查看网站信息图标怎么做app代理推广合作50元
| 实验名称: 基于urllib库的网页数据爬取 |
| 实验目的及要求: 【实验目的】 通过本实验了解和掌握urllib库。 【实验要求】 1. 使用urllib库爬取百度搜索页面。 2. 使用urllib库获取百度搜索的关键字搜索结果(关键字任选)。 实验原理及内容:填写格式:宋体,五号,行距最小值18磅 【实验原理】(列出相关知识点) 1、urllib.request.urlopen: 这个函数用于打开一个URL,返回一个文件对象,然后可以通过该文件对象来获取服务器的响应。在这个过程中,urllib会向目标服务器发送HTTP请求,并接收服务器的响应。 2、请求参数和编码:在构建URL时,可以使用urllib.parse.urlencode来将请求参数编码并拼接到URL中。这是为了将查询参数传递给服务器,以便进行搜索或其他操作。 3、Headers(请求头): 有些网站对请求头进行检查,以确定请求是否来自合法的浏览器。通过在请求中添加合适的Headers,可以模拟浏览器的请求,降低被识别为爬虫的概率。这可以通过在urllib.request.Request对象中添加Headers来实现。 4、URL解析和构建: 解析URL:使用urllib.parse.urlparse函数解析URL,获取其各个部分的信息(协议、主机、路径等)。 构建URL:使用urllib.parse.urljoin函数构建绝对路径的URL。 【程序思路】 程序的思路可以总结为以下几个步骤: 1. 构建URL:根据实验要求,我们首先需要构建URL。如果是爬取百度搜索页面,可以使用百度的首页URL;如果是关键字搜索结果,需要在URL中加入相应的查询参数。 2.发送HTTP请求:使用`urllib.request.urlopen`函数打开URL,获取服务器的响应。 3.