深圳做生鲜食材的网站叫什么房地产网站模板
文章目录
- 一、简介
- 1、BeanFactoryPostProcessor
- 2、BeanPostProcessor
- 二、BeanFactoryPostProcessor 源码解析
- 1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程
- 2、BeanFactoryPostProcessor 接口实现类的处理流程
- 3、总结
- 三、BeanPostProcessor 源码解析
一、简介
Spring有两种类型的后置处理器,分别是 BeanFactoryPostProcessor 和 BeanPostProcessor ,这里再贴出我画的 Spring 启动过程,可以看看这两种后置处理器在 Spring 启动过程中位置。
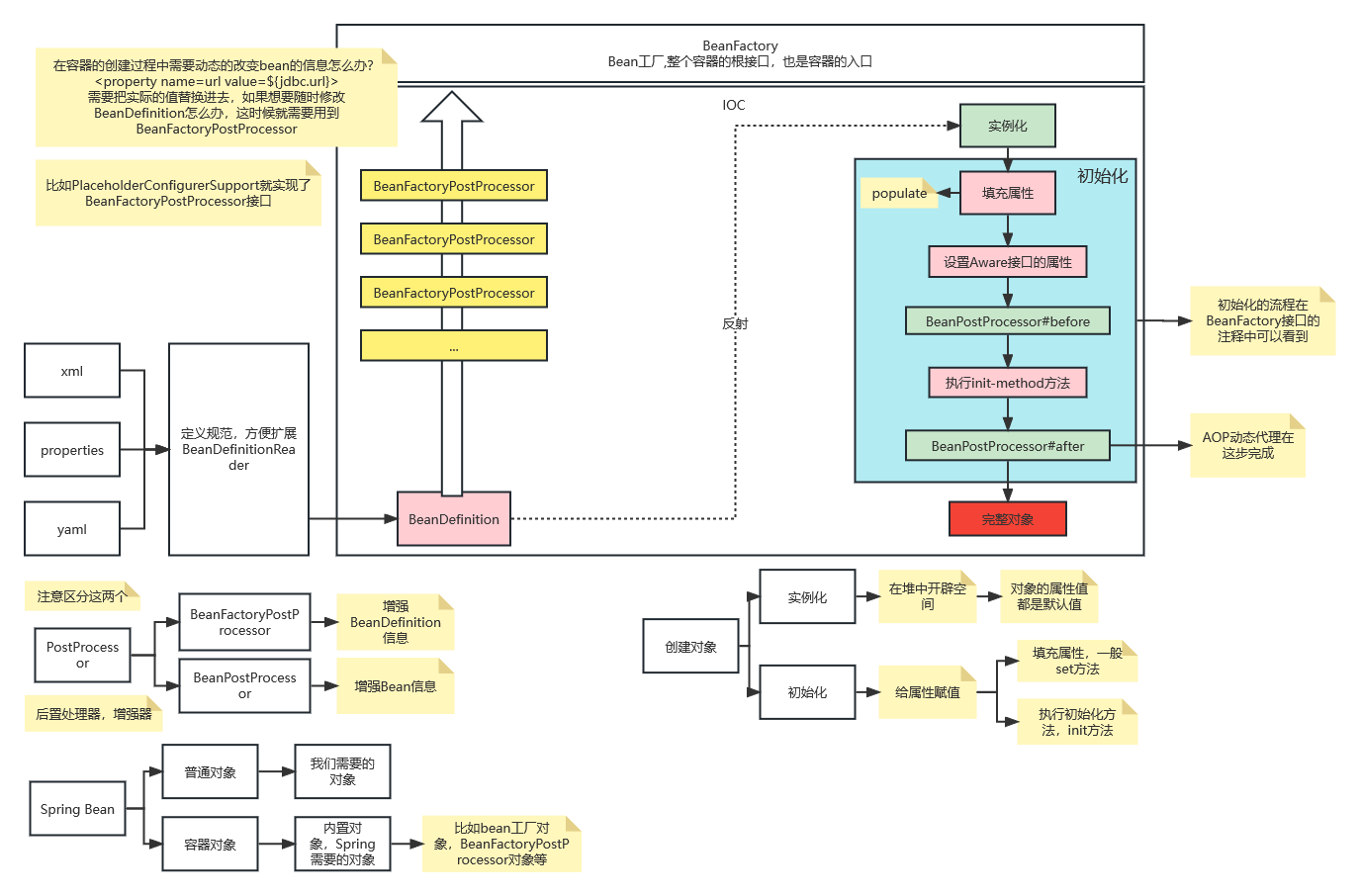
1、BeanFactoryPostProcessor
BeanFactoryPostProcessor 的 postProcessBeanFactory 方法在 Spring 容器启动时被调用,可以对整个容器中的 BeanDefinition (Bean 定义)进行处理,BeanFactoryPostProcessor 还有个子接口 BeanDefinitionRegistryPostProcessor ,其 postProcessBeanDefinitionRegistry 方法也可以对 BeanDefinition 进行处理的,但两个的侧重点不一样, BeanDefinitionRegistryPostProcessor 侧重于创建自定义的 BeanDefinition,而 BeanFactoryPostProcessor 侧重于对已有的 BeanDefinition 进行修改。
2、BeanPostProcessor
BeanPostProcessor 是在 Bean 初始化方法调用前后,对 Bean 进行一些预处理或后处理,这个接口有两个方法,分别是 postProcessBeforeInitialization 和 postProcessAfterInitialization,分别用来执行预处理和后处理。
二、BeanFactoryPostProcessor 源码解析
处理 BeanFactoryPostProcessor 的源码在哪里呢,我们先找到 Spring 的核心方法 refresh 方法(在 AbstractApplicationContext 类里),在里面找到 invokeBeanFactoryPostProcessors 方法
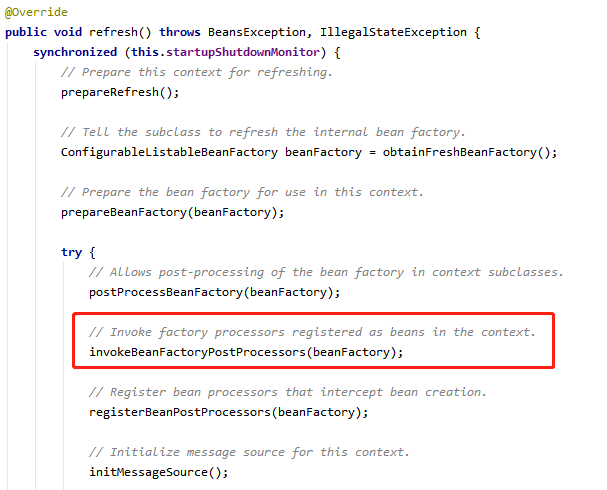
跟进去这个方法
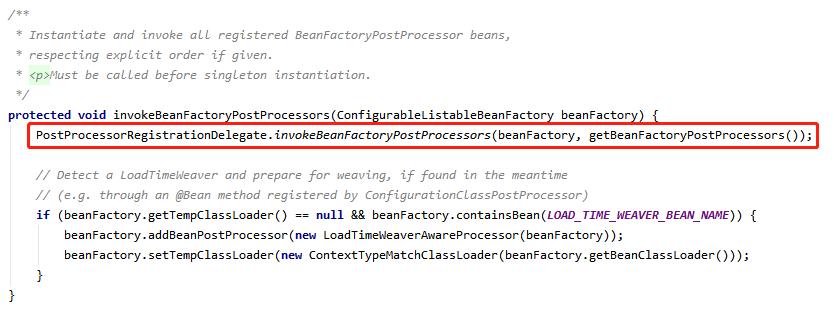
在跟进到 PostProcessorRegistrationDelegate 类的 invokeBeanFactoryPostProcessors 方法里,就到了核心处理逻辑了,先列出这个方法的代码
public static void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {// Invoke BeanDefinitionRegistryPostProcessors first, if any.Set<String> processedBeans = new HashSet<>();if (beanFactory instanceof BeanDefinitionRegistry) {BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {BeanDefinitionRegistryPostProcessor registryProcessor =(BeanDefinitionRegistryPostProcessor) postProcessor;registryProcessor.postProcessBeanDefinitionRegistry(registry);registryProcessors.add(registryProcessor);}else {regularPostProcessors.add(postProcessor);}}// Do not initialize FactoryBeans here: We need to leave all regular beans// uninitialized to let the bean factory post-processors apply to them!