():housename = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[1]/span').texthouseaddress = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[2]/span').texthousearea = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[3]').text#连接数据库,如果数据库中没有相应的数据库名称会自动创建一个print(housename,houseaddress,housearea)#用a+模式创建csv文件并写入f = open('house.csv', 'a+', encoding='utf-8')#基于文件对象构建csv写入csv_a = csv.writer(f)#将数据写入csv_a.writerow([housename,houseaddress,housearea])#关闭文件f.close()if __name__ == "__main__":sc()
pandas方式查询文件
这种方法是一次性显示所有的csv里面的内容,如果要将信息单次一条一条插入进行爬虫,就可以用for循环
import pandas as pd#导入pandas
df = pd.read_csv("house.csv", encoding='utf-8')print(df)

存入txt
python自带方法
#打开txt文件以a+模式写入sctxt = open('house.txt',mode='a+', encoding="utf-8")#将爬虫后的文件写入sctxt.writelines([housename,houseaddress,housearea])#关闭文件sctxt.close()
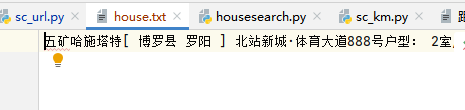
完整代码
import csv
import pandas as pd
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = Chrome(options=opt) # 创建Chrome无界面对象
driver.get("https://hui.fang.anjuke.com/loupan/all/a1_m94-95_o8_w1_z3/")
def sc():housename = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[1]/span').texthouseaddress = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[2]/span').texthousearea = driver.find_element(By.XPATH, '//*[@id="container"]/div[2]/div[1]/div[3]/div[1]/div/a[3]').text#连接数据库,如果数据库中没有相应的数据库名称会自动创建一个print(housename,houseaddress,housearea)#打开txt文件以a+模式写入sctxt = open('house.txt',mode='a+', encoding="utf-8")#将爬虫后的文件写入sctxt.writelines([housename,houseaddress,housearea])#关闭文件sctxt.close()
if __name__ == "__main__":sc()
pandas方式查询文件
df = pd.read_csv("house.txt", encoding='utf-8')print(df)