读取响应内容:通过响应对象可以获取服务器返回的HTML内容。 4.打印或处理HTML内容:对获取的HTML内容进行处理,可以选择打印出前几个字符,保存到文件中,或者进行进一步的解析。 5.查询参数处理(如果是关键字搜索):如果是关键字搜索,需要构建带有查询参数的URL。 6.发送带查询参数的HTTP请求:通过`urllib.request.urlopen`发送带有查询参数的HTTP请求。 7.读取关键字搜索结果的HTML内容:与之前相同,通过响应对象获取服务器返回的HTML内容。 8.打印或处理关键字搜索结果的HTML内容:对获取的HTML内容进行处理,可以选择打印出前几个字符,保存到文件中,或者进行进一步的解析。 实验数据与结果分析:(含运行结果截屏) 【实验结果】
【结果分析】 通过进行这两个实验,在第一个实验中成功将百度搜索页面爬取下来,但在第二个实验中,触发了百度的安全验证,导致搜索关键词停止,无法爬取后面的内容,在尝试添加一些头信息或使用代理等手段后,仍被阻止,故无法读取后续结果。 实验小结:(包括问题和解决方法、心得体会、意见与建议等) 一、问题与解决方法: 安全验证问题:在爬取百度搜索页面时,可能遇到安全验证问题,导致无法直接获取页面内容。解决方法可能包括添加请求头信息,使用代理服务器,或者采用其他绕过安全验证的策略。 异常处理:在实际运行中,可能会遇到各种异常,如网络连接问题、超时等。建议使用适当的异常处理机制来增强代码的稳定性。 二、心得体会: 通过本次实验,我了解了使用`urllib`库进行网页爬取的基本流程,包括构建URL、发送HTTP请求、处理响应等步骤。同时也了解了实验中可能遇到网站的反爬虫机制,需要适应性地调整代码,添加头信息、使用代理等手段来规避这些机制。 三、意见与建议: 我应该去学习更多爬虫技术,可以进一步学习相关的爬虫技术,包括使用更高级的库(如Scrapy、BeautifulSoup、Selenium)和处理动态网页爬取等。