// Separate between BeanDefinitionRegistryPostProcessors that implement// PriorityOrdered, Ordered, and the rest.List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.String[] postProcessorNames =beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);for (String ppName : postProcessorNames) {if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));processedBeans.add(ppName);}}sortPostProcessors(currentRegistryProcessors, beanFactory);registryProcessors.addAll(currentRegistryProcessors);invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);currentRegistryProcessors.clear();// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);for (String ppName : postProcessorNames) {if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));processedBeans.add(ppName);}}sortPostProcessors(currentRegistryProcessors, beanFactory);registryProcessors.addAll(currentRegistryProcessors);invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);currentRegistryProcessors.clear();// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.boolean reiterate = true;while (reiterate) {reiterate = false;postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);for (String ppName : postProcessorNames) {if (!processedBeans.contains(ppName)) {currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));processedBeans.add(ppName);reiterate = true;}}sortPostProcessors(currentRegistryProcessors, beanFactory);registryProcessors.addAll(currentRegistryProcessors);invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);currentRegistryProcessors.clear();}// Now, invoke the postProcessBeanFactory callback of all processors handled so far.invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);}else {// Invoke factory processors registered with the context instance.invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);}// Do not initialize FactoryBeans here: We need to leave all regular beans// uninitialized to let the bean factory post-processors apply to them!String[] postProcessorNames =beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,// Ordered, and