网站组成元素太原seo培训
有时做应急响应的时候,需要提取web日志如access.log日志文件来分析系统遭受攻击的具体原因,由于开源的工具并不是很好用,所以自己用Python3写了一个简单的日志分析工具。
先介绍一下access.log日志
access.log日志文件记录了所有目标对Web服务器的访问请求,当有客户端对网站进行了访问时,access.log就会生成一条访问日志。
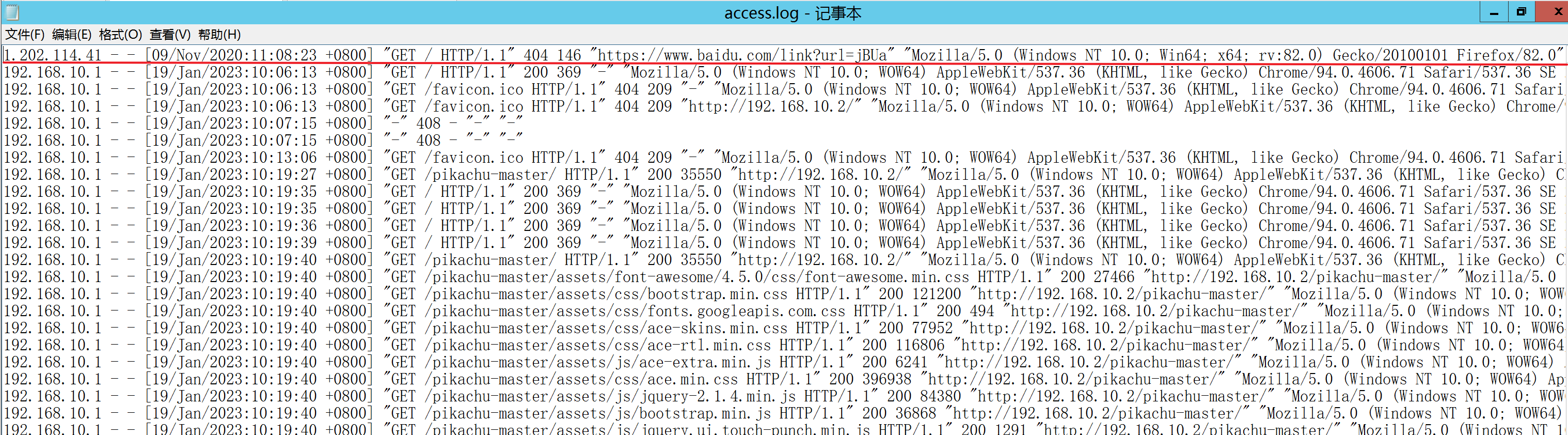
日志格式
一条访问日志一般分为7个字段
1.202.114.41 - - [09/Nov/2020:11:08:23 +0800] "GET / HTTP/1.1" 404 146 "https://www.baidu.com/link?url=jBUa" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
1.202.114.41 代表是谁访问的服务器
[09/Nov/2020:11:08:23 +0800] 表示访问服务器时,服务器的时间。+0800表示服务器所处时区位于UTC之后的8小时。
GET / HTTP/1.1 请求的方法和访问的路径
404 为服务器响应的状态码,此信息非常有价值,它揭示了请求是否成功以及失败。
146 表示服务器发送给客户端的字节数,但这个字节数,不包括响应头的信息,如果服务器没有向客户端发送任何内容,则该值为“-”
https://www.baidu.com/link?url=jBUa 请求来源,用于表示浏览者在访问该页面之前所浏览的页面,只有从上一页面链接过来的请求才会有该项输出,如果是新开的页面则该项为空。上例中来源页面是从baidu转过来,即用户从baidu的那条链接中点击进来。
"Mozilla/5.0 xx" 表示用户终端浏览器的UserAgent
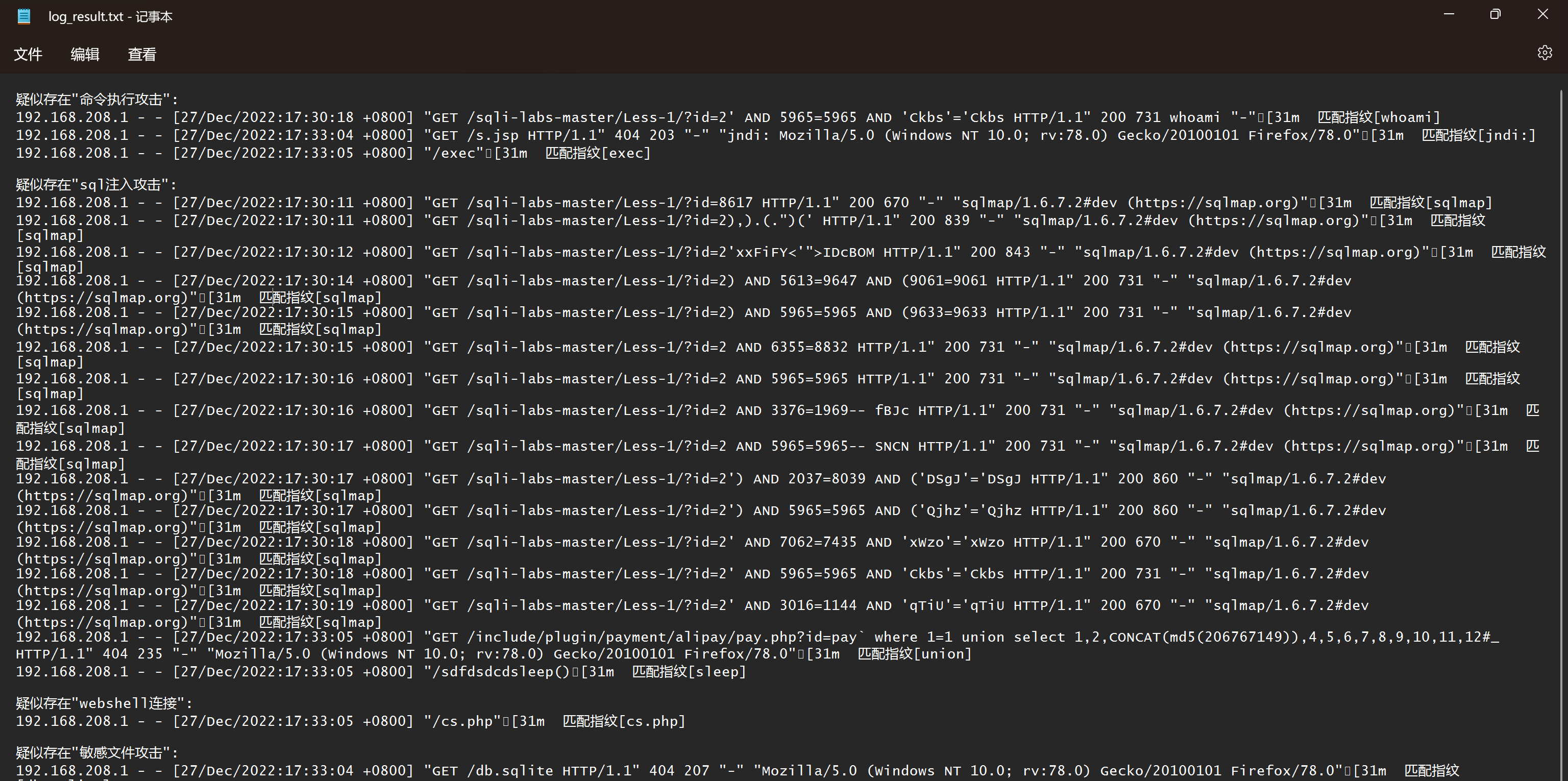
常见web漏洞攻击日志
通过web日志可以判断目标为恶意请求还是正常请求。如下请求路径中携带危险字符