同时在实际应用中,我们也要注意遵循网站的使用规范,不要滥用爬虫,以免造成对方服务器的过大负担,甚至被封禁IP。 四、总结: 通过这个实验,初步了解了`urllib`库的使用和基本的网页爬取原理。在实际应用中,需要不断学习、调整和优化代码,以应对各种可能遇到的情况。 实验源代码清单:(带注释) |

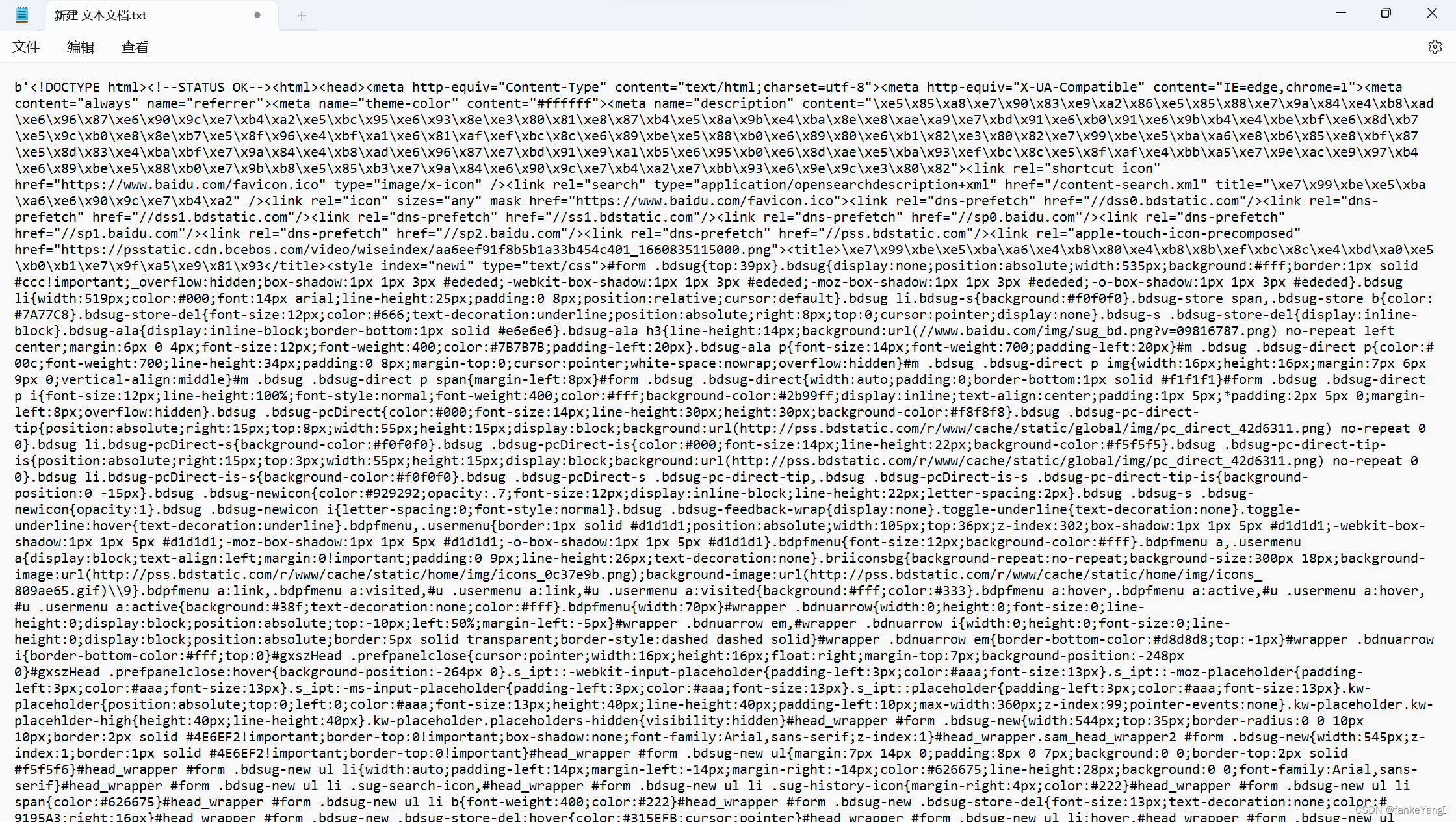
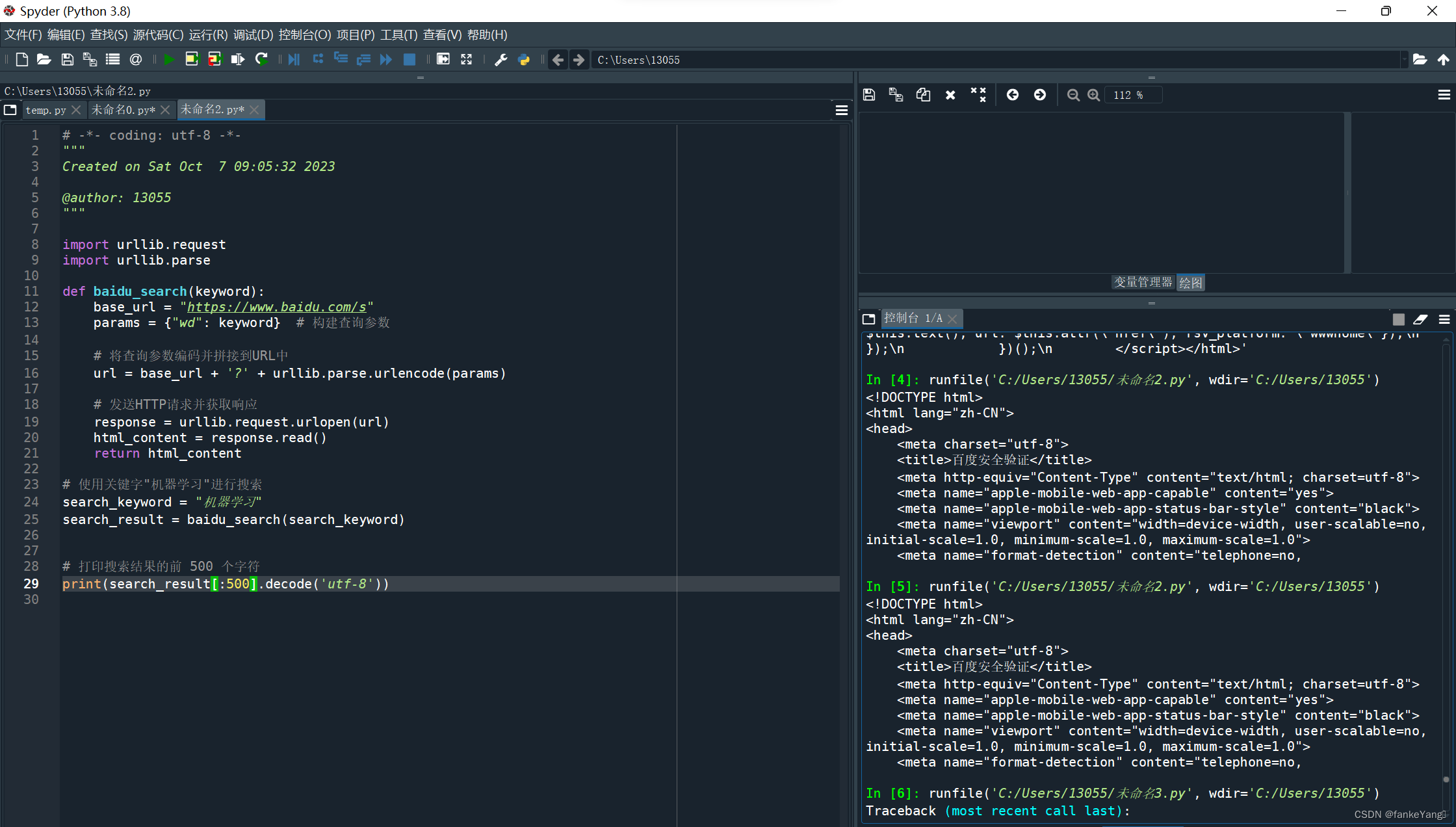
import urllib.request #导入urllib库response = urllib.request.urlopen('http://www.baidu.com')html=response.read()#读取网页print(html)#输出网页import urllib.requestimport urllib.parsedef baidu_search(keyword):base_url = "https://www.baidu.com/s"params = {"wd": keyword} # 构建查询参数# 将查询参数编码并拼接到URL中url = base_url + '?' + urllib.parse.urlencode(params)# 发送HTTP请求并获取响应response = urllib.request.urlopen(url)html_content = response.read()return html_content# 使用关键字"机器学习"进行搜索search_keyword = "机器学习"search_result = baidu_search(search_keyword)# 打印搜索结果的前 500 个字符print(search_result[:500].decode('utf-8'))