the rest.List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();List<String> orderedPostProcessorNames = new ArrayList<>();List<String> nonOrderedPostProcessorNames = new ArrayList<>();for (String ppName : postProcessorNames) {if (processedBeans.contains(ppName)) {// skip - already processed in first phase above}else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));}else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {orderedPostProcessorNames.add(ppName);}else {nonOrderedPostProcessorNames.add(ppName);}}// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.sortPostProcessors(priorityOrderedPostProcessors, beanFactory);invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);// Next, invoke the BeanFactoryPostProcessors that implement Ordered.List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();for (String postProcessorName : orderedPostProcessorNames) {orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));}sortPostProcessors(orderedPostProcessors, beanFactory);invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);// Finally, invoke all other BeanFactoryPostProcessors.List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();for (String postProcessorName : nonOrderedPostProcessorNames) {nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));}invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);// Clear cached merged bean definitions since the post-processors might have// modified the original metadata, e.g. replacing placeholders in values...beanFactory.clearMetadataCache();
}
这段代码比较长,我们可以分成两部分来看,前半部分处理 BeanDefinitionRegistryPostProcessors 接口的实现类,后半部分处理 BeanFactoryPostProcessor 接口的实现类,我们先看 BeanDefinitionRegistryPostProcessors 接口的处理流程
1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程
首先创建了一个名叫 processedBeans 的 HashSet

是为了记录处理过的 PostProcessor 的名字,目的是防止重复处理,然后下面对 beanFactory 的类型进行了判断,如果是 BeanDefinitionRegistry 类型,会有一大段的处理逻辑,如果不是,就调用 invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory); 方法
if (beanFactory instanceof BeanDefinitionRegistry) {...