172.16.2.1 - - [09/Feb/2023:17:57:02 0800] "GET /sqli-labs-master/Less-1/?id=1' order by 3 -- HTTP/1.1" 200 721(SQL注入) 172.16.2.1 - - [09/Feb/2023:17:57:18 0800] "GET /sqli-labs-master/Less-1/?id=1' and sleep(5) -- HTTP/1.1" 200 670 (SQL注入) 172.16.2.1 - - [09/Feb/2023:18:01:19 0800] "GET /sqli-labs-master/Less-1/?id=<script>alert(11)</script> HTTP/1.1" 200 670 (xss攻击) ... |
可以使用正则来匹配每条请求是否存在攻击行为,其中的指纹库finger可以根据需求随时进行扩充
log_tool.py
import re, os, argparse
from urllib.parse import unquote
from colorama import init,Fore,Back
init(autoreset=True)finger = {"命令执行攻击":"/dev/tcp|call_user_func|preg_replace|proc_popen|popen|passthru|shell_exec|exec|/bin/bash|call_user_func_array|assert|eval|fputs|fopen|base64_decode|wget|curl.*ifs|uname|think.*invokefunction|whoami|ifconfig|ip add|echo|net user|phpinfo|jndi:|rmi:|\${","sql注入攻击":"sleep|union|concat|information_schema|table_name|extractvalue|updatexml|order by|sqlmap|md5\(","xss攻击":"<script|img src=|imgsrc=|document\.domain|prompt|alert\(|confirm\(|javascript:|Onerror|onclick","webshell连接":"shell\.asp|shell\.jsp|shell\.jspx|shell\.php|cs\.php|tomcatwar\.jsp","敏感文件攻击":"\.ssh/id_dsa|\.\./|\.\.|/etc/passwd|\.bash_profile|db\.sqlite|/win\.ini|wp-config\.php|\.htaccess|\?pwd|heapdump|/\.git"