}else {// Invoke factory processors registered with the context instance.invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
这个方法,其实就是循环执行所有 PostProcessor 的 postProcessBeanFactory 方法,我们再来看如果是 BeanDefinitionRegistry 类型,是怎么处理的,先看第一段
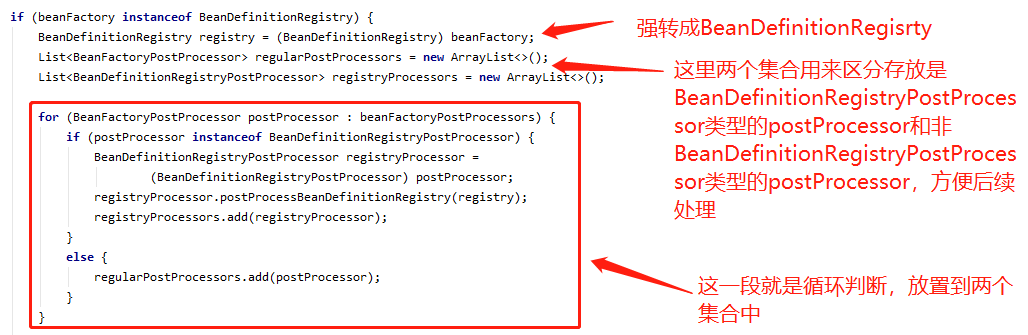
这一段是将传进来的参数 BeanFactoryPostProcessor 集合进行区分,分成 BeanDefinitionRegistryPostProcessor 类型(后面简称 BDRPP)和非 BeanDefinitionRegistryPostProcessor 类型,其实就是 BeanFactoryPostProcessor 类型(后面简称 BFPP),并执行了 BDRPP 类型的 postProcessBeanDefinitionRegistry 方法,并且,把两种类型分别添加到了两个集合里 registryProcessors 和 regularPostProcessors,继续往下看
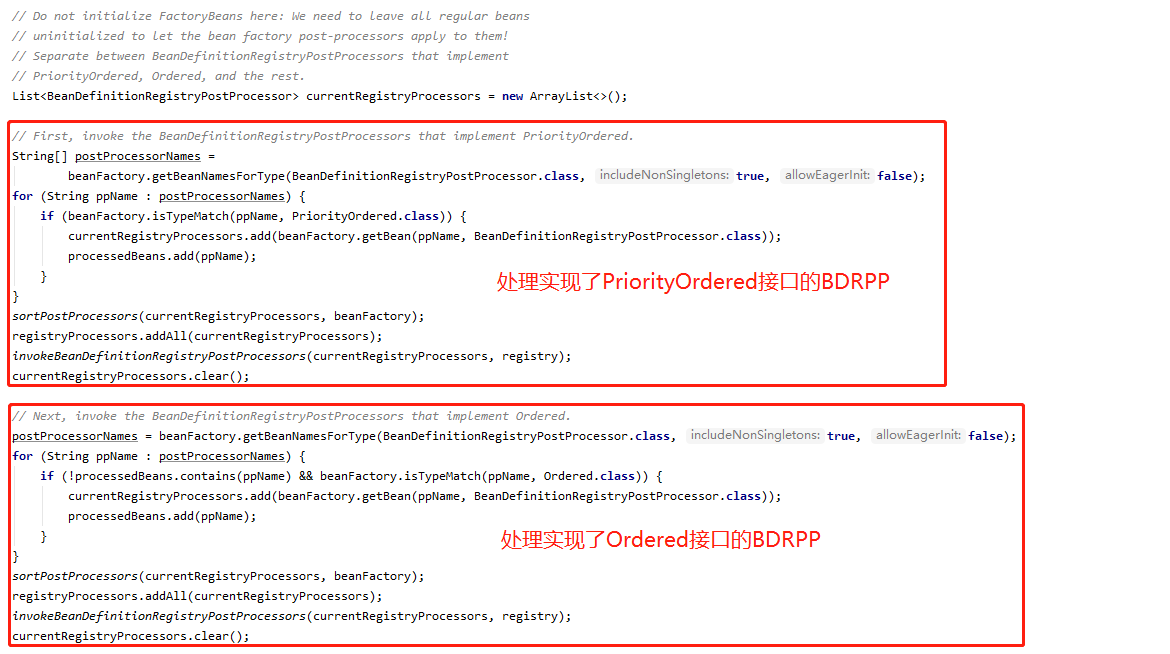
这一段,先声明了一个 BDRPP 类型的集合,用于存放在 Spring 容器里找到的 BDRPP,然后从 Spring 容器里找到所有 BDRPP 的名字,循环并找到实现了 PriorityOrdered 接口的 BDRPP,排序,添加到之前定义区分 BDRPP 和 BFPP 的集合 registryProcessors 里,然后执行了这些实现了 PriorityOrdered 接口的 BDRPP 的 postProcessBeanDefinitionRegistry 方法,下面以同样的方式处理实现了 Ordered 接口的 BDRPP,这里先科普下 PriorityOrdered 和 Ordered
PriorityOrdered和Ordered是 Spring 框架中用于定义 Bean 的加载顺序的接口。而PriorityOrdered是Ordered的子类,实现了这两个接口的类,需要实现一个getOrder()方法,返回一个 int 值,这个值越大,优先级就越低,而实现了PriorityOrdered接口的 Bean 的加载顺序会优先于实现了Ordered接口的Bean,且两者都优先于没实现这两个接口的 Bean
所以,这里先处理的实现了 PriorityOrdered 接口的 BDRPP ,再处理了实现了 Ordered 接口的 BDRPP ,有的人会好奇哦,为什么上面已经调用过一次 beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);,下面为什么还要再调一次,这不是重复代码了吗,其实不是,执行了 BDRPP 的 postProcessBeanDefinitionRegistry 方法,有可能会产生新的 BDRPP ,所以需要再重新取一次,继续看下面的代码
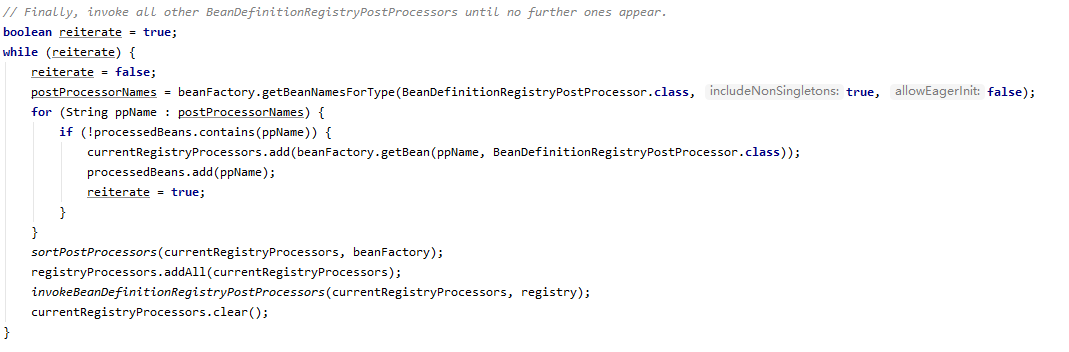
知道了执行了 BDRPP 的 postProcessBeanDefinitionRegistry 方法,有可能会产生新的 BDRPP ,这段就好理解了,一直循环获取 BDRPP,执行其 postProcessBeanDefinitionRegistry 方法,直到不产生新的 BDRPP 为止

最后,因为 BDRPP 是 BFPP 的子类,所以也是需要执行 BFPP 里的 postProcessBeanFactory 方法的,但是 BDRPP 的先执行,BFPP 的后执行。
到此 BDRPP 的处理完了,下面看 BFPP 的
2、BeanFactoryPostProcessor 接口实现类的处理流程
看完 BeanDefinitionRegistryPostProcessor 之后,BeanFactoryPostProcessor(后面简称 BFPP)的处理流程就比较简单了,先看第一段代码
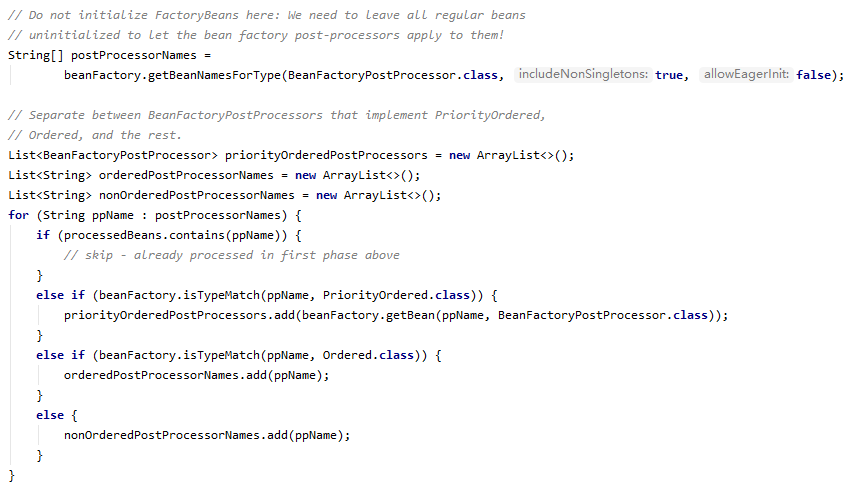
获取 Spring 容器里所有 BFPP 类型的 Bean,然后分成三类,分别是实现了 PriorityOrdered 接口的,实现了 Ordered 接口的,其他(也就是不需要排序的),这里需要注意,因为获取 BFPP 类型的 Bean,会将 BDRPP 类型的也获取到,因为 BDRPP 是 BFPP 的子类嘛,所以之前处理过的 BDRPP 需要跳过,继续看下面