}data_list = {'命令执行攻击':[],'sql注入攻击':[],'xss攻击':[],'webshell连接':[],'敏感文件攻击':[]
}def get_parser():logo = r"""______ _____________ ____ / ___/ / ___/\_ __ \_/ ___\ \___ \ \___ \ | | \/\ \___ /____ >/____ > |__| \___ >\/ \/ \/ Author: 山山而川Blog : https://chenchena.blog.csdn.net/?type=lately"""parser = argparse.ArgumentParser(usage='python log_tool.py 日志文件')print(logo)print("正在分析日志信息,请稍等..."+"\n")p = parser.add_argument_group('log_tool.py的参数')p.add_argument("logName", type=str, help="为.log日志文件")args = parser.parse_args()return argsdef extract(filename):with open(filename,'r',encoding='utf-8') as file:for line in file: #获取每一条日志信息line = unquote(line[:-1], 'utf-8')for k,v in finger.items(): #遍历每一条指纹信息result = re.search(v,line,re.I)if result:data = line + Fore.RED+" 匹配指纹[%s]"%result.group()if k == "命令执行攻击":rce = data_list.get('命令执行攻击')rce.append(data)breakif k == "sql注入攻击":sql = data_list.get('sql注入攻击')sql.append(data)breakif k == "xss攻击":xss = data_list.get('xss攻击')xss.append(data)breakif k == "webshell连接":webshell = data_list.get('webshell连接')webshell.append(data)breakif k == "敏感文件攻击":file = data_list.get('敏感文件攻击')file.append(data)breakoutfileName = filename.rsplit(".",1)[0] + "_result.txt"if os.path.exists(outfileName):os.remove(outfileName)for attack_name,attack_record in data_list.items():if attack_record:output = '疑似存在"%s":'%attack_nameprint(Fore.YELLOW+output)with open(outfileName,'a',encoding='utf-8') as f:f.write(output+"\n")for recode in attack_record:if "200" in recode:print(recode + Fore.GREEN + " 响应码200")with open(outfileName,'a',encoding='utf-8') as f:f.write(recode + " 响应码200""\n")else:print(recode)with open(outfileName, 'a', encoding='utf-8') as f:f.write(recode + "\n")with open(outfileName, 'a', encoding='utf-8') as f:f.write("\n")print("")
if __name__ == '__main__':filename = get_parser().logNameextract(filename)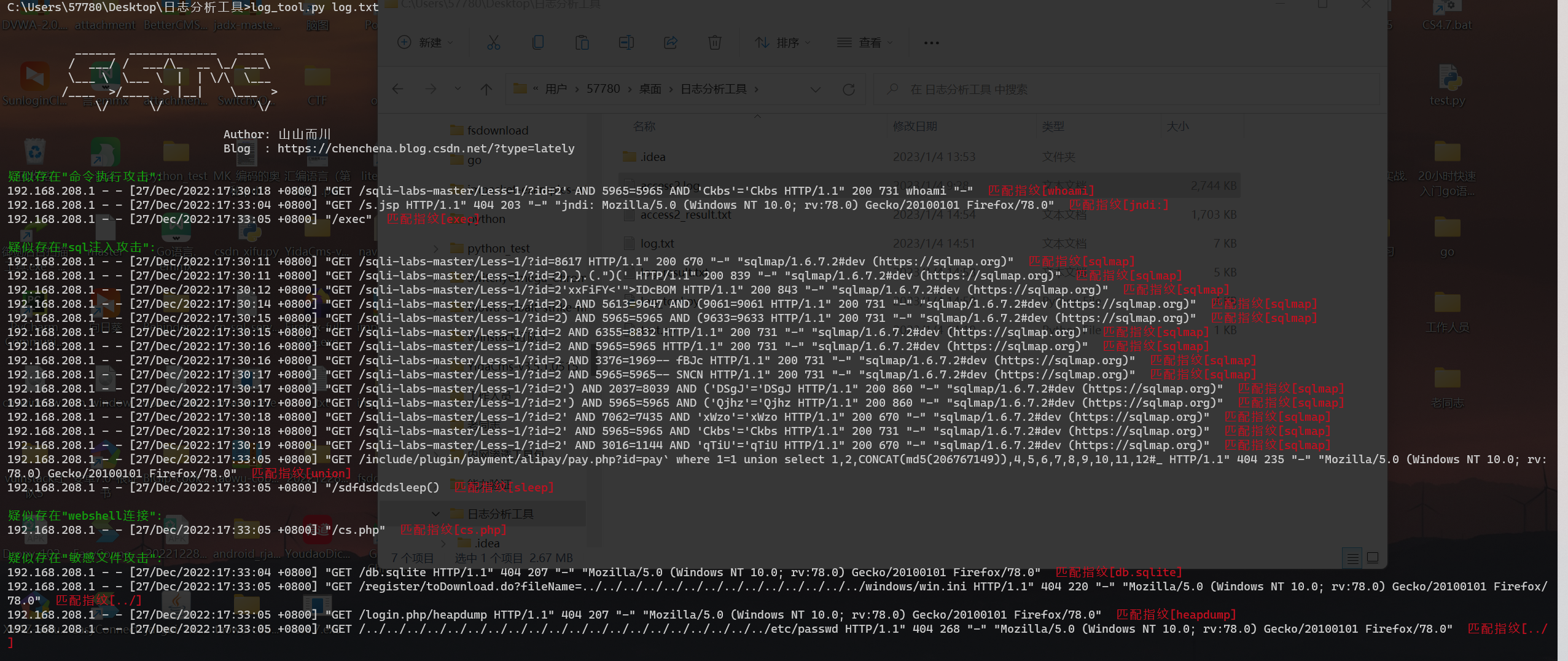
输出的同时会默认保存在本地