这边就很好理解了,按照 PriorityOrdered > Ordered > 其他,的顺序依次执行 postProcessBeanFactory 方法
3、总结
总结一下执行顺序
- 先执行了
BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法,按照顺序PriorityOrdered>Ordered> 其他; - 再执行了
BeanDefinitionRegistryPostProcessor的postProcessBeanFactory方法; - 最后执行
BeanFactoryPostProcessor的postProcessBeanFactory方法,按照顺序PriorityOrdered>Ordered> 其他;
三、BeanPostProcessor 源码解析
处理 BeanPostProcessor (后面简称 BPP)的源码在哪里呢,我们知道 BPP 是在 Bean 实例化过程中,init 方法执行前后调用的,入口在 Spring 的核心方法 refresh 方法中的 finishBeanFactoryInitialization(beanFactory); 方法里,里面嵌套很多方法,我们直接来到创建 Bean 的核心方法里,也就是 AbstractAutowireCapableBeanFactory 类的 doCreateBean 方法,在这个方法里找到 exposedObject = initializeBean(beanName, exposedObject, mbd); 这句
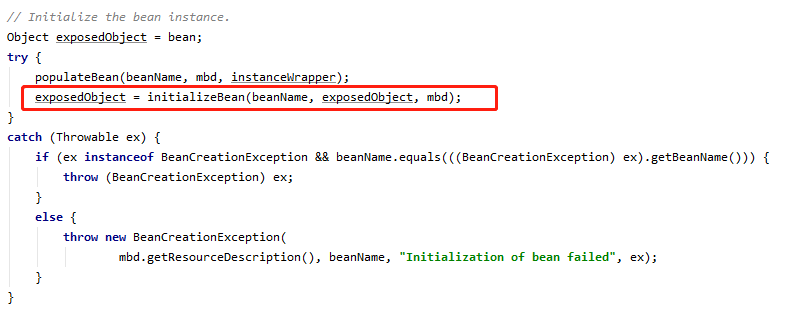
在对 Bean 进行实例化和属性填充之后,就会执行这个方法,进一步完成 Bean 的初始化,我们看看这个方法

可以看到在执行 init 方法前后,分别执行了 applyBeanPostProcessorsBeforeInitialization 和 applyBeanPostProcessorsAfterInitialization 方法,这两个方法里,循环了所有的 BPP,调用了其 postProcessBeforeInitialization 和 postProcessAfterInitialization 